

VI. Comprendre EXPLAIN▲
|
|

VI-A. Introduction▲
- Le matériel, le système et la configuration sont importants pour les performances.
- Mais il est aussi essentiel de se préoccuper des requêtes et de leurs performances.
Face à un problème de performances, l’administrateur se retrouve assez rapidement face à une (ou plusieurs) requête(s). Une requête en soi représente très peu d’informations. Suivant la requête, des dizaines de plans peuvent être sélectionnés pour l’exécuter. Il est donc nécessaire de pouvoir trouver le plan d’exécution et de comprendre ce plan. Cela permet de mieux appréhender la requête et de mieux comprendre les pistes envisageables pour la corriger.
VI-A-1. Au menu▲
- Exécution globale d’une requête.
- Planificateur : utilité, statistiques et configuration.
- EXPLAIN.
- Nœuds d’un plan.
- Outils.
Avant de détailler le fonctionnement du planificateur, nous allons regarder la façon dont une requête s’exécute globalement. Ensuite, nous aborderons le planificateur : en quoi est-il utile, comment fonctionne-t-il, et comment le configurer ? Nous ferons un tour sur le fonctionnement de la commande EXPLAIN et les informations qu’elle fournit. Nous verrons aussi l’ensemble des opérations utilisables par le planificateur. Enfin, nous listerons les outils essentiels pour faciliter la compréhension d’un plan de requête.
VI-A-2. Jeu de tests▲
-
Tables :
- services, contenant 4 lignes,
- services_big, contenant environ 40k lignes,
- employes, contenant 14 lignes,
- employes_big, contenant environ 500k lignes.
-
Index :
- sur la colonne num_service, via la clé primaire des tables services et services_big,
- sur la colonne matricule, via la clé primaire des tables employes et employes_big,
- sur la colonne date_embauche pour employes,
- sur la colonne num_service pour employes_big.
Le script suivant permet de recréer le jeu d’essai :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
86.
87.
88.
89.
90.
91.
92.
93.
94.
95.
-- suppression des tables si elles existent
DROP TABLE IF EXISTS services CASCADE;
DROP TABLE IF EXISTS services_big CASCADE;
DROP TABLE IF EXISTS employes CASCADE;
DROP TABLE IF EXISTS employes_big CASCADE;
-- définition des tables
CREATE TABLE services (
num_service serial PRIMARY KEY,
nom_service character varying(20),
localisation character varying(20),
departement integer,
date_creation date
);
CREATE TABLE services_big (
num_service serial PRIMARY KEY,
nom_service character varying(20),
localisation character varying(20),
departement integer,
date_creation date
);
CREATE TABLE employes (
matricule serial primary key,
nom varchar(15) not null,
prenom varchar(15) not null,
fonction varchar(20) not null,
manager integer,
date_embauche date,
num_service integer not null references services (num_service)
);
CREATE TABLE employes_big (
matricule serial primary key,
nom varchar(15) not null,
prenom varchar(15) not null,
fonction varchar(20) not null,
manager integer,
date_embauche date,
num_service integer not null references services (num_service)
);
-- ajout des données
INSERT INTO services
VALUES
(1, 'Comptabilité', 'Paris', 75, '2006-09-03'),
(2, 'R&D', 'Rennes', 40, '2009-08-03'),
(3, 'Commerciaux', 'Limoges', 52, '2006-09-03'),
(4, 'Consultants', 'Nantes', 44, '2009-08-03');
INSERT INTO services_big (nom_service, localisation, departement, date_creation)
VALUES
('Comptabilité', 'Paris', 75, '2006-09-03'),
('R&D', 'Rennes', 40, '2009-08-03'),
('Commerciaux', 'Limoges', 52, '2006-09-03'),
('Consultants', 'Nantes', 44, '2009-08-03');
INSERT INTO services_big (nom_service, localisation, departement, date_creation)
SELECT s.nom_service, s.localisation, s.departement, s.date_creation
FROM services s, generate_series(1, 10000);
INSERT INTO employes VALUES
(33, 'Roy', 'Arthur', 'Consultant', 105, '2000-06-01', 4),
(81, 'Prunelle', 'Léon', 'Commercial', 97, '2000-06-01', 3),
(97, 'Lebowski', 'Dude', 'Responsable', 104, '2003-01-01', 3),
(104, 'Cruchot', 'Ludovic', 'Directeur Général', NULL, '2005-03-06', 3),
(105, 'Vacuum', 'Anne-Lise', 'Responsable', 104, '2005-03-06', 4),
(119, 'Thierrie', 'Armand', 'Consultant', 105, '2006-01-01', 4),
(120, 'Tricard', 'Gaston', 'Développeur', 125, '2006-01-01', 2),
(125, 'Berlicot', 'Jules', 'Responsable', 104, '2006-03-01', 2),
(126, 'Fougasse', 'Lucien', 'Comptable', 128, '2006-03-01', 1),
(128, 'Cruchot', 'Josépha', 'Responsable', 105, '2006-03-01', 1),
(131, 'Lareine-Leroy', 'Émilie', 'Développeur', 125, '2006-06-01', 2),
(135, 'Brisebard', 'Sylvie', 'Commercial', 97, '2006-09-01', 3),
(136, 'Barnier', 'Germaine', 'Consultant', 105, '2006-09-01', 4),
(137, 'Pivert', 'Victor', 'Consultant', 105, '2006-09-01', 4);
INSERT INTO employes_big SELECT * FROM employes;
INSERT INTO employes_big
SELECT i, nom,prenom,fonction,manager,date_embauche,num_service
FROM employes_big,
LATERAL generate_series(1000, 500000) i
WHERE matricule=137;
-- création des index
CREATE INDEX ON employes(date_embauche);
CREATE INDEX ON employes_big(date_embauche);
CREATE INDEX ON employes_big(num_service);
-- calcul des statistiques sur les nouvelles données
VACUUM ANALYZE;
VI-B. Exécution globale d’une requête▲
-
L’exécution peut se voir sur deux niveaux :
- niveau système,
- niveau SGBD.
- De toute façon, composée de plusieurs étapes.
L’exécution d’une requête peut se voir sur deux niveaux :
- ce que le système perçoit ;
- ce que le SGBD fait.
Dans les deux cas, cela va nous permettre de trouver les possibilités de lenteurs dans l’exécution d’une requête par un utilisateur.
VI-B-1. Niveau système▲
- Le client envoie une requête au serveur de bases de données.
- Le serveur l’exécute.
- Puis il renvoie le résultat au client.
PostgreSQL est un système client-serveur. L’utilisateur se connecte via un outil (le client) à une base d’une instance PostgreSQL (le serveur). L’outil peut envoyer une requête au serveur, celui-ci l’exécute et finit par renvoyer les données résultant de la requête ou le statut de la requête.
Généralement, l’envoi de la requête est rapide. Par contre, la récupération des données peut poser problème si une grosse volumétrie est demandée sur un réseau à faible débit. L’affichage peut aussi être un problème (afficher une ligne sera plus rapide qu’afficher un million de lignes, afficher un entier est plus rapide qu’afficher un document texte de 1 Mo, etc.).
VI-B-2. Niveau SGBD▲
|
|
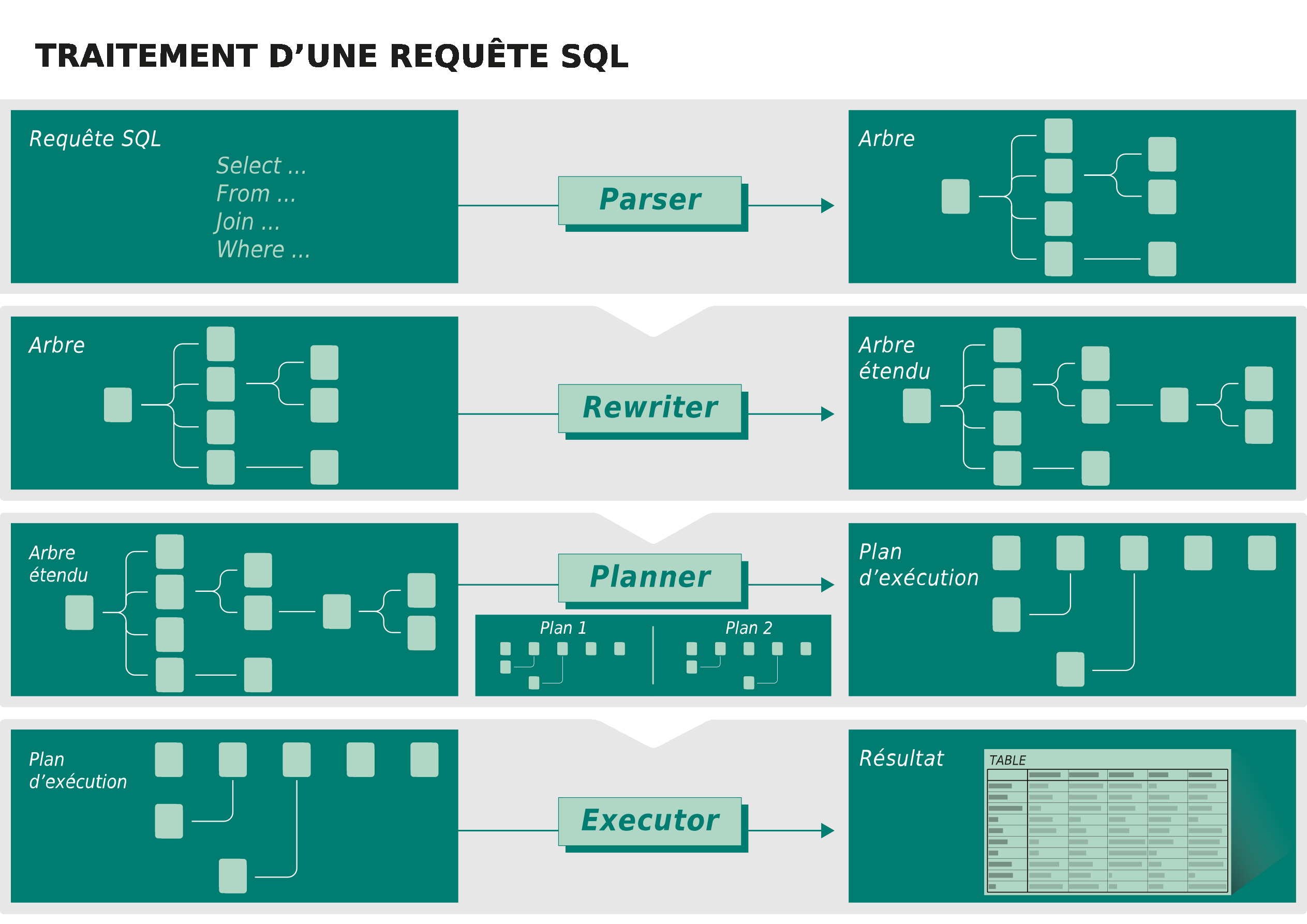
Lorsque le serveur récupère la requête, un ensemble de traitements est réalisé :
- le parser va réaliser une analyse syntaxique de la requête ;
- le rewriter va réécrire, si nécessaire la requête ;
- pour cela, il prend en compte les règles, les vues non matérialisées et les fonctions SQL ;
- si une règle demande de changer la requête, la requête envoyée est remplacée par la nouvelle ;
- si une vue non matérialisée est utilisée, la requête qu’elle contient est intégrée dans la requête envoyée ;
- si une fonction SQL intégrable est utilisée, la requête qu’elle contient est intégrée dans la requête envoyée ;
- le planner va générer l’ensemble des plans d’exécutions ;
- il calcule le coût de chaque plan ;
- puis il choisit le plan le moins coûteux, donc le plus intéressant ;
- l’ executer exécute la requête ;
- pour cela, il doit commencer par récupérer les verrous nécessaires sur les objets ciblés ;
- une fois les verrous récupérés, il exécute la requête ;
- une fois la requête exécutée, il envoie les résultats à l’utilisateur.
Plusieurs goulets d’étranglement sont visibles ici. Les plus importants sont :
- la planification (à tel point qu’il est parfois préférable de ne générer qu’un sous-ensemble de plans, pour passer plus rapidement à la phase d’exécution) ;
- la récupération des verrous (une requête peut attendre plusieurs secondes, minutes, voire heures, avant de récupérer les verrous et exécuter réellement la requête) ;
- l’exécution de la requête ;
- l’envoi des résultats à l’utilisateur.
Il est possible de tracer l’exécution des différentes étapes grâce aux options log_parser_stats, log_planner_stats et log_executor_stats. Voici un exemple complet :
- Mise en place de la configuration sur la session :
2.
3.
4.
SET log_parser_stats TO on;
SET log_planner_stats TO on;
SET log_executor_stats TO on;
SET client_min_messages TO log;
- Exécution de la requête :
SELECTfonction,count(*)FROMemployes_bigORDERBYfonction;- Trace du parser
LOG: PARSER STATISTICS
DETAIL: ! system usage stats:
! 0.000015 s user, 0.000000 s system, 0.000015 s elapsed
! [5.191712 s user, 0.241927 s system total]
! 0/0 [0/470824] filesystem blocks in/out
! 0/0 [0/34363] page faults/reclaims, 0 [0] swaps
! 0 [0] signals rcvd, 0/0 [0/0] messages rcvd/sent
! 0/0 [1143/170] voluntary/involuntary context switches
LOG: PARSE ANALYSIS STATISTICS
DETAIL: ! system usage stats:
! 0.000183 s user, 0.000000 s system, 0.000189 s elapsed
! [5.191915 s user, 0.241928 s system total]
! 0/0 [0/470824] filesystem blocks in/out
! 0/12 [0/34375] page faults/reclaims, 0 [0] swaps
! 0 [0] signals rcvd, 0/0 [0/0] messages rcvd/sent
! 0/0 [1143/170] voluntary/involuntary context switches- Trace du rewriter
LOG: REWRITER STATISTICS
DETAIL: ! system usage stats:
! 0.000004 s user, 0.000000 s system, 0.000004 s elapsed
! [5.191940 s user, 0.241928 s system total]
! 0/0 [0/470824] filesystem blocks in/out
! 0/0 [0/34375] page faults/reclaims, 0 [0] swaps
! 0 [0] signals rcvd, 0/0 [0/0] messages rcvd/sent
! 0/0 [1143/170] voluntary/involuntary context switches- Trace du planner
LOG: PLANNER STATISTICS
DETAIL: ! system usage stats:
! 0.000159 s user, 0.000000 s system, 0.000159 s elapsed
! [5.192119 s user, 0.241928 s system total]
! 0/0 [0/470824] filesystem blocks in/out
! 0/8 [0/34383] page faults/reclaims, 0 [0] swaps
! 0 [0] signals rcvd, 0/0 [0/0] messages rcvd/sent
! 0/0 [1143/170] voluntary/involuntary context switches- Trace de l’ executer
LOG: EXECUTOR STATISTICS
DETAIL: ! system usage stats:
! 0.078269 s user, 0.000000 s system, 0.093096 s elapsed
! [5.270446 s user, 0.241928 s system total]
! 0/0 [0/470824] filesystem blocks in/out
! 0/9 [0/34392] page faults/reclaims, 0 [0] swaps
! 0 [0] signals rcvd, 0/0 [0/0] messages rcvd/sent
! 2/68 [1145/240] voluntary/involuntary context switchesVI-B-3. Exceptions▲
- Requêtes DDL.
- Instructions TRUNCATE et COPY.
-
Pas de réécriture, pas de plans d’exécution… :
- une exécution directe.
Il existe quelques requêtes qui échappent à la séquence d’opérations présentées précédemment. Toutes les opérations DDL (modification de la structure de la base), les instructions TRUNCATE et COPY (en partie) sont vérifiées syntaxiquement, puis directement exécutées. Les étapes de réécriture et de planification ne sont pas réalisées.
Le principal souci pour les performances sur ce type d’instructions est donc l’obtention des verrous et l’exécution réelle.
VI-C. Quelques définitions▲
-
Prédicat :
- filtre de la clause WHERE.
-
Sélectivité :
- pourcentage de lignes retournées après application d’un prédicat.
-
Cardinalité :
- nombre de lignes d’une table,
- nombre de lignes retournées après filtrage.
Un prédicat est une condition de filtrage présente dans la clause WHERE d’une requête. Par exemple colonne = valeur.
La sélectivité est liée à l’application d’un prédicat sur une table. Elle détermine le nombre de lignes remontées par la lecture d’une relation suite à l’application d’une clause de filtrage, ou prédicat. Elle peut être vue comme un coefficient de filtrage d’un prédicat. La sélectivité est exprimée sous la forme d’un pourcentage. Pour une table de 1000 lignes, si la sélectivité d’un prédicat est de 10 %, la lecture de la table en appliquant le prédicat devrait retourner 10 % des lignes, soit 100 lignes.
La cardinalité représente le nombre de lignes d’une relation. En d’autres termes, la cardinalité représente le nombre de lignes d’une table ou du résultat d’une fonction. Elle représente aussi le nombre de lignes retournées par la lecture d’une table après application d’un ou plusieurs prédicats.
VI-C-1. Requête étudiée▲
2.
3.
4.
SELECT matricule, nom, prenom, nom_service, fonction, localisation
FROM employes emp
JOIN services ser ON (emp.num_service = ser.num_service)
WHERE ser.localisation = 'Nantes';
Cette requête permet de déterminer les employés basés à Nantes.
VI-C-2. Plan de la requête étudiée▲
L’objet de ce module est de comprendre son plan d’exécution :
2.
3.
4.
5.
Nested Loop (cost=0.00..2.37 rows=4 width=48)
Join Filter: (emp.num_service = ser.num_service)
-> Seq Scan on services ser (cost=0.00..1.05 rows=1 width=21)
Filter: ((localisation)::text = 'Nantes'::text)
-> Seq Scan on employes emp (cost=0.00..1.14 rows=14 width=35)
La directive EXPLAIN permet de connaître le plan d’exécution d’une requête. Elle permet de savoir par quelles étapes va passer le SGBD pour répondre à la requête.
Ce plan montre une jointure par Nested Loop. Pour faciliter la compréhension, un autre plan utilisant une jointure par hachage sera utilisé et étudié ultérieurement.
VI-D. Planificateur▲
- Chargé de sélectionner le meilleur plan d’exécution.
-
Énumère tous les plans d’exécution :
- tous ou presque…
- Calcule leur coût suivant des statistiques, un peu de configuration et beaucoup de règles.
- Sélectionne le meilleur (le moins coûteux).
Le but du planificateur est assez simple. Pour une requête, il existe de nombreux plans d’exécution possibles. Il va donc énumérer tous les plans d’exécution possibles (sauf si cela représente vraiment trop de plans, auquel cas il ne prendra en compte qu’une partie des plans possibles). Lors de cette énumération des différents plans, il calcule leur coût. Cela lui permet d’en ignorer certains alors qu’ils sont incomplets si leur plan d’exécution est déjà plus coûteux que les autres. Pour calculer le coût, il dispose d’informations sur les données (des statistiques), d’une configuration (réalisée par l’administrateur de bases de données) et d’un ensemble de règles inscrites en dur. À la fin de l’énumération et du calcul de coût, il ne lui reste plus qu’à sélectionner le plan qui a le plus petit coût.
VI-D-1. Utilité▲
- SQL est un langage déclaratif.
-
Une requête décrit le résultat à obtenir :
- mais pas la façon de l’obtenir.
- C’est au planificateur de déduire le moyen de parvenir au résultat demandé.
Le planificateur est un composant essentiel d’un moteur de bases de données. Les moteurs utilisent un langage SQL qui permet à l’utilisateur de décrire le résultat qu’il souhaite obtenir. Par exemple, s’il veut récupérer des informations sur tous les clients dont le nom commence par la lettre A en triant les clients par leur département, il pourrait utiliser une requête du type :
SELECT * FROM employes WHERE nom LIKE 'A%' ORDER BY num_service;
Un moteur de bases de données peut récupérer les données de plusieurs façons :
- faire un parcours séquentiel de la table employes en filtrant les enregistrements d’après leur nom, puis trier les données grâce à un algorithme ;
- faire un parcours d’index sur la colonne nom pour trouver plus rapidement les enregistrements de la table clients satisfaisant le filtre 'A%', puis trier les données grâce à un algorithme ;
- faire un parcours d’index sur la colonne num_service pour récupérer les enregistrements déjà triés, et ne retourner que ceux vérifiant le prédicat nom like 'A%'.
Et ce ne sont que quelques exemples, car il serait possible d’avoir un index utilisable pour le tri et le filtre par exemple.
Donc la requête décrit le résultat à obtenir, et le planificateur va chercher le meilleur moyen pour parvenir à ce résultat.
Pour ce travail, il dispose d’un certain nombre d’opérations de base. Ces opérations travaillent sur des ensembles de lignes, généralement un ou deux. Chaque opération renvoie un seul ensemble de lignes. Le planificateur peut combiner ces opérations suivant certaines règles. Une opération peut renvoyer l’ensemble de résultats de deux façons : d’un coup (par exemple le tri) ou petit à petit (par exemple un parcours séquentiel). Le premier cas utilise plus de mémoire, et peut nécessiter d’écrire des données temporaires sur disque. Le deuxième cas aide à accélérer des opérations comme les curseurs, les sous-requêtes IN et EXISTS, la clause LIMIT, etc.
VI-D-2. Règles▲
- 1re règle : Récupérer le bon résultat.
-
2e règle : Le plus rapidement possible :
- en minimisant les opérations disques,
- en préférant les lectures séquentielles,
- en minimisant la charge CPU,
- en minimisant l’utilisation de la mémoire.
Le planificateur suit deux règles :
- il doit récupérer le bon résultat ;
- il doit le récupérer le plus rapidement possible.
Cette deuxième règle lui impose de minimiser l’utilisation des ressources : en tout premier lieu les opérations disques vu qu’elles sont les plus coûteuses, mais aussi la charge CPU (charge des CPU utilisés et nombre de CPU utilisés) et l’utilisation de la mémoire. Dans le cas des opérations disques, s’il doit en faire, il doit absolument privilégier les opérations séquentielles aux opérations aléatoires (qui demandent un déplacement de la tête de disque, ce qui est l’opération la plus coûteuse sur les disques magnétiques).
VI-D-3. Outils de l’optimiseur▲
-
L’optimiseur s’appuie sur :
- un mécanisme de calcul de coûts,
- des statistiques sur les données,
- le schéma de la base de données.
Pour déterminer le chemin d’exécution le moins coûteux, l’optimiseur devrait connaître précisément les données mises en œuvre dans la requête, les particularités du matériel et la charge en cours sur ce matériel. Cela est impossible. Ce problème est contourné en utilisant deux mécanismes liés l’un à l’autre :
- un mécanisme de calcul de coût de chaque opération ;
- des statistiques sur les données.
Pour quantifier la charge nécessaire pour répondre à une requête, PostgreSQL utilise un mécanisme de coût. Il part du principe que chaque opération a un coût plus ou moins important. Les statistiques sur les données permettent à l’optimiseur de requêtes de déterminer assez précisément la répartition des valeurs d’une colonne d’une table, sous la forme d’histogramme. Il dispose encore d’autres informations comme la répartition des valeurs les plus fréquentes, le pourcentage de NULL, le nombre de valeurs distinctes, etc. Toutes ces informations aideront l’optimiseur à déterminer la sélectivité d’un filtre (prédicat de la clause WHERE, condition de jointure) et donc la quantité de données récupérées par la lecture d’une table en utilisant le filtre évalué. Enfin, l’optimiseur s’appuie sur le schéma de la base de données afin de déterminer différents paramètres qui entrent dans le calcul du plan d’exécution : contrainte d’unicité sur une colonne, présence d’une contrainte NOT NULL, etc.
VI-D-4. Optimisations▲
-
À partir du modèle de données :
- suppression de jointures externes inutiles.
-
Transformation des sous-requêtes :
- certaines sous-requêtes transformées en jointures.
-
Appliquer les prédicats le plus tôt possible :
- réduit le jeu de données manipulé.
-
Intègre le code des fonctions SQL simples (inline) :
- évite un appel de fonction coûteux.
Suppression des jointures externes inutiles
À partir du modèle de données et de la requête soumise, l’optimiseur de PostgreSQL va pouvoir déterminer si une jointure externe n’est pas utile à la production du résultat.
Sous certaines conditions, PostgreSQL peut supprimer des jointures externes, à condition que le résultat ne soit pas modifié :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
EXPLAIN
SELECT e.matricule, e.nom, e.prenom
FROM employes e
LEFT JOIN services s
ON (e.num_service = s.num_service)
WHERE e.num_service = 4;
QUERY PLAN
-----------------------------------------------------------
Seq Scan on employes e (cost=0.00..1.18 rows=5 width=19)
Filter: (num_service = 4)
(2 rows)
Toutefois, si le prédicat de la requête est modifié pour s’appliquer sur la table services, la jointure est tout de même réalisée, puisqu’on réalise un test d’existence sur cette table services :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
EXPLAIN
SELECT e.matricule, e.nom, e.prenom
FROM employes e
LEFT JOIN services s
ON (e.num_service = s.num_service)
WHERE s.num_service = 4;
QUERY PLAN
-----------------------------------------------------------------
Nested Loop (cost=0.00..2.27 rows=5 width=19)
-> Seq Scan on services s (cost=0.00..1.05 rows=1 width=4)
Filter: (num_service = 4)
-> Seq Scan on employes e (cost=0.00..1.18 rows=5 width=23)
Filter: (num_service = 4)
(5 rows)
Transformation des sous-requêtes
Certaines sous-requêtes sont transformées en jointure :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
EXPLAIN
SELECT *
FROM employes emp
JOIN (SELECT * FROM services WHERE num_service = 1) ser
ON (emp.num_service = ser.num_service);
QUERY PLAN
-------------------------------------------------------------------
Nested Loop (cost=0.00..2.25 rows=2 width=64)
-> Seq Scan on services (cost=0.00..1.05 rows=1 width=21)
Filter: (num_service = 1)
-> Seq Scan on employes emp (cost=0.00..1.18 rows=2 width=43)
Filter: (num_service = 1)
(5 rows)
La sous-requête ser a été remontée dans l’arbre de requête pour être intégré en jointure.
Application des prédicats au plus tôt
Lorsque cela est possible, PostgreSQL essaye d’appliquer les prédicats au plus tôt :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
EXPLAIN
SELECT MAX(date_embauche)
FROM (SELECT * FROM employes WHERE num_service = 4) e
WHERE e.date_embauche < '2006-01-01';
QUERY PLAN
------------------------------------------------------------------------------
Aggregate (cost=1.21..1.22 rows=1 width=4)
-> Seq Scan on employes (cost=0.00..1.21 rows=2 width=4)
Filter: ((date_embauche < '2006-01-01'::date) AND (num_service = 4))
(3 rows)
Les deux prédicats num_service = 4 et date_embauche < '2006-01-01' ont été appliqués en même temps, réduisant ainsi le jeu de données à considérer dès le départ.
En cas de problème, il est possible d’utiliser une CTE (clause WITH) pour bloquer cette optimisation :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
EXPLAIN
WITH e AS (SELECT * FROM employes WHERE num_service = 4)
SELECT MAX(date_embauche)
FROM e
WHERE e.date_embauche < '2006-01-01';
QUERY PLAN
-----------------------------------------------------------------
Aggregate (cost=1.29..1.30 rows=1 width=4)
CTE e
-> Seq Scan on employes (cost=0.00..1.18 rows=5 width=43)
Filter: (num_service = 4)
-> CTE Scan on e (cost=0.00..0.11 rows=2 width=4)
Filter: (date_embauche < '2006-01-01'::date)
(6 rows)
Function inlining
Voici deux fonctions, la première écrite en SQL, la seconde en PL/pgsql :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
CREATE OR REPLACE FUNCTION add_months_sql(mydate date, nbrmonth integer)
RETURNS date AS
$BODY$
SELECT ( mydate + interval '1 month' * nbrmonth )::date;
$BODY$
LANGUAGE SQL;
CREATE OR REPLACE FUNCTION add_months_plpgsql(mydate date, nbrmonth integer)
RETURNS date AS
$BODY$
BEGIN RETURN ( mydate + interval '1 month' * nbrmonth ); END;
$BODY$
LANGUAGE plpgsql;
Si l’on utilise la fonction écrite en PL/pgsql, on retrouve l’appel de la fonction dans la clause Filter du plan d’exécution de la requête :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
EXPLAIN (ANALYZE, BUFFERS, COSTS off)
SELECT *
FROM employes
WHERE date_embauche = add_months_plpgsql(now()::date, -1);
QUERY PLAN
------------------------------------------------------------------------------
Seq Scan on employes (actual time=0.098..0.098 rows=0 loops=1)
Filter: (date_embauche = add_months_plpgsql((now())::date, '-1'::integer))
Rows Removed by Filter: 14
Buffers: shared hit=1
Planning time: 0.052 ms
Execution time: 0.133 ms
(6 rows)
PostgreSQL ne sait pas intégrer le code des fonctions PL/pgsql dans ses plans d’exécution.
En revanche, en utilisant la fonction écrite en langage SQL, la définition de la fonction a été intégrée dans la clause de filtrage de la requête :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
EXPLAIN (ANALYZE, BUFFERS, COSTS off)
SELECT *
FROM employes
WHERE date_embauche = add_months_sql(now()::date, -1);
QUERY PLAN
---------------------------------------------------------------------------
Seq Scan on employes (actual time=0.009..0.009 rows=0 loops=1)
Filter: (date_embauche = (((now())::date + '-1 mons'::interval))::date)
Rows Removed by Filter: 14
Buffers: shared hit=1
Planning time: 0.088 ms
Execution time: 0.018 ms
(6 rows)
Le code de la fonction SQL a été correctement intégré dans le plan d’exécution. Le temps d’exécution a été divisé par deux sur ce jeu de données très réduit, montrant l’impact de l’appel d’une fonction dans une clause de filtrage. Le changement serait encore plus flagrant avec un index sur la colonne date_embauche, étant donné que l’utilisation de la fonction PL/pgsql empêcherait son utilisation, contrairement à celle écrite en SQL :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
EXPLAIN (ANALYZE, BUFFERS, COSTS off)
SELECT *
FROM employes_big
WHERE date_embauche = add_months_plpgsql(now()::date, -1);
QUERY PLAN
------------------------------------------------------------------------------
Seq Scan on employes_big (actual time=576.848..576.848 rows=0 loops=1)
Filter: (date_embauche = add_months_plpgsql((now())::date, '-1'::integer))
Rows Removed by Filter: 499015
Buffers: shared hit=4664
Planning time: 0.073 ms
Execution time: 576.860 ms
(6 rows)
EXPLAIN (ANALYZE, BUFFERS, COSTS off)
SELECT *
FROM employes_big
WHERE date_embauche = add_months_sql(now()::date, -1);
QUERY PLAN
-------------------------------------------------------------------------------
Index Scan using employes_big_date_embauche_idx on employes_big
(actual time=0.036..0.036 rows=0 loops=1)
Index Cond: (date_embauche = (((now())::date + '-1 mons'::interval))::date)
Buffers: shared read=3
Planning time: 0.093 ms
Execution time: 0.048 ms
(5 rows)
Cette fois, l’exécution est beaucoup plus rapide !
VI-D-5. Décisions▲
-
Stratégie d’accès aux lignes :
- par parcours d’une table, d’un index, de TID, etc.
-
Stratégie d’utilisation des jointures :
- ordre des jointures,
- type de jointure (Nested Loop, Merge/Sort Join, Hash Join),
- ordre des tables jointes dans une même jointure.
-
Stratégie d’agrégation :
- brut, trié, haché.
Pour exécuter une requête, le planificateur va utiliser des opérations. Pour lire des lignes, il peut utiliser un parcours de table, un parcours d’index ou encore d’autres types de parcours. Ce sont généralement les premières opérations utilisées. Ensuite, d’autres opérations permettent différentes actions :
- joindre deux ensembles de lignes avec des opérations de jointure (trois au total) ;
- agréger un ensemble de lignes avec une opération d’agrégation (trois là aussi) ;
- trier un ensemble de lignes ;
- etc.
VI-D-6. Parallélisation▲
-
Disponible depuis la version 9.6 :
- parcours séquentiel,
- jointures Nested Loop et Hash Join,
- agrégats.
-
Améliorée en version 10 :
- parcours d’index (Btree uniquement),
- jointures Merge Join.
-
Des limitations :
- pas sur les écritures,
- pas en cas de verrous,
- pas sur les opérations DDL,
- pas sur les curseurs.
La parallélisation de l’exécution d’une requête est disponible depuis la version 9.6 de PostgreSQL. Elle est désactivée par défaut sur cette version, mais l’implémentation permet de paralléliser les parcours de table (SeqScan), les jointures (Nested Loop et Hash Join), ainsi que certaines fonctions d’agrégat (comme min, max, avg, sum, etc.).
La version 10 améliore cette implémentation en proposant de paralléliser les parcours d’index (Index Scan, Index Only Scan et Bitmap Scan). Seuls les index B-tree utilisent cette nouvelle API pour l’instant. Il est aussi possible de paralléliser les jointures de type Merge Join.
Même si cette fonctionnalité évolue bien, des limitations assez fortes restent présentes, notamment :
- pas de parallélisation pour les écritures de données (INSERT, UPDATE, DELETE, etc.),
- pas de parallélisation sur les opérations DDL (par exemple un CREATE INDEX ou un VACUUM ne peuvent pas être parallélisés).
VI-E. Mécanisme de coûts▲
-
Modèle basé sur les coûts :
- quantifier la charge pour répondre à une requête.
-
Chaque opération a un coût :
- lire un bloc selon sa position sur le disque,
- manipuler une ligne issue d’une lecture de table ou d’index,
- appliquer un opérateur.
L’optimiseur statistique de PostgreSQL utilise un modèle de calcul de coût. Les coûts calculés sont des indications arbitraires sur la charge nécessaire pour répondre à une requête. Chaque facteur de coût représente une unité de travail : lecture d’un bloc, manipulation des lignes en mémoire, application d’un opérateur sur des données.
VI-E-1. Coûts unitaires▲
-
L’optimiseur a besoin de connaître :
- le coût relatif d’un accès séquentiel au disque,
- le coût relatif d’un accès aléatoire au disque,
- le coût relatif de la manipulation d’une ligne en mémoire,
- le coût de traitement d’une donnée issue d’un index,
- le coût d’application d’un opérateur,
- le coût de la manipulation d’une ligne en mémoire pour un parcours parallélisé,
- le coût de mise en place d’un parcours parallélisé.
- Paramètres modifiables dynamiquement avec SET.
Pour quantifier la charge nécessaire pour répondre à une requête, PostgreSQL utilise un mécanisme de coût. Il part du principe que chaque opération a un coût plus ou moins important.
Sept paramètres permettent d’ajuster les coûts relatifs :
- seq_page_cost représente le coût relatif d’un accès séquentiel au disque. Ce paramètre vaut 1 par défaut.
- random_page_cost représente le coût relatif d’un accès aléatoire au disque. Ce paramètre vaut 4 par défaut, cela signifie que le temps de déplacement de la tête de lecture de façon aléatoire est estimé quatre fois plus important que le temps d’accès d’un bloc au suivant.
- cpu_tuple_cost représente le coût relatif de la manipulation d’une ligne en mémoire. Ce paramètre vaut par défaut 0,01.
- cpu_index_tuple_cost répercute le coût de traitement d’une donnée issue d’un index. Ce paramètre vaut par défaut 0,005.
- cpu_operator_cost indique le coût d’application d’un opérateur sur une donnée. Ce paramètre vaut par défaut 0,0025.
- parallel_tuple_cost indique le coût de traitement d’une ligne lors d’un parcours parallélisé. Ce paramètre vaut par défaut 0,1.
- parallel_setup_cost indique le coût de mise en place d’un parcours parallélisé. Ce paramètre vaut par défaut 1000.
En général, on ne modifie pas ces paramètres sans justification sérieuse. On peut être amené à diminuer random_page_cost si le serveur dispose de disques rapides et d’une carte RAID équipée d’un cache important. Mais en faisant cela, il faut veiller à ne pas déstabiliser des plans optimaux qui obtiennent des temps de réponse constants. À trop diminuer random_page_cost, on peut obtenir de meilleurs temps de réponse si les données sont en cache, mais aussi des temps de réponse dégradés si les données ne sont pas en cache.
Pour des besoins particuliers, ces paramètres sont des paramètres de sessions. Ils peuvent être modifiés dynamiquement avec l’ordre SET au niveau de l’application en vue d’exécuter des requêtes bien particulières.
VI-F. Statistiques▲
-
Toutes les décisions du planificateur se basent sur les statistiques :
- le choix du parcours,
- comme le choix des jointures.
- Statistiques mises à jour avec ANALYZE.
- Sans bonnes statistiques, pas de bons plans.
Le planificateur se base principalement sur les statistiques pour ses décisions. Le choix du parcours, le choix des jointures, le choix de l’ordre des jointures, tout cela dépend des statistiques (et un peu de la configuration). Sans statistiques à jour, le choix du planificateur a un fort risque d’être mauvais. Il est donc important que les statistiques soient mises à jour fréquemment. La mise à jour se fait avec l’instruction ANALYZE qui peut être exécutée manuellement ou automatiquement (via un cron ou l’autovacuum par exemple).
VI-F-1. Utilisation des statistiques▲
-
L’optimiseur utilise les statistiques pour déterminer :
- la cardinalité d’un filtre -> quelle stratégie d’accès,
- la cardinalité d’une jointure -> quel algorithme de jointure,
- la cardinalité d’un regroupement -> quel algorithme de regroupement.
Les statistiques sur les données permettent à l’optimiseur de requêtes de déterminer assez précisément la répartition des valeurs d’une colonne d’une table, sous la forme d’un histogramme de répartition des valeurs. Il dispose encore d’autres informations comme la répartition des valeurs les plus fréquentes, le pourcentage de NULL, le nombre de valeurs distinctes, etc. Toutes ces informations aideront l’optimiseur à déterminer la sélectivité d’un filtre (prédicat de la clause WHERE, condition de jointure) et donc quelle sera la quantité de données récupérées par la lecture d’une table en utilisant le filtre évalué.
Grâce aux statistiques connues par PostgreSQL (voir la vue pg_stats), l’optimiseur est capable de déterminer le chemin le plus intéressant selon les valeurs recherchées.
Ainsi, avec un filtre peu sélectif, date_embauche = '2006-09-01', la requête va ramener pratiquement l’intégralité de la table. PostgreSQL choisira donc une lecture séquentielle de la table, ou Seq Scan :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
EXPLAIN (ANALYZE, TIMING OFF)
SELECT * FROM employes_big WHERE date_embauche='2006-09-01';
QUERY PLAN
----------------------------------------------------------------------
Seq Scan on employes_big (cost=0.00..10901.69 rows=498998 width=40)
(actual rows=499004 loops=1)
Filter: (date_embauche = '2006-09-01'::date)
Rows Removed by Filter: 11
Planning time: 0.027 ms
Execution time: 42.624 ms
(5 rows)
La partie cost montre que l’optimiseur estime que la lecture va ramener 498 998 lignes. Comme on peut le voir, ce n’est pas exact. Il va en récupérer 499 004. Ce n’est qu’une estimation basée sur des statistiques selon la répartition des données et ces estimations seront la plupart du temps erronées. L’important est de savoir si l’erreur est négligeable ou si elle est importante. Dans notre cas, elle est négligeable.
Avec un filtre plus sélectif, la requête ne ramènera que deux lignes. L’optimiseur préférera donc passer par l’index que l’on a créé :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
EXPLAIN (ANALYZE, TIMING OFF)
SELECT * FROM employes_big WHERE date_embauche='2006-01-01';
QUERY PLAN
-----------------------------------------------------------------
Index Scan using employes_big_date_embauche_idx on employes_big
(cost=0.42..8.72 rows=17 width=40) (actual rows=2 loops=1)
Index Cond: (date_embauche = '2006-01-01'::date)
Planning time: 0.055 ms
Execution time: 0.044 ms
(4 rows)
Dans ce deuxième essai, l’optimiseur estime ramener 17 lignes. En réalité, il n’en ramène que deux. L’estimation reste relativement précise étant donné le volume de données.
Dans le premier cas, l’optimiseur estime qu’il est moins coûteux de passer par une lecture séquentielle de la table plutôt qu’une lecture d’index. Dans le second cas, où le filtre est très sélectif, une lecture par index est plus appropriée.
VI-F-2. Statistiques : table et index▲
- Taille.
- Cardinalité.
-
Stocké dans pg_class :
- colonnes relpages et reltuples.
L’optimiseur a besoin de deux données statistiques pour une table ou un index : sa taille physique et le nombre de lignes portées par l’objet.
Ces deux données statistiques sont stockées dans la table pg_class. La taille de la table ou de l’index est exprimée en nombre de blocs de 8 ko et stockée dans la colonne relpages. La cardinalité de la table ou de l’index, c’est-à-dire le nombre de lignes, est stockée dans la colonne reltuples.
L’optimiseur utilisera ces deux informations pour apprécier la cardinalité de la table en fonction de sa volumétrie courante en calculant sa densité estimée, puis en utilisant cette densité multipliée par le nombre actuel de blocs de la table pour estimer le nombre réel de lignes de la table :
density = reltuples / relpages;
tuples = density * curpages;VI-F-3. Statistiques : monocolonne▲
- Nombre de valeurs distinctes.
- Nombre d’éléments qui n’ont pas de valeur NULL.
- Largeur d’une colonne.
-
Distribution des données :
- tableau des valeurs les plus fréquentes,
- histogramme de répartition des valeurs.
Au niveau d’une colonne, plusieurs données statistiques sont stockées :
- le nombre de valeurs distinctes ;
- le nombre d’éléments qui n’ont pas de valeur NULL ;
- la largeur moyenne des données portées par la colonne ;
- le facteur de corrélation entre l’ordre des données triées et la répartition physique des valeurs dans la table ;
- la distribution des données.
La distribution des données est représentée sous deux formes qui peuvent être complémentaires. Tout d’abord, un tableau de répartition permet de connaître les valeurs les plus fréquemment rencontrées et la fréquence d’apparition de ces valeurs. Un histogramme de distribution des valeurs rencontrées permet également de connaître la répartition des valeurs pour la colonne considérée.
VI-F-4. Stockage des statistiques monocolonne▲
-
Les informations statistiques vont dans la table pg_statistic :
- mais elle est difficile à comprendre.
- Mieux vaut utiliser la vue pg_stats.
- Une table vide n’a pas de statistiques.
Le stockage des statistiques se fait dans le catalogue système pg_statistic, mais les colonnes de cette table sont difficiles à interpréter. Il est préférable de passer par la vue pg_stats qui est plus facilement compréhensible par un être humain.
VI-F-5. Vue pg_stats▲
- Une ligne par colonne de chaque table et par index fonctionnel.
-
3 colonnes d’identification :
- schemaname, tablename, attname.
-
8 colonnes d’informations statistiques :
- inherited, null_frac, avg_width, n_distinct,
- most_common_vals, most_common_freqs, histogram_bounds,
- most_common_elems, most_common_elem_freqs, elem_count_histogram,
- correlation.
La vue pg_stats a été créée pour faciliter la compréhension des statistiques récupérées par la commande ANALYZE.
Elle est composée de trois colonnes qui permettent d’identifier la colonne :
- schemaname : nom du schéma (jointure possible avec pg_namespace).
- tablename : nom de la table (jointure possible avec pg_class, intéressant pour récupérer reltuples et relpages).
- attname : nom de la colonne (jointure possible avec pg_attribute, intéressant pour récupérer attstatstarget, valeur d’échantillon).
Suivent ensuite les colonnes de statistiques.
inherited
Si true, les statistiques incluent les valeurs de cette colonne dans les tables filles.
null_frac
Cette statistique correspond au pourcentage de valeurs NULL dans l’échantillon considéré. Elle est toujours calculée.
avg_width
Il s’agit de la largeur moyenne en octets des éléments de cette colonne. Elle est constante pour les colonnes dont le type est à taille fixe (integer, boolean, char, etc.). Dans le cas du type char(n), il s’agit du nombre de caractères saisissables + 1. Il est variable pour les autres (principalement text, varchar, bytea).
n_distinct
Si cette colonne contient un nombre positif, il s’agit du nombre de valeurs distinctes dans l’échantillon. Cela arrive uniquement quand le nombre de valeurs distinctes possibles semble fixe.
Si cette colonne contient un nombre négatif, il s’agit du nombre de valeurs distinctes dans l’échantillon divisé par le nombre de lignes. Cela survient uniquement quand le nombre de valeurs distinctes possibles semble variable. -1 indique donc que toutes les valeurs sont distinctes, -0,5 que chaque valeur apparaît deux fois.
Cette colonne peut être NULL si le type de données n’a pas d’opérateur =.
Il est possible de forcer cette colonne a une valeur constante en utilisant l’ordre ALTER TABLE nom_table ALTER COLUMN nom_colonne SET (parametre = valeur); où parametre vaut soit n_distinct (pour une table standard) soit n_distinct_inherited (pour une table comprenant des partitions). Pour les grosses tables contenant des valeurs distinctes, indiquer une grosse valeur ou la valeur -1 permet de favoriser l’utilisation de parcours d’index à la place de parcours de bitmap. C’est aussi utile pour des tables où les données ne sont pas réparties de façon homogène, et où la collecte de cette statistique est alors faussée.
most_common_vals
Cette colonne contient une liste triée des valeurs les plus communes. Elle peut être NULL si les valeurs semblent toujours aussi communes ou si le type de données n’a pas d’opérateur =.
most_common_freqs
Cette colonne contient une liste triée des fréquences pour les valeurs les plus communes. Cette fréquence est en fait le nombre d’occurrences de la valeur divisé par le nombre de lignes. Elle est NULL si most_common_vals est NULL.
histogram_bounds
PostgreSQL prend l’échantillon récupéré par ANALYZE. Il trie ces valeurs. Ces données triées sont partagées en x tranches égales (aussi appelées classes), où x dépend de la valeur du paramètre default_statistics_target ou de la configuration spécifique de la colonne. Il construit ensuite un tableau dont chaque valeur correspond à la valeur de début d’une tranche.
most_common_elems, most_common_elem_freqs, elem_count_histogram
Ces trois colonnes sont équivalentes aux trois précédentes, mais uniquement pour les données de type tableau.
correlation
Cette colonne est la corrélation statistique entre l’ordre physique et l’ordre logique des valeurs de la colonne. Si sa valeur est proche de -1 ou 1, un parcours d’index est privilégié. Si elle est proche de 0, un parcours séquentiel est mieux considéré.
Cette colonne peut être NULL si le type de données n’a pas d’opérateur <.
VI-F-6. Statistiques : multicolonnes▲
- Pas par défaut.
- CREATE STATISTICS.
-
Deux types de statistique :
- nombre de valeurs distinctes,
- dépendances fonctionnelles.
- À partir de la version 10.
Par défaut, la commande ANALYZE de PostgreSQL calcule des statistiques monocolonnes uniquement. Depuis la version 10, elle peut aussi calculer certaines statistiques multicolonnes.
Pour cela, il est nécessaire de créer un objet statistique avec l’ordre SQL CREATE STATISTICS. Cet objet indique les colonnes concernées ainsi que le type de statistique souhaité.
Actuellement, PostgreSQL supporte deux types de statistiques pour ces objets :
- ndistinct pour le nombre de valeurs distinctes sur ces colonnes ;
- dependencies pour les dépendances fonctionnelles.
Dans les deux cas, cela peut permettre d’améliorer fortement les estimations de nombre de lignes, ce qui ne peut qu’amener de meilleurs plans d’exécution.
Prenons un exemple. On peut voir sur ces deux requêtes que les statistiques sont à jour :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
EXPLAIN (ANALYZE)
SELECT * FROM services_big WHERE localisation='Paris';
QUERY PLAN
-------------------------------------------------------------------
Seq Scan on services_big (cost=0.00..786.05 rows=10013 width=28)
(actual time=0.019..4.773 rows=10001 loops=1)
Filter: ((localisation)::text = 'Paris'::text)
Rows Removed by Filter: 30003
Planning time: 0.863 ms
Execution time: 5.289 ms
(5 rows)
EXPLAIN (ANALYZE)
SELECT * FROM services_big where departement=75;
QUERY PLAN
-------------------------------------------------------------------
Seq Scan on services_big (cost=0.00..786.05 rows=10013 width=28)
(actual time=0.020..7.013 rows=10001 loops=1)
Filter: (departement = 75)
Rows Removed by Filter: 30003
Planning time: 0.219 ms
Execution time: 7.785 ms
(5 rows)
Cela fonctionne bien (c.-à-d. l’estimation du nombre de lignes est très proche de la réalité) dans le cas spécifique où le filtre se fait sur une seule colonne. Par contre, si le filtre se fait sur les deux colonnes, l’estimation diffère d’un facteur d’échelle :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
EXPLAIN (ANALYZE)
SELECT * FROM services_big where localisation='Paris' and departement=75;
QUERY PLAN
---------------------------------------------------------------------------
Seq Scan on services_big (cost=0.00..886.06 rows=2506 width=28)
(actual time=0.032..7.081 rows=10001 loops=1)
Filter: (((localisation)::text = 'Paris'::text) AND (departement = 75))
Rows Removed by Filter: 30003
Planning time: 0.257 ms
Execution time: 7.767 ms
(5 rows)
En fait, il y a une dépendance fonctionnelle entre ces deux colonnes, mais PostgreSQL ne le sait pas, car ses statistiques sont monocolonnes par défaut. Pour avoir des statistiques sur les deux colonnes, il faut créer un objet statistique pour ces deux colonnes :
2.
3.
CREATE STATISTICS stat_services_big (dependencies)
ON localisation, departement
FROM services_big;
Après création de l’objet statistique, il ne faut pas oublier de calculer les statistiques :
ANALYZE services_big;
Ceci fait, on peut de nouveau regarder les estimations :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
EXPLAIN (ANALYZE)
SELECT * FROM services_big where localisation='Paris' and departement=75;
QUERY PLAN
---------------------------------------------------------------------------
Seq Scan on services_big (cost=0.00..886.06 rows=10038 width=28)
(actual time=0.008..6.249 rows=10001 loops=1)
Filter: (((localisation)::text = 'Paris'::text) AND (departement = 75))
Rows Removed by Filter: 30003
Planning time: 0.121 ms
Execution time: 6.849 ms
(5 rows)
Cette fois, l’estimation est beaucoup plus proche de la réalité.
Maintenant, prenons le cas d’un regroupement :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
EXPLAIN (ANALYZE)
SELECT localisation, COUNT(*) FROM services_big GROUP BY localisation;
QUERY PLAN
------------------------------------------------------------------------
HashAggregate (cost=886.06..886.10 rows=4 width=14)
(actual time=12.925..12.926 rows=4 loops=1)
Group Key: localisation
-> Seq Scan on services_big (cost=0.00..686.04 rows=40004 width=6)
(actual time=0.010..2.779 rows=40004 loops=1)
Planning time: 0.162 ms
Execution time: 13.033 ms
(5 rows)
L’estimation du nombre de lignes pour un regroupement sur une colonne est très bonne. Par contre, sur deux colonnes :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
EXPLAIN (ANALYZE)
SELECT localisation, departement, COUNT(*)
FROM services_big
GROUP BY localisation, departement;
QUERY PLAN
-------------------------------------------------------------------------
HashAggregate (cost=986.07..986.23 rows=16 width=18)
(actual time=15.830..15.831 rows=4 loops=1)
Group Key: localisation, departement
-> Seq Scan on services_big (cost=0.00..686.04 rows=40004 width=10)
(actual time=0.005..3.094 rows=40004 loops=1)
Planning time: 0.102 ms
Execution time: 15.860 ms
(5 rows)
Là-aussi, on constate un facteur d’échelle important entre l’estimation et la réalité. Et là-aussi, c’est un cas où un objet statistique peut fortement aider :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
DROP STATISTICS stat_services_big;
CREATE STATISTICS stat_services_big (dependencies,ndistinct)
ON localisation, departement
FROM services_big;
ANALYZE services_big ;
EXPLAIN (ANALYZE)
SELECT localisation, departement, COUNT(*)
FROM services_big
GROUP BY localisation, departement;
QUERY PLAN
-------------------------------------------------------------------------
HashAggregate (cost=986.07..986.11 rows=4 width=18)
(actual time=14.351..14.352 rows=4 loops=1)
Group Key: localisation, departement
-> Seq Scan on services_big (cost=0.00..686.04 rows=40004 width=10)
(actual time=0.013..2.786 rows=40004 loops=1)
Planning time: 0.305 ms
Execution time: 14.413 ms
(5 rows)
L’estimation est bien meilleure grâce aux statistiques spécifiques aux deux colonnes.
VI-F-7. Catalogue pg_statistic_ext▲
- Une ligne par objet statistique.
-
Quatre colonnes d’identification :
- stxrelid, stxname, stxnamespace, stxkeys.
-
Une colonne pour connaître le type de statistiques géré :
- stxkind.
-
Deux colonnes d’informations statistiques :
- stxndistinct.
- stxdependencies.
stxname est le nom de l’objet statistique, et stxnamespace l’OID de son schéma.
stxrelid précise l’OID de la table concernée par cette statistique. stxkeys est un tableau d’entiers correspondant aux numéros des colonnes.
stxkind peut avoir une ou plusieurs valeurs parmi d pour le nombre de valeurs distinctes et f pour les dépendances fonctionnelles.
Voici un exemple sur l’objet statistique créé précédemment :
2.
3.
4.
5.
6.
7.
8.
9.
10.
postgres=# select * from pg_statistic_ext;
-[ RECORD 1 ]---+-----------------------------------------
stxrelid | 16394
stxname | stat_services_big
stxnamespace | 2200
stxowner | 10
stxkeys | 3 4
stxkind | {d,f}
stxndistinct | {"3, 4": 4}
stxdependencies | {"3 => 4": 1.000000, "4 => 3": 1.000000}
VI-F-8. ANALYZE▲
- Ordre SQL de calcul de statistiques :
ANALYZE[ VERBOSE ][ table [ ( colonne [, ...])] ] - Sans argument : base entière.
- Avec argument : la table complète ou certaines colonnes seulement.
- Prend un échantillon de chaque table.
- Et calcule des statistiques sur cet échantillon.
- Si table vide, conservation des anciennes statistiques.
ANALYZE est l’ordre SQL permettant de mettre à jour les statistiques sur les données. Sans argument, l’analyse se fait sur la base complète. Si un argument est donné, il doit correspondre au nom de la table à analyser. Il est même possible d’indiquer les colonnes à traiter.
En fait, cette instruction va exécuter un calcul d’un certain nombre de statistiques. Elle ne va pas lire la table entière, mais seulement un échantillon. Sur cet échantillon, chaque colonne sera traitée pour récupérer quelques informations comme le pourcentage de valeurs NULL, les valeurs les plus fréquentes et leur fréquence, sans parler d’un histogramme des valeurs. Toutes ces informations sont stockées dans un catalogue système nommé pg_statistics.
Dans le cas d’une table vide, les anciennes statistiques sont conservées. S’il s’agit d’une nouvelle table, les statistiques sont initialement vides. La table n’est jamais considérée vide par l’optimiseur, qui utilise alors des valeurs par défaut.
VI-F-9. Fréquence d’analyse▲
- Dépend principalement de la fréquence des requêtes DML.
-
Cron :
- avec psql,
- avec vacuumdb et son option --analyze-only.
-
Autovacuum fait du ANALYZE mais… :
- pas sur les tables temporaires,
- pas assez rapidement dans certains cas.
Les statistiques doivent être mises à jour fréquemment. La fréquence exacte dépend surtout de la fréquence des requêtes d’insertion/modification/ suppression des lignes des tables. Néanmoins, un ANALYZE tous les jours semble un minimum, sauf cas spécifique.
L’exécution périodique peut se faire avec cron (ou les tâches planifiées sous Windows). Il n’existe pas d’outils PostgreSQL pour lancer un seul ANALYZE . L’outil vacuumdb se voit doté d’une option --analyze-only pour combler ce manque. Avant, il était nécessaire de passer par psql et son option -c qui permet de préciser la requête à exécuter. En voici un exemple :
psql -c "ANALYZE" b1
Cet exemple exécute la commande ANALYZE sur la base b1 locale.
Le démon autovacuum fait aussi des ANALYZE. La fréquence dépend de sa configuration. Cependant, il faut connaître deux particularités de cet outil :
- Ce démon a sa propre connexion à la base. Il ne peut donc pas voir les tables temporaires appartenant aux autres sessions. Il ne sera donc pas capable de mettre à jour leurs statistiques.
- Après une insertion ou une mise à jour massive, autovacuum ne va pas forcément lancer un ANALYZE immédiat. En effet, autovacuum ne cherche les tables à traiter que toutes les minutes (par défaut). Si, après la mise à jour massive, une requête est immédiatement exécutée, il y a de fortes chances qu’elle s’exécute avec des statistiques obsolètes. Il est préférable dans ce cas de lancer un ANALYZE manuel sur la ou les tables ayant subi l’insertion ou la mise à jour massive.
VI-F-10. Échantillon statistique▲
-
Se configure dans postgresql.conf :
- default_statistics_target = 100.
- Configurable par colonne :
ALTER TABLE nom ALTER [ COLUMN ] colonne
SET STATISTICS valeur;-
Par défaut, récupère 30 000 lignes au hasard :
- 300 * default_statistics_target.
- Va conserver les cent valeurs les plus fréquentes avec leur fréquence.
Par défaut, un ANALYZE récupère 30 000 lignes d’une table. Les statistiques générées à partir de cet échantillon sont bonnes si la table ne contient pas des millions de lignes. Si c’est le cas, il faudra augmenter la taille de l’échantillon. Pour cela, il faut augmenter la valeur du paramètre default_statistics_target. Ce dernier vaut 100 par défaut. La taille de l’échantillon est de 300 x default_statistics_target. Augmenter ce paramètre va avoir plusieurs répercussions. Les statistiques seront plus précises grâce à un échantillon plus important. Mais du coup, les statistiques seront plus longues à calculer, prendront plus de place sur le disque, et demanderont plus de travail au planificateur pour générer le plan optimal. Augmenter cette valeur n’a donc pas que des avantages.
Du coup, les développeurs de PostgreSQL ont fait en sorte qu’il soit possible de le configurer colonne par colonne avec l’instruction suivante :
ALTER TABLE nom_table ALTER nom_colonne SET STATISTICS valeur;
VI-G. Qu’est-ce qu’un plan d’exécution ?▲
- Représente les différentes opérations pour répondre à la requête.
- Sous forme arborescente.
- Composé des nœuds d’exécution.
- Plusieurs opérations simples mises bout à bout.
VI-G-1. Nœud d’exécution▲
-
Nœud :
- opération simple : lectures, jointures, tris, etc.,
- unité de traitement,
- produit et consomme des données.
-
Enchaînement des opérations :
- chaque nœud produit les données consommées par le nœud parent,
- le nœud final retourne les données à l’utilisateur.
Les nœuds correspondent à des unités de traitement qui réalisent des opérations simples sur un ou deux ensembles de données : lecture d’une table, jointures entre deux tables, tri d’un ensemble, etc. Si le plan d’exécution était une recette, chaque nœud serait une étape de la recette.
Les nœuds peuvent produire et consommer des données.
VI-G-2. Récupérer un plan d’exécution▲
-
Commande EXPLAIN :
- suivi de la requête complète.
- Uniquement le plan finalement retenu.
Pour récupérer le plan d’exécution d’une requête, il suffit d’utiliser la commande EXPLAIN. Cette commande est suivie de la requête pour laquelle on souhaite le plan d’exécution.
Seul le plan sélectionné est affichable. Les plans ignorés du fait de leur coût trop important ne sont pas récupérables. Ceci est dû au fait que les plans en question peuvent être abandonnés avant d’avoir été totalement développés si leur coût partiel est déjà supérieur à celui de plans déjà considérés.
VI-G-3. Lecture d’un plan▲
|
|

Un plan d’exécution est lu en partant du nœud se trouvant le plus à droite et en remontant jusqu’au nœud final. Quand le plan contient plusieurs nœuds, le premier nœud exécuté est celui qui se trouve le plus à droite. Celui qui est le plus à gauche (la première ligne) est le dernier nœud exécuté. Tous les nœuds sont exécutés simultanément, et traitent les données dès qu’elles sont transmises par le nœud parent (le ou les nœuds juste en dessous, à droite).
Chaque nœud montre les coûts estimés dans le premier groupe de parenthèses :
- cost est un couple de deux coûts ;
- la première valeur correspond au coût pour récupérer la première ligne (souvent nul dans le cas d’un parcours séquentiel) ;
- la deuxième valeur correspond au coût pour récupérer toutes les lignes (cette valeur dépend essentiellement de la taille de la table lue, mais aussi de l’opération de filtre ici présente) ;
- rows correspond au nombre de lignes que le planificateur pense récupérer à la sortie de ce nœud ;
- width est la largeur en octets de la ligne.
Cet exemple simple permet de voir le travail de l’optimiseur :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
SET enable_nestloop TO off;
EXPLAIN
SELECT matricule, nom, prenom, nom_service, fonction, localisation
FROM employes emp
JOIN services ser ON (emp.num_service = ser.num_service)
WHERE ser.localisation = 'Nantes';
QUERY PLAN
-------------------------------------------------------------------------
Hash Join (cost=1.06..2.34 rows=4 width=48)
Hash Cond: (emp.num_service = ser.num_service)
-> Seq Scan on employes emp (cost=0.00..1.14 rows=14 width=35)
-> Hash (cost=1.05..1.05 rows=1 width=21)
-> Seq Scan on services ser (cost=0.00..1.05 rows=1 width=21)
Filter: ((localisation)::text = 'Nantes'::text)
(6 rows)
RESET enable_nestloop;
Ce plan débute par la lecture de la table services. L’optimiseur estime que cette lecture ramènera une seule ligne (rows=1), que cette ligne occupera 21 octets en mémoire (width=21). Il s’agit de la sélectivité du filtre WHERE localisation = 'Nantes'. Le coût de départ de cette lecture est de 0 (cost=0.00). Le coût total de cette lecture est de 1.05, qui correspond à la lecture séquentielle d’un seul bloc (donc seq_page_cost) et à la manipulation des 4 lignes de la table services (donc 4 * cpu_tuple_cost + 4 * cpu_operator_cost). Le résultat de cette lecture est ensuite haché par le nœud Hash, qui précède la jointure de type Hash Join.
La jointure peut maintenant commencer, avec le nœud Hash Join. Il est particulier, car il prend deux entrées : la donnée hachée initialement, et les données issues de la lecture d’une seconde table (peu importe le type d’accès). Le nœud a un coût de démarrage de 1.06, soit le coût du hachage additionné au coût de manipulation du tuple de départ. Il s’agit du coût de production du premier tuple de résultat. Le coût total de production du résultat est de 2.34. La jointure par hachage démarre réellement lorsque la lecture de la table employes commence. Cette lecture remontera 14 lignes, sans application de filtre. La totalité de la table est donc remontée et elle est très petite donc tient sur un seul bloc de 8 ko. Le coût d’accès total est donc facilement déduit à partir de cette information. À partir des sélectivités précédentes, l’optimiseur estime que la jointure ramènera 4 lignes au total.
VI-G-4. Options de l’EXPLAIN▲
-
Des options supplémentaires :
- ANALYZE: exécution (danger !),
- BUFFERS: blocs read/hit/written, shared/local/temp,
- COSTS: par défaut,
- TIMING: par défaut,
- VERBOSE: colonnes considérées,
- SUMMARY: temps de planification,
- FORMAT : sortie en XML, JSON, YAML.
-
Donnant des informations supplémentaires très utiles :
- ou permettant de cacher des informations inutiles.
Au fil des versions, EXPLAIN a gagné en options. L’une d’entre elles permet de sélectionner le format en sortie. Toutes les autres permettent d’obtenir des informations supplémentaires.
Option ANALYZE
Le but de cette option est d’obtenir les informations sur l’exécution réelle de la requête.
Avec cette option, la requête est réellement exécutée. Attention aux INSERT/ UPDATE/DELETE. Pensez à les englober dans une transaction que vous annulerez après coup.
Voici un exemple utilisant cette option :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
EXPLAIN (ANALYZE) SELECT * FROM employes WHERE matricule < 100;
QUERY PLAN
---------------------------------------------------------
Seq Scan on employes (cost=0.00..1.18 rows=3 width=43)
(actual time=0.004..0.005 rows=3 loops=1)
Filter: (matricule < 100)
Rows Removed by Filter: 11
Planning time: 0.027 ms
Execution time: 0.013 ms
(5 rows)
Quatre nouvelles informations apparaissent, toutes liées à l’exécution réelle de la requête :
- actual time ;
- la première valeur correspond à la durée en millisecondes pour récupérer la première ligne ;
- la deuxième valeur est la durée en millisecondes pour récupérer toutes les lignes ;
- rows est le nombre de lignes réellement récupérées ;
- loops est le nombre d’exécutions de ce nœud.
Multiplier la durée par le nombre de boucles pour obtenir la durée réelle d’exécution du nœud.
L’intérêt de cette option est donc de trouver l’opération qui prend du temps dans l’exécution de la requête, mais aussi de voir les différences entre les estimations et la réalité (notamment au niveau du nombre de lignes).
Option BUFFERS
Cette option n’est utilisable qu’avec l’option ANALYZE. Elle est désactivée par défaut.
Elle indique le nombre de blocs impactés par chaque nœud du plan d’exécution, en lecture comme en écriture.
Voici un exemple de son utilisation :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM employes WHERE matricule < 100;
QUERY PLAN
---------------------------------------------------------
Seq Scan on employes (cost=0.00..1.18 rows=3 width=43)
(actual time=0.002..0.004 rows=3 loops=1)
Filter: (matricule < 100)
Rows Removed by Filter: 11
Buffers: shared hit=1
Planning time: 0.024 ms
Execution time: 0.011 ms
(6 rows)
La nouvelle ligne est la ligne Buffers. Elle peut contenir un grand nombre d’informations :
|
Informations |
Type d’objet concerné |
Explications |
|---|---|---|
|
Shared hit |
Table ou index permanent |
Lecture d’un bloc dans le cache |
|
Shared read |
Table ou index permanent |
Lecture d’un bloc hors du cache |
|
Shared written |
Table ou index permanent |
Écriture d’un bloc |
|
Local hit |
Table ou index temporaire |
Lecture d’un bloc dans le cache |
|
Local read |
Table ou index temporaire |
Lecture d’un bloc hors du cache |
|
Local written |
Table ou index temporaire |
Écriture d’un bloc |
|
Temp read |
Tris et hachages |
Lecture d’un bloc |
|
Temp written |
Tris et hachages |
Écriture d’un bloc |
Option COSTS
Une fois activée, l’option COSTS indique les estimations du planificateur. Cette option est activée par défaut.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
EXPLAIN (COSTS OFF) SELECT * FROM employes WHERE matricule < 100;
QUERY PLAN
-----------------------------
Seq Scan on employes
Filter: (matricule < 100)
(2 rows)
EXPLAIN (COSTS ON) SELECT * FROM employes WHERE matricule < 100;
QUERY PLAN
---------------------------------------------------------
Seq Scan on employes (cost=0.00..1.18 rows=3 width=43)
Filter: (matricule < 100)
(2 rows)
Option TIMING
Cette option n’est utilisable qu’avec l’option ANALYZE. Elle ajoute les informations sur les durées en millisecondes. Elle est activée par défaut. Sa désactivation peut être utile sur certains systèmes où le chronométrage prend beaucoup de temps et allonge inutilement la durée d’exécution de la requête.
Voici un exemple de son utilisation :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
EXPLAIN (ANALYZE, TIMING ON) SELECT * FROM employes WHERE matricule < 100;
QUERY PLAN
---------------------------------------------------------
Seq Scan on employes (cost=0.00..1.18 rows=3 width=43)
(actual time=0.003..0.004 rows=3 loops=1)
Filter: (matricule < 100)
Rows Removed by Filter: 11
Planning time: 0.022 ms
Execution time: 0.010 ms
(5 rows)
EXPLAIN (ANALYZE, TIMING OFF) SELECT * FROM employes WHERE matricule < 100;
QUERY PLAN
---------------------------------------------------------
Seq Scan on employes (cost=0.00..1.18 rows=3 width=43)
(actual rows=3 loops=1)
Filter: (matricule < 100)
Rows Removed by Filter: 11
Planning time: 0.025 ms
Execution time: 0.010 ms
(5 rows)
Option VERBOSE
L’option VERBOSE permet d’afficher des informations supplémentaires comme la liste des colonnes en sortie, le nom de la table qualifié du nom du schéma, le nom de la fonction qualifié du nom du schéma, le nom du trigger, etc. Elle est désactivée par défaut.
2.
3.
4.
5.
6.
7.
8.
9.
EXPLAIN (VERBOSE) SELECT * FROM employes WHERE matricule < 100;
QUERY PLAN
---------------------------------------------------------------------
Seq Scan on public.employes (cost=0.00..1.18 rows=3 width=43)
Output: matricule, nom, prenom, fonction, manager, date_embauche,
num_service
Filter: (employes.matricule < 100)
(3 rows)
On voit dans cet exemple que le nom du schéma est ajouté au nom de la table. La nouvelle section Output indique la liste des colonnes de l’ensemble de données en sortie du nœud.
Option SUMMARY
Cette option apparaît en version 10. Elle permet d’afficher ou non le résumé final indiquant la durée de la planification et de l’exécution. Un EXPLAIN simple n’affiche pas le résumé par défaut. Par contre, un EXPLAIN ANALYZE l’affiche par défaut.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
EXPLAIN SELECT * FROM employes;
QUERY PLAN
----------------------------------------------------------
Seq Scan on employes (cost=0.00..1.14 rows=14 width=43)
(1 row)
EXPLAIN (SUMMARY ON) SELECT * FROM employes;
QUERY PLAN
----------------------------------------------------------
Seq Scan on employes (cost=0.00..1.14 rows=14 width=43)
Planning time: 0.014 ms
(2 rows)
EXPLAIN (ANALYZE) SELECT * FROM employes;
QUERY PLAN
----------------------------------------------------------
Seq Scan on employes (cost=0.00..1.14 rows=14 width=43)
(actual time=0.002..0.003 rows=14 loops=1)
Planning time: 0.013 ms
Execution time: 0.009 ms
(3 rows)
EXPLAIN (ANALYZE, SUMMARY OFF) SELECT * FROM employes;
QUERY PLAN
----------------------------------------------------------
Seq Scan on employes (cost=0.00..1.14 rows=14 width=43)
(actual time=0.002..0.003 rows=14 loops=1)
(1 row)
Option FORMAT
L’option FORMAT permet de préciser le format du texte en sortie. Par défaut, il s’agit du texte habituel, mais il est possible de choisir un format balisé parmi XML, JSON et YAML. Voici ce que donne la commande EXPLAIN avec le format XML :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
EXPLAIN (FORMAT XML) SELECT * FROM employes WHERE matricule < 100;
QUERY PLAN
----------------------------------------------------------
<explain xmlns="http://www.postgresql.org/2009/explain">+
<Query> +
<Plan> +
<Node-Type>Seq Scan</Node-Type> +
<Parallel-Aware>false</Parallel-Aware> +
<Relation-Name>employes</Relation-Name> +
<Alias>employes</Alias> +
<Startup-Cost>0.00</Startup-Cost> +
<Total-Cost>1.18</Total-Cost> +
<Plan-Rows>3</Plan-Rows> +
<Plan-Width>43</Plan-Width> +
<Filter>(matricule < 100)</Filter> +
</Plan> +
</Query> +
</explain>
(1 row)
Les formats semi-structurés sont utilisés principalement par des outils pour qu’ils retrouvent facilement les informations. Par exemple, pgAdmin IV utilise le format JSON pour afficher graphiquement un plan d’exécution.
VI-G-5. Détecter les problèmes▲
- Différence importante entre l’estimation du nombre de lignes et la réalité.
-
Boucles :
- appels très nombreux dans une boucle (Nested loop),
- opérations lentes sur lesquelles PostgreSQL boucle.
- Temps d’exécution important sur une opération.
- Opérations utilisant beaucoup de blocs (option BUFFERS).
Lorsqu’une requête s’exécute lentement, cela peut être un problème dans le plan. La sortie de EXPLAIN peut apporter quelques informations qu’il faut savoir décoder. Une différence importante entre le nombre estimé de lignes et le nombre réel de lignes laisse un doute sur les statistiques présentes. Soit elles n’ont pas été réactualisées récemment, soit l’échantillon n’est pas suffisamment important pour que les statistiques donnent une vue proche du réel contenu de la table.
L’option BUFFERS d’EXPLAIN permet également de mettre en valeur les opérations d’entrées/sorties lourdes. Cette option affiche notamment le nombre de blocs lus en/hors du cache de PostgreSQL. Sachant qu’un bloc fait généralement 8 ko, il est aisé de déterminer le volume de données manipulé par une requête.
VI-G-6. Statistiques et coûts▲
-
Détermine à partir des statistiques :
- cardinalité des prédicats,
- cardinalité des jointures.
-
Coût d’accès déterminé selon :
- des cardinalités,
- volumétrie des tables.
Afin de comparer les différents plans d’exécution possibles pour une requête et choisir le meilleur, l’optimiseur a besoin d’estimer un coût pour chaque nœud du plan.
L’estimation la plus cruciale est celle liée aux nœuds de parcours de données, car c’est d’eux que découlera la suite du plan. Pour estimer le coût de ces nœuds, l’optimiseur s’appuie sur les informations statistiques collectées, ainsi que sur la valeur de paramètres de configuration.
Les deux notions principales de ce calcul sont la cardinalité (nombre de lignes estimées en sortie d’un nœud) et la sélectivité (fraction des lignes conservées après l’application d’un filtre).
Voici ci-dessous un exemple de calcul de cardinalité et de détermination du coût associé.
Calcul de cardinalité
Pour chaque prédicat et chaque jointure, PostgreSQL va calculer sa sélectivité et sa cardinalité. Pour un prédicat, cela permet de déterminer le nombre de lignes retournées par le prédicat par rapport au nombre total de lignes de la table. Pour une jointure, cela permet de déterminer le nombre de lignes retournées par la jointure entre deux tables.
L’optimiseur dispose de plusieurs façons de calculer la cardinalité d’un filtre ou d’une jointure selon que la valeur recherchée est une valeur unique, que la valeur se trouve dans le tableau des valeurs les plus fréquentes ou dans l’histogramme. L’exemple ci-dessous montre comment calculer la cardinalité d’un filtre simple sur une table employes de 14 lignes. La valeur recherchée se trouve dans le tableau des valeurs les plus fréquentes, la cardinalité peut être calculée directement. Si ce n’était pas le cas, il aurait fallu passer par l’histogramme des valeurs pour calculer d’abord la sélectivité du filtre pour en déduire ensuite la cardinalité.
La requête suivante permet de récupérer la fréquence d’apparition de la valeur recherchée dans le prédicat WHERE num_service = 1 pour notre table d’exemple employes :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
SELECT tablename, attname, value, freq
FROM (SELECT tablename, attname, mcv.value, mcv.freq FROM pg_stats,
LATERAL ROWS FROM (unnest(most_common_vals::text::int[]),
unnest(most_common_freqs)) AS mcv(value, freq)
WHERE tablename = 'employes'
AND attname = 'num_service') get_mcv
WHERE value = 1;
tablename | attname | value | freq
-----------+-------------+-------+----------
employes | num_service | 1 | 0.142857
(1 row)
L’optimiseur calcule la cardinalité du prédicat WHERE num_service = 1 en multipliant cette fréquence de la valeur recherchée avec le nombre total de lignes de la table :
2.
3.
4.
5.
6.
7.
8.
SELECT 0.142857 * reltuples AS cardinalite_predicat
FROM pg_class
WHERE relname = 'employes';
cardinalite_predicat
----------------------
1.999998
(1 row)
On peut vérifier que le calcul est bon en obtenant le plan d’exécution de la requête impliquant la lecture de employes sur laquelle on applique le prédicat évoqué plus haut :
2.
3.
4.
5.
6.
7.
EXPLAIN SELECT * FROM employes WHERE num_service = 1;
QUERY PLAN
---------------------------------------------------------
Seq Scan on employes (cost=0.00..1.18 rows=2 width=43)
Filter: (num_service = 1)
(2 rows)
Calcul de coût
Notre table employes peuplée de 14 lignes va permettre de montrer le calcul des coûts réalisé par l’optimiseur. L’exemple présenté ci-dessous est simplifié. En réalité, les calculs sont plus complexes, car ils tiennent également compte de la volumétrie réelle de la table.
Le coût de la lecture séquentielle de la table employes est calculé à partir de deux composantes. Tout d’abord, le nombre de pages (ou blocs) de la table permet de déduire le nombre de blocs à accéder pour lire la table intégralement. Le paramètre seq_page_cost sera appliqué ensuite pour indiquer le coût de l’opération :
2.
3.
4.
5.
6.
7.
SELECT relname, relpages * current_setting('seq_page_cost')::float AS cout_acces
FROM pg_class
WHERE relname = 'employes';
relname | cout_acces
----------+------------
employes | 1
Cependant, le coût d’accès seul ne représente pas le coût de la lecture des données. Une fois que le bloc est monté en mémoire, PostgreSQL doit décoder chaque ligne individuellement. L’optimiseur utilise cpu_tuple_cost pour estimer le coût de manipulation des lignes :
2.
3.
4.
5.
6.
7.
8.
9.
10.
SELECT relname,
relpages * current_setting('seq_page_cost')::float
+ reltuples * current_setting('cpu_tuple_cost')::float AS cout
FROM pg_class
WHERE relname = 'employes';
relname | cout
----------+------
employes | 1.14
(1 row)
On peut vérifier que le calcul est bon :
2.
3.
4.
5.
6.
EXPLAIN SELECT * FROM employes;
QUERY PLAN
----------------------------------------------------------
Seq Scan on employes (cost=0.00..1.14 rows=14 width=43)
(1 row)
Si l’on applique un filtre à la requête, les traitements seront plus lourds. Par exemple, en ajoutant le prédicat WHERE date_embauche='2006-01-01'.
Il faut non seulement extraire les lignes les unes après les autres, mais il faut également appliquer l’opérateur de comparaison utilisé. L’optimiseur utilise le paramètre cpu_operator_cost pour déterminer le coût d’application d’un filtre :
2.
3.
4.
5.
6.
7.
8.
9.
10.
SELECT relname,
relpages * current_setting('seq_page_cost')::float
+ reltuples * current_setting('cpu_tuple_cost')::float
+ reltuples * current_setting('cpu_operator_cost')::float AS cost
FROM pg_class
WHERE relname = 'employes';
relname | cost
----------+-------
employes | 1.175
En récupérant le plan d’exécution de la requête à laquelle est appliqué le filtre WHERE date_embauche='2006-01-01', on s’aperçoit que le calcul est juste, à l’arrondi près :
2.
3.
4.
5.
6.
7.
EXPLAIN SELECT * FROM employes WHERE date_embauche='2006-01-01';
QUERY PLAN
---------------------------------------------------------
Seq Scan on employes (cost=0.00..1.18 rows=2 width=43)
Filter: (date_embauche = '2006-01-01'::date)
(2 rows)
Pour aller plus loin dans le calcul de sélectivité, de cardinalité et de coût, la documentation de PostgreSQL montre un exemple complet de calcul de sélectivité et indique les références des fichiers sources dans lesquels fouiller pour en savoir plus : Comment le planificateur utilise les statistiques.
VI-H. Nœuds d’exécution les plus courants▲
- Un plan est composé de nœuds.
- Certains produisent des données.
- D’autres consomment des données et les retournent.
- Le nœud final retourne les données à l’utilisateur.
- Chaque nœud consomme au fur et à mesure les données produites par les nœuds parents.
VI-H-1. Nœuds de type parcours▲
- Parcours de table.
- Parcours d’index.
- Autres parcours.
Par parcours, on entend le renvoi d’un ensemble de lignes provenant soit d’un fichier soit d’un traitement.
Le fichier peut correspondre à une table ou à une vue matérialisée, et on parle dans ces deux cas d’un parcours de table. Nous verrons qu’il en existe deux types.
Le fichier peut aussi correspondre à un index, auquel cas on parle de parcours d’index. Il existe trois types de parcours d’index.
Un traitement peut être effectué dans différents cas, même si principalement cela vient d’une procédure stockée.
VI-H-2. Parcours de table▲
- Seq Scan.
-
Paramètres :
- seq_page_cost, cpu_tuple_cost, cpu_operator_cost,
- enable_seqscan.
-
Parallel Seq Scan (9.6+) :
- parallel_tuple_cost,
- min_parallel_table_scan_size (v10).
Les parcours de tables sont les seules opérations qui lisent les données des tables (normales, temporaires ou non journalisées) et des vues matérialisées. Elles ne prennent donc rien en entrée et fournissent un ensemble de données en sortie. Cet ensemble peut être trié ou non, filtré ou non.
Il existe deux types de parcours de table :
- le parcours séquentiel (Seq Scan) ;
- le parcours séquentiel parallélisé (Parallel Seq Scan).
Ce dernier n’apparaît qu’à partir de la version 9.6.
L’opération Seq Scan correspond à une lecture séquentielle d’une table, aussi appelée Full table scan sur d’autres SGBD. Il consiste à lire l’intégralité de la table, du premier bloc au dernier bloc. Une clause de filtrage peut être appliquée.
On retrouve ce nœud lorsque la requête nécessite de lire l’intégralité ou la majorité de la table :
2.
3.
4.
5.
6.
EXPLAIN SELECT * FROM employes;
QUERY PLAN
----------------------------------------------------------
Seq Scan on employes (cost=0.00..1.14 rows=14 width=43)
(1 row)
Ce nœud peut également filtrer directement les données, la présence de la clause Filter montre le filtre appliqué à la lecture des données :
2.
3.
4.
5.
6.
7.
EXPLAIN SELECT * FROM employes WHERE matricule=135;
QUERY PLAN
---------------------------------------------------------
Seq Scan on employes (cost=0.00..1.18 rows=1 width=43)
Filter: (matricule = 135)
(2 rows)
Le coût pour ce type de nœud sera dépendant du nombre de blocs à parcourir et du paramètre seq_page_cost, ainsi que du nombre de lignes à décoder et, optionnellement, à filtrer.
Il est possible d’avoir un parcours parallélisé d’une table sous certaines conditions. La première est qu’il faut avoir au minimum une version 9.6 et que la parallélisation soit activée (max_parallel_workers_per_gather non nul et, en v10, aussi max_parallel_workers non nul). La table traitée doit avoir une taille minimale indiquée par le paramètre min_parallel_table_scan_size (en version 10) ou min_parallel_relation_size (en 9.6), dont le défaut est 8 Mo. Pour que ce type de parcours soit valable, il faut que l’optimiseur soit persuadé que le problème sera le temps CPU et non la bande passante disque. Autrement dit, dans la majorité des cas, il faut un filtre pour que la parallélisation se déclenche, et il faut que la table soit suffisamment volumineuse.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
-- En 9.6, il est nécessaire de configurer le paramètre
-- max_parallel_workers_per_gather à une valeur supérieur à 0.
-- Par exemple :
-- SET max_parallel_workers_per_gather TO 5;
-- Plan d'exécution parallélisé
EXPLAIN SELECT * FROM employes_big WHERE num_service <> 4;
QUERY PLAN
-------------------------------------------------------------------------------
Gather (cost=1000.00..8263.14 rows=1 width=41)
Workers Planned: 2
-> Parallel Seq Scan on employes_big (cost=0.00..7263.04 rows=1 width=41)
Filter: (num_service <> 4)
(4 rows)
Ici, deux processus supplémentaires seront exécutés pour réaliser la requête. Dans le cas de ce type de parcours, chaque processus prend un bloc et traite toutes les lignes de ce bloc. Quand un processus a terminé de traiter son bloc, il regarde quel est le prochain bloc à traiter et le traite.
VI-H-3. Parcours d’index▲
- Index Scan.
- Index Only Scan.
- Bitmap Index Scan.
- Et leurs versions parallélisées.
-
Paramètres :
- random_page_cost, cpu_index_tuple_cost, effective_cache_size,
- min_parallel_index_scan_size (v10),
- enable_indexscan, enable_indexonlyscan, enable_bitmapscan.
PostgreSQL dispose de trois moyens d’accéder aux données à travers les index.
Le nœud Index Scan est le premier qui a été disponible. Il consiste à parcourir les blocs d’index jusqu’à trouver les pointeurs vers les blocs contenant les données. À chaque pointeur trouvé, PostgreSQL lit le bloc de la table pointé pour retrouver l’enregistrement et s’assurer notamment de sa visibilité pour la transaction en cours. De ce fait, il y a beaucoup d’accès non séquentiels pour lire l’index et la table.
2.
3.
4.
5.
6.
7.
8.
EXPLAIN SELECT * FROM employes_big WHERE matricule = 132;
QUERY PLAN
----------------------------------------------------
Index Scan using employes_big_pkey on employes_big
(cost=0.42..8.44 rows=1 width=41)
Index Cond: (matricule = 132)
(2 rows)
Ce type de nœud n’a d’intérêt que s’il y a très peu de lignes à récupérer, si le filtre est très sélectif. De plus, ce type de nœud ne permet pas d’extraire directement les données à retourner depuis l’index, sans passer par la lecture des blocs correspondants de la table. Le nœud Index Only Scan permet cette optimisation, à condition que les colonnes retournées fassent partie de l’index :
2.
3.
4.
5.
6.
7.
8.
EXPLAIN SELECT matricule FROM employes_big WHERE matricule < 132;
QUERY PLAN
---------------------------------------------------------
Index Only Scan using employes_big_pkey on employes_big
(cost=0.42..9.86 rows=82 width=4)
Index Cond: (matricule < 132)
(2 rows)
Mais pour que ce type de nœud soit efficace, il faut s’assurer que la table en relation soit fréquemment traitée par des opérations VACUUM. Enfin, on retrouve le dernier parcours sur des opérations de type range scan, c’est-à-dire où PostgreSQL doit retourner une plage de valeurs. On le retrouve également lorsque PostgreSQL doit combiner le résultat de la lecture de plusieurs index.
Contrairement à d’autres SGBD, un index bitmap n’a aucune existence sur disque. Il est créé en mémoire lorsque son utilisation a un intérêt. Le but est de diminuer les déplacements de la tête de lecture en découplant le parcours de l’index du parcours de la table :
- lecture en un bloc de l’index ;
- lecture en un bloc de la partie intéressante de la table (dans l’ordre physique de la table, pas dans l’ordre logique de l’index).
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
SET enable_indexscan TO off;
EXPLAIN
SELECT * FROM employes_big WHERE matricule between 200000 and 300000;
QUERY PLAN
-----------------------------------------------------------------------
Bitmap Heap Scan on employes_big
(cost=2108.46..8259.35 rows=99126 width=41)
Recheck Cond: ((matricule >= 200000) AND (matricule <= 300000))
-> Bitmap Index Scan on employes_big_pkey*
(cost=0.00..2083.68 rows=99126 width=0)
Index Cond: ((matricule >= 200000) AND (matricule <= 300000))
(4 rows)
RESET enable_indexscan;
On retrouve aussi des Bitmap Index Scan lorsqu’il s’agit de combiner le résultat de la lecture de plusieurs index :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
EXPLAIN
SELECT * FROM employes_big
WHERE matricule BETWEEN 1000 AND 100000
OR matricule BETWEEN 200000 AND 300000;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on employes_big
(cost=4265.09..12902.67 rows=178904 width=41)
Recheck Cond: (((matricule >= 1000) AND (matricule <= 100000))
OR ((matricule >= 200000) AND (matricule <= 300000)))
-> BitmapOr (cost=4265.09..4265.09 rows=198679 width=0)
-> Bitmap Index Scan on employes_big_pkey
(cost=0.00..2091.95 rows=99553 width=0)
Index Cond: ((matricule >= 1000) AND (matricule <= 100000))
-> Bitmap Index Scan on employes_big_pkey
(cost=0.00..2083.68 rows=99126 width=0)
Index Cond: ((matricule >= 200000) AND (matricule <= 300000))
(7 rows)
À partir de la version 10, une infrastructure a été mise en place pour permettre un parcours parallélisé d’un index. Cela donne donc les nœuds Parallel Index Scan, Parallel Index Only Scan et Parallel Bitmap Heap Scan. Cette infrastructure est actuellement uniquement utilisée pour les index Btree. Par contre, pour le bitmap scan, seul le parcours de la table est parallélisé, ce qui fait que tous les types d’index sont concernés. Un parcours parallélisé d’un index n’est considéré qu’à partir du moment où l’index a une taille supérieure à la valeur du paramètre min_parallel_index_scan_size (défaut : 512 ko).
VI-H-4. Autres parcours▲
- Function Scan.
- Values Scan.
On retrouve le nœud Function Scan lorsqu’une requête utilise directement le résultat d’une fonction. Par exemple, on le rencontre lorsqu’on utilise les fonctions d’informations système de PostgreSQL :
2.
3.
4.
5.
6.
EXPLAIN SELECT * from pg_get_keywords();
QUERY PLAN
-----------------------------------------------------------------------
Function Scan on pg_get_keywords (cost=0.03..4.03 rows=400 width=65)
(1 ligne)
On retrouve également d’autres types de parcours, mais PostgreSQL les utilise rarement. Ils sont néanmoins détaillés en annexe.
VI-H-5. Nœuds de jointure▲
-
PostgreSQL implémente les trois algorithmes de jointures habituels :
- Nested Loop (boucle imbriquée),
- Hash Join (hachage de la table interne),
- Merge Join (trifusion).
-
Parallélisation possible :
- Nested Loop et Hash Join (9.6+),
- Merge Join (10+).
-
Et pour EXISTS, IN et certaines jointures externes :
- Semi Join,
- Anti Join.
-
Paramètres :
- enable_nestloop, enable_hashjoin, enable_mergejoin.
Le choix du type de jointure dépend non seulement des données mises en œuvre, mais elle dépend également beaucoup du paramétrage de PostgreSQL, notamment des paramètres work_mem, seq_page_cost et random_page_cost.
La Nested Loop se retrouve principalement quand on joint de petits ensembles de données :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
EXPLAIN SELECT matricule, nom, prenom, nom_service, fonction, localisation
FROM employes emp
JOIN services ser ON (emp.num_service = ser.num_service)
WHERE ser.localisation = 'Nantes';
QUERY PLAN
--------------------------------------------------------------------
Nested Loop (cost=0.00..2.37 rows=4 width=45)
Join Filter: (emp.num_service = ser.num_service)
-> Seq Scan on services ser (cost=0.00..1.05 rows=1 width=21)
Filter: ((localisation)::text = 'Nantes'::text)
-> Seq Scan on employes emp (cost=0.00..1.14 rows=14 width=32)
(5 rows)
Le Hash Join se retrouve également lorsque l’ensemble de la table interne est très petit. L’optimiseur réalise alors un hachage des valeurs de la colonne de jointure sur la table externe. Il réalise ensuite une lecture de la table interne et compare les hachages de la clé de jointure avec le(s) hachage(s) obtenu(s) à la lecture de la table interne.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
EXPLAIN SELECT matricule, nom, prenom, nom_service, fonction, localisation
FROM employes_big emp
JOIN services ser ON (emp.num_service = ser.num_service);
QUERY PLAN
-------------------------------------------------------------------------------
Hash Join (cost=1.06..14848.09 rows=124754 width=46)
Hash Cond: (emp.num_service = ser.num_service)
-> Seq Scan on employes_big emp (cost=0.00..9654.15 rows=499015 width=33)
-> Hash (cost=1.05..1.05 rows=1 width=21)
-> Seq Scan on services ser (cost=0.00..1.05 rows=1 width=21)
Filter: ((localisation)::text = 'Nantes'::text)
(6 rows)
La jointure par trifusion, ou Merge Join, prend deux ensembles de données triés en entrée et restitue l’ensemble de données après jointure. Cette jointure est assez lourde à initialiser si PostgreSQL ne peut pas utiliser d’index, mais elle a l’avantage de retourner les données triées directement :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
EXPLAIN
SELECT matricule, nom, prenom, nom_service, fonction, localisation
FROM employes_big emp
JOIN services ser ON (emp.num_service = ser.num_service)
ORDER BY ser.num_service;
QUERY PLAN
-------------------------------------------------------------------------
Merge Join (cost=0.55..23886.23 rows=499015 width=49)
Merge Cond: (emp.num_service = ser.num_service)
-> Index Scan using employes_big_num_service_idx on employes_big emp
(cost=0.42..17636.65 rows=499015 width=32)
-> Index Scan using services_pkey on services ser
(cost=0.13..12.19 rows=4 width=21)
(4 rows)
Il s’agit d’un algorithme de jointure particulièrement efficace pour traiter les volumes de données importants, surtout si les données sont prétriées (grâce à l’existence d’un index).
Les clauses EXISTS et NOT EXISTS mettent également en œuvre des algorithmes dérivés de semi et anti-jointures. En voici un exemple avec la clause EXISTS :
EXPLAIN
SELECT *
FROM services s
WHERE EXISTS (SELECT 1
FROM employes_big e
WHERE e.date_embauche>s.date_creation
AND s.num_service = e.num_service);
QUERY PLAN
-----------------------------------------------------------------
Hash Semi Join (cost=17841.84..19794.91 rows=1 width=25)
Hash Cond: (s.num_service = e.num_service)
Join Filter: (e.date_embauche > s.date_creation)
-> Seq Scan on services s (cost=0.00..1.04 rows=4 width=25)
-> Hash (cost=9654.15..9654.15 rows=499015 width=8)
-> Seq Scan on employes_big e
(cost=0.00..9654.15 rows=499015 width=8)
(6 rows)On obtient un plan sensiblement identique, avec NOT EXISTS. Le nœud Hash Semi Join est remplacé par Hash Anti Join :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
EXPLAIN
SELECT *
FROM services s
WHERE NOT EXISTS (SELECT 1
FROM employes_big e
WHERE e.date_embauche>s.date_creation
AND s.num_service = e.num_service);
QUERY PLAN
-----------------------------------------------------------------
Hash Anti Join (cost=17841.84..19794.93 rows=3 width=25)
Hash Cond: (s.num_service = e.num_service)
Join Filter: (e.date_embauche > s.date_creation)
-> Seq Scan on services s (cost=0.00..1.04 rows=4 width=25)
-> Hash (cost=9654.15..9654.15 rows=499015 width=8)
-> Seq Scan on employes_big e
(cost=0.00..9654.15 rows=499015 width=8)
(6 rows)
PostgreSQL dispose de la parallélisation depuis la version 9.6. Cela ne concernait que les jointures de type Nested Loop et Hash Join. Il a fallu attendre la version 10 pour que la parallélisation soit supportée aussi par le Merge Join.
VI-H-6. Nœuds de tris et de regroupements▲
-
Un seul nœud de tri :
- Sort.
-
Regroupement/Agrégation :
- Aggregate,
- Hash Aggregate,
- Group Aggregate,
- Mixed Aggregate (10+),
- Partial/Finalize Aggregate (9.6+).
-
Paramètres :
- enable_hashagg.
Pour réaliser un tri, PostgreSQL ne dispose que d’un seul nœud pour réaliser cela : Sort. Son efficacité va dépendre du paramètre work_mem qui va définir la quantité de mémoire que PostgreSQL pourra utiliser pour un tri.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
EXPLAIN (ANALYZE)
SELECT * FROM employes ORDER BY fonction;
QUERY PLAN
----------------------------------------------------------------
Sort (cost=1.41..1.44 rows=14 width=43)
(actual time=0.013..0.014 rows=14 loops=1)
Sort Key: fonction
Sort Method: quicksort Memory: 26kB
-> Seq Scan on employes (cost=0.00..1.14 rows=14 width=43)
(actual time=0.003..0.004 rows=14 loops=1)
Planning time: 0.021 ms
Execution time: 0.021 ms
(6 rows)
Si le tri ne tient pas en mémoire, l’algorithme de tri gère automatiquement le débordement sur disque :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
EXPLAIN (ANALYZE)
SELECT * FROM employes_big ORDER BY fonction;
QUERY PLAN
---------------------------------------------------------------------------
Sort (cost=70529.24..71776.77 rows=499015 width=40)
(actual time=252.827..298.948 rows=499015 loops=1)
Sort Key: fonction
Sort Method: external sort Disk: 26368kB
-> Seq Scan on employes_big (cost=0.00..9654.15 rows=499015 width=40)
(actual time=0.003..29.012 rows=499015 loops=1)
Planning time: 0.021 ms
Execution time: 319.283 ms
(6 rows)
Cependant, si un index existe, PostgreSQL peut également utiliser un index pour récupérer les données triées directement :
2.
3.
4.
5.
6.
7.
EXPLAIN SELECT * FROM employes_big ORDER BY matricule;
QUERY PLAN
----------------------------------------------
Index Scan using employes_pkey on employes
(cost=0.42..17636.65 rows=499015 width=41)
(1 row)
Dans n’importe quel ordre de tri :
2.
3.
4.
5.
6.
7.
EXPLAIN SELECT * FROM employes_big ORDER BY matricule DESC;
QUERY PLAN
-----------------------------------------------------
Index Scan Backward using employes_pkey on employes
(cost=0.42..17636.65 rows=499015 width=41)
(1 row)
Le choix du type d’opération de regroupement dépend non seulement des données mises en œuvre, mais elle dépend également beaucoup du paramétrage de PostgreSQL, notamment du paramètre work_mem.
Concernant les opérations d’agrégations, on retrouve un nœud de type Aggregate lorsque la requête réalise une opération d’agrégation simple, sans regroupement :
2.
3.
4.
5.
6.
7.
EXPLAIN SELECT count(*) FROM employes;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=1.18..1.19 rows=1 width=8)
-> Seq Scan on employes (cost=0.00..1.14 rows=14 width=0)
(2 rows)
Si l’optimiseur estime que l’opération d’agrégation tient en mémoire (paramètre work_mem), il va utiliser un nœud de type HashAggregate :
2.
3.
4.
5.
6.
7.
8.
EXPLAIN SELECT fonction, count(*) FROM employes GROUP BY fonction;
QUERY PLAN
----------------------------------------------------------------
HashAggregate (cost=1.21..1.27 rows=6 width=20)
Group Key: fonction
-> Seq Scan on employes (cost=0.00..1.14 rows=14 width=12)
(3 rows)
L’inconvénient de ce nœud est que sa consommation mémoire n’est pas limitée par work_mem, il continuera malgré tout à allouer de la mémoire. Dans certains cas, heureusement très rares, l’optimiseur peut se tromper suffisamment pour qu’un nœud HashAggregate consomme plusieurs gigaoctets de mémoire et sature la mémoire du serveur.
Lorsque l’optimiseur estime que le volume de données à traiter ne tient pas dans work_mem ou quand il peut accéder aux données prétriées, il utilise plutôt l’algorithme GroupAggregate :
2.
3.
4.
5.
6.
7.
8.
9.
EXPLAIN SELECT matricule, count(*) FROM employes_big GROUP BY matricule;
QUERY PLAN
---------------------------------------------------------------
GroupAggregate (cost=0.42..20454.87 rows=499015 width=12)
Group Key: matricule
-> Index Only Scan using employes_big_pkey on employes_big
(cost=0.42..12969.65 rows=499015 width=4)
(3 rows)
La version 10 apporte un autre nœud d’agrégats : le Mixed Aggregate, beaucoup plus efficace pour les clauses GROUP BY GROUPING SETS ou GROUP BY CUBE grâce à l’utilisation de hashs:
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
EXPLAIN (ANALYZE,buffers)
SELECT manager, fonction, num_service, COUNT(*)
FROM employes_big
GROUP BY CUBE(manager,fonction,num_service) ;
QUERY PLAN
---------------------------------------------------------------
MixedAggregate (cost=0.00..34605.17 rows=27 width=27)
(actual time=581.562..581.573 rows=51 loops=1)
Hash Key: manager, fonction, num_service
Hash Key: manager, fonction
Hash Key: manager
Hash Key: fonction, num_service
Hash Key: fonction
Hash Key: num_service, manager
Hash Key: num_service
Group Key: ()
Buffers: shared hit=4664
-> Seq Scan on employes_big (cost=0.00..9654.15 rows=499015 width=19)
(actual time=0.015..35.840 rows=499015 loops=1)
Buffers: shared hit=4664
Planning time: 0.223 ms
Execution time: 581.671 ms
(Comparez avec le plan et le temps obtenus auparavant, que l’on peut retrouver avec SET enable_hashagg TO off;).
Le calcul d’un agrégat peut être parallélisé à partir de la version 9.6. Dans ce cas, deux nœuds sont utilisés : un pour le calcul partiel de chaque processus (Partial Aggregate), et un pour le calcul final (Finalize Aggregate). Voici un exemple de plan :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
EXPLAIN (ANALYZE,COSTS OFF)
SELECT date_embauche, count(*), min(date_embauche), max(date_embauche)
FROM employes_big
GROUP BY date_embauche;
QUERY PLAN
-------------------------------------------------------------------------
Finalize GroupAggregate (actual time=92.736..92.740 rows=7 loops=1)
Group Key: date_embauche
-> Sort (actual time=92.732..92.732 rows=9 loops=1)
Sort Key: date_embauche
Sort Method: quicksort Memory: 25kB
-> Gather (actual time=92.664..92.673 rows=9 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Partial HashAggregate
(actual time=89.531..89.532 rows=3 loops=3)
Group Key: date_embauche
-> Parallel Seq Scan on employes_big
(actual time=0.011..35.801 rows=166338 loops=3)
Planning time: 0.127 ms
Execution time: 95.601 ms
(13 rows)
(8 rows)
VI-H-7. Les autres nœuds▲
- Limit.
- Unique.
- Append (UNION ALL), Except, Intersect.
- Gather.
- InitPlan, Subplan, etc.
On rencontre le nœud Limit lorsqu’on limite le résultat avec l’ordre LIMIT :
2.
3.
4.
5.
6.
7.
EXPLAIN SELECT * FROM employes_big LIMIT 1;
QUERY PLAN
---------------------------------------------------------------------------
Limit (cost=0.00..0.02 rows=1 width=40)
-> Seq Scan on employes_big (cost=0.00..9654.15 rows=499015 width=40)
(2 rows)
À noter, que le nœud Sort utilisera dans ce cas une méthode de tri appelée top-N heapsort qui permet d’optimiser le tri pour retourner les n premières lignes :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
EXPLAIN ANALYZE
SELECT * FROM employes_big ORDER BY fonction LIMIT 5;
QUERY PLAN
-------------------------------------------------------------
Limit (cost=17942.61..17942.62 rows=5 width=40)
(actual time=80.359..80.360 rows=5 loops=1)
-> Sort (cost=17942.61..19190.15 rows=499015 width=40)
(actual time=80.358..80.359 rows=5 loops=1)
Sort Key: fonction
Sort Method: top-N heapsort Memory: 25kB
-> Seq Scan on employes_big
(cost=0.00..9654.15 rows=499015 width=40)
(actual time=0.005..27.506 rows=499015 loops=1)
Planning time: 0.035 ms
Execution time: 80.375 ms
(7 rows)
On retrouve le nœud Unique lorsque l’on utilise DISTINCT pour dédoublonner le résultat d’une requête :
2.
3.
4.
5.
6.
7.
8.
EXPLAIN SELECT DISTINCT matricule FROM employes_big;
QUERY PLAN
---------------------------------------------------------------
Unique (cost=0.42..14217.19 rows=499015 width=4)
-> Index Only Scan using employes_big_pkey on employes_big
(cost=0.42..12969.65 rows=499015 width=4)
(2 rows)
On le verra plus loin, il est souvent plus efficace d’utiliser GROUP BY pour dédoublonner les résultats d’une requête.
Les nœuds Append, Except et Intersect se rencontrent lorsqu’on utilise les opérateurs ensemblistes UNION, EXCEPT et INTERSECT. Par exemple, avec UNION ALL :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
EXPLAIN
SELECT * FROM employes
WHERE num_service = 2
UNION ALL
SELECT * FROM employes
WHERE num_service = 4;
QUERY PLAN
--------------------------------------------------------------------------
Append (cost=0.00..2.43 rows=8 width=43)
-> Seq Scan on employes (cost=0.00..1.18 rows=3 width=43)
Filter: (num_service = 2)
-> Seq Scan on employes employes_1 (cost=0.00..1.18 rows=5 width=43)
Filter: (num_service = 4)
Le nœud InitPlan apparaît lorsque PostgreSQL a besoin d’exécuter une première sous-requête pour ensuite exécuter le reste de la requête. Il est assez rare :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
EXPLAIN
SELECT *,
(SELECT nom_service FROM services WHERE num_service=1)
FROM employes WHERE num_service = 1;
QUERY PLAN
----------------------------------------------------------------
Seq Scan on employes (cost=1.05..2.23 rows=2 width=101)
Filter: (num_service = 1)
InitPlan 1 (returns $0)
-> Seq Scan on services (cost=0.00..1.05 rows=1 width=10)
Filter: (num_service = 1)
(5 rows)
Le nœud SubPlan est utilisé lorsque PostgreSQL a besoin d’exécuter une sous-requête pour filtrer les données :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
EXPLAIN
SELECT * FROM employes
WHERE num_service NOT IN (SELECT num_service FROM services
WHERE nom_service = 'Consultants');
QUERY PLAN
----------------------------------------------------------------
Seq Scan on employes (cost=1.05..2.23 rows=7 width=43)
Filter: (NOT (hashed SubPlan 1))
SubPlan 1
-> Seq Scan on services (cost=0.00..1.05 rows=1 width=4)
Filter: ((nom_service)::text = 'Consultants'::text)
(5 rows)
Le nœud Gather a été introduit en version 9.6 et est utilisé comme nœud de rassemblement des données pour les plans parallélisés.
D’autres types de nœuds peuvent également être trouvés dans les plans d’exécution. L’annexe décrit tous ces nœuds en détail.
VI-I. Problèmes les plus courants▲
-
L’optimiseur se trompe parfois :
- mauvaises statistiques,
- écriture particulière de la requête,
- problèmes connus de l’optimiseur.
L’optimiseur de PostgreSQL est sans doute la partie la plus complexe de PostgreSQL. Il se trompe rarement, mais certains facteurs peuvent entraîner des temps d’exécution très lents, voire catastrophiques de certaines requêtes.
VI-I-1. Colonnes corrélées▲
SELECT * FROM t1 WHERE c1=1 AND c2=1
- c1=1 est vrai pour 20 % des lignes.
- c2=1 est vrai pour 10 % des lignes.
- Le planificateur va penser que le résultat complet ne récupérera que 20 % * 10 % (soit 2 %) des lignes.
- En réalité, ça peut aller de 0 à 10 % des lignes.
-
Problème corrigé en version 10 :
- CREATE STATISTICS pour des statistiques multicolonnes.
PostgreSQL conserve des statistiques par colonne simple. Dans l’exemple ci-dessus, le planificateur sait que l’estimation pour c1=1 est de 20 % et que l’estimation pour c2=1 est de 10 %. Par contre, il n’a aucune idée de l’estimation pour c1=1 AND c2=1. En réalité, l’estimation pour cette formule va de 0 à 10 %, mais le planificateur doit statuer sur une seule valeur. Ce sera le résultat de la multiplication des deux estimations, soit 2 % (20 % * 10 %).
La version 10 de PostgreSQL corrige cela en apportant la possibilité d’ajouter des statistiques sur plusieurs colonnes spécifiques. Ce n’est pas automatique, il faut créer un objet statistique avec l’ordre CREATE STATISTICS.
VI-I-2. Mauvaise écriture de prédicats▲
2.
3.
SELECT *
FROM commandes
WHERE extract('year' from date_commande) = 2014;
- L’optimiseur n’a pas de statistiques sur le résultat de la fonction extract.
- Il estime la sélectivité du prédicat à 0,5 %.
Dans un prédicat, lorsque les valeurs des colonnes sont transformées par un calcul ou par une fonction, l’optimiseur n’a aucun moyen pour connaître la sélectivité d’un prédicat. Il utilise donc une estimation codée en dur dans le code de l’optimiseur : 0,5 % du nombre de lignes de la table.
Dans la requête suivante, l’optimiseur estime que la requête va ramener 2495 lignes :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
EXPLAIN
SELECT * FROM employes_big
WHERE extract('year' from date_embauche) = 2006;
QUERY PLAN
---------------------------------------------------------------
Gather (cost=1000.00..9552.15 rows=2495 width=40)
Workers Planned: 2
-> Parallel Seq Scan on employes_big
(cost=0.00..8302.65 rows=1040 width=40)
Filter: (date_part('year'::text,
(date_embauche)::timestamp without time zone)
= '2006'::double precision)
(4 rows)
Ces 2495 lignes correspondent à 0,5 % de la table commandes :
2.
3.
4.
5.
6.
7.
8.
SELECT relname, reltuples, round(reltuples*0.005) AS estimé
FROM pg_class
WHERE relname = 'employes_big';
relname | reltuples | estimé
--------------+-----------+--------
employes_big | 499015 | 2495
(1 row)
VI-I-3. Problème avec LIKE▲
SELECT * FROM t1 WHERE c2 LIKE 'x%';
- PostgreSQL peut utiliser un index dans ce cas.
-
Si l’encodage n’est pas C :
- déclarer l’index avec une classe d’opérateur,
- varchar_pattern_ops, text_pattern_ops, etc.
- Attention au collationnement en 9.1+.
- Ne pas oublier pg_trgm (9.1+) et FTS.
Dans le cas d’une recherche avec préfixe, PostgreSQL peut utiliser un index sur la colonne. Il existe cependant une spécificité à PostgreSQL. Si l’encodage est autre chose que C, il faut utiliser une classe d’opérateur lors de la création de l’index. Cela donnera par exemple :
CREATE INDEX i1 ON t1 (c2 varchar_pattern_ops);
De plus, à partir de la version 9.1, il est important de faire attention au collationnement. Si le collationnement de la requête diffère du collationnement de la colonne de l’index, l’index ne pourra pas être utilisé.
VI-I-4. DELETE lent▲
- DELETE lent.
- Généralement un problème de clé étrangère.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
Delete (actual time=111.251..111.251 rows=0 loops=1)
-> Hash Join (actual time=1.094..21.402 rows=9347 loops=1)
-> Seq Scan on lot_a30_descr_lot
(actual time=0.007..11.248 rows=34934 loops=1)
-> Hash (actual time=0.501..0.501 rows=561 loops=1)
-> Bitmap Heap Scan on lot_a10_pdl
(actual time=0.121..0.326 rows=561 loops=1)
Recheck Cond: (id_fantoir_commune = 320013)
-> Bitmap Index Scan on...
(actual time=0.101..0.101 rows=561 loops=1)
Index Cond: (id_fantoir_commune = 320013)
Trigger for constraint fk_lotlocal_lota30descrlot:
time=1010.358 calls=9347
Trigger for constraint fk_nonbatia21descrsuf_lota30descrlot:
time=2311695.025 calls=9347
Total runtime: 2312835.032 ms
Parfois, un DELETE peut prendre beaucoup de temps à s’exécuter. Cela peut être dû à un grand nombre de lignes à supprimer. Cela peut aussi être dû à la vérification des contraintes étrangères.
Dans l’exemple ci-dessus, le DELETE met 38 minutes à s’exécuter (2 312 835 ms), pour ne supprimer aucune ligne. En fait, c’est la vérification de la contrainte fk_nonbatia21descrsuf_lota30descrlot qui prend pratiquement tout le temps. C’est d’ailleurs pour cette raison qu’il est recommandé de positionner des index sur les clés étrangères, car cet index permet d’accélérer la recherche liée à la contrainte.
Attention donc aux contraintes de clés étrangères pour les instructions DML.
VI-I-5. Dédoublonnage▲
SELECT DISTINCT t1.* FROM t1 JOIN t2 ON (t1.id=t2.t1_id);
-
DISTINCT est souvent utilisé pour dédoublonner les lignes :
- mais génère un tri qui pénalise les performances.
- GROUP BY est plus rapide.
-
Une clé primaire permet de dédoublonner efficacement des lignes :
- à utiliser avec GROUP BY.
L’exemple ci-dessous montre une requête qui récupère les commandes qui ont des lignes de commandes et réalise le dédoublonnage avec DISTINCT. Le plan d’exécution montre une opération de tri qui a nécessité un fichier temporaire sur disque. Toutes ces opérations sont assez gourmandes :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
EXPLAIN (ANALYZE on, COSTS off)
SELECT DISTINCT employes_big.*
FROM employes_big
JOIN services USING (num_service);
QUERY PLAN
----------------------------------------------------------------------------
Unique (actual time=376.232..555.422 rows=499015 loops=1)
-> Sort (actual time=376.231..414.852 rows=499015 loops=1)
Sort Key: employes_big.matricule, employes_big.nom,
employes_big.prenom, employes_big.fonction,
employes_big.manager, employes_big.date_embauche,
employes_big.num_service
Sort Method: external sort Disk: 26368kB
-> Hash Join (actual time=0.015..137.162 rows=499015 loops=1)
Hash Cond: (employes_big.num_service = services.num_service)
-> Seq Scan on employes_big
(actual time=0.005..30.420 rows=499015 loops=1)
-> Hash (actual time=0.005..0.005 rows=4 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on services
(actual time=0.002..0.003 rows=4 loops=1)
Planning time: 0.203 ms
Execution time: 575.625 ms
(12 rows)
En utilisant GROUP BY au lieu du DISTINCT, le temps d’exécution est plus bas, il faut juste donner explicitement les colonnes. Ici il n’y a pas de tri.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
EXPLAIN (ANALYZE on, COSTS off)
SELECT employes_big.*
FROM employes_big
JOIN services USING (num_service)
GROUP BY employes_big.matricule, employes_big.nom, employes_big.prenom,
employes_big.fonction, employes_big.manager,
employes_big.date_embauche, employes_big.num_service;
QUERY PLAN
------------------------------------------------------------------------
Group (actual time=0.014..450.730 rows=499015 loops=1)
Group Key: employes_big.matricule
-> Nested Loop (actual time=0.013..326.207 rows=499015 loops=1)
Join Filter: (employes_big.num_service = services.num_service)
Rows Removed by Join Filter: 1497029
-> Index Scan using employes_big_pkey on employes_big
(actual time=0.007..64.275 rows=499015 loops=1)
-> Materialize (actual time=0.000..0.000 rows=4 loops=499015)
-> Seq Scan on services
(actual time=0.003..0.003 rows=4 loops=1)
Planning time: 0.179 ms
Execution time: 465.314 ms
(10 rows)
Noter que PostgreSQL est assez malin pour ne faire le tri que sur les colonnes correspondant à la clé primaire (ici, matricule). Dans certains cas,n il utilisera le parallélisme.
Pour aller plus loin, n’hésitez pas à consulter cet article de blog.
VI-I-6. Index inutilisés▲
- Trop de lignes retournées.
- Prédicat incluant une transformation.
WHEREcol1+2>5.- Statistiques pas à jour ou peu précises.
- Opérateur non supporté par l’index.
WHEREcol1<>'valeur';.- Paramétrage de PostgreSQL : effective_cache_size.
PostgreSQL offre de nombreuses possibilités d’indexation des données :
- Type d’index : B-tree, GiST, GIN, SP-GiST, BRIN et hash.
- Index multicolonnes :
CREATEINDEX...ON(col1, col2...);. - Index partiel :
CREATEINDEX...WHEREcolonne=valeur. - Extension offrant des fonctionnalités supplémentaires : pg_trgm.
- Index fonctionnel :
CREATEINDEX...ON(fonction(colonne)).
Malgré toutes ces possibilités, une question revient souvent lorsqu’un index vient d’être ajouté : pourquoi cet index n’est-il pas utilisé ?
L’optimiseur de PostgreSQL est très avancé et il y a peu de cas où il est mis en défaut. Malgré cela, certains index ne sont pas utilisés comme on le souhaiterait. Il peut y avoir plusieurs raisons à cela.
Problèmes de statistiques
Le cas le plus fréquent concerne les statistiques qui ne sont pas à jour. Cela arrive souvent après le chargement massif d’une table ou une mise à jour massive sans avoir fait une nouvelle collecte des statistiques à l’issue de ces changements.
On utilisera l’ordre ANALYZE table pour déclencher explicitement la collecte des statistiques après un tel traitement. En effet, bien qu’autovacuum soit présent, il peut se passer un certain temps entre le moment où le traitement est fait et le moment où autovacuum déclenche une collecte de statistiques. Ou autovacuum peut simplement ne pas se déclencher, car le traitement complet est imbriqué dans une seule transaction.
Un traitement batch devra comporter des ordres ANALYZE juste après les ordres SQL qui modifient fortement les données :
2.
3.
COPY table_travail FROM '/tmp/fichier.csv';
ANALYZE table_travail;
SELECT ... FROM table_travail;
Un autre problème qui peut se poser avec les statistiques concerne les tables de très forte volumétrie. Dans certains cas, l’échantillon de données ramené par ANALYZE n’est pas assez précis pour donner à l’optimiseur de PostgreSQL une vision suffisamment précise des données. Il choisira alors de mauvais plans d’exécution.
Il est possible d’augmenter la précision de l’échantillon de données ramené à l’aide de l’ordre :
ALTER TABLE ... ALTER COLUMN ... SET STATISTICS ...;
Problèmes de prédicats
Dans d’autres cas, les prédicats d’une requête ne permettent pas à l’optimiseur de choisir un index pour répondre à une requête. C’est le cas lorsque le prédicat inclut une transformation de la valeur d’une colonne.
L’exemple suivant est assez naïf, mais démontre bien le problème :
SELECT * FROM employes WHERE date_embauche + interval '1 month' = '2006-01-01';Avec une telle construction, l’optimiseur ne saura pas tirer partie d’un quelconque index, à moins d’avoir créé un index fonctionnel sur col1 + 10, mais cet index est largement contre-productif par rapport à une réécriture de la requête.
Ce genre de problème se rencontre plus souvent avec des prédicats sur des dates :
SELECT * FROM employes WHERE date_trunc('month', date_embauche) = 12;
ou encore plus fréquemment rencontré :
SELECT * FROM employes WHERE extract('year' from date_embauche) = 2006;
SELECT * FROM employes WHERE upper(prenom) = 'GASTON';Opérateurs non supportés
Les index B-tree supportent la plupart des opérateurs généraux sur les variables scalaires (entiers, chaînes, dates, mais pas types composés comme géométries, hstore…), mais pas la différence (<> ou !=). Par nature, il n’est pas possible d’utiliser un index pour déterminer toutes les valeurs sauf une. Mais ce type de construction est parfois utilisé pour exclure les valeurs les plus fréquentes d’une colonne. Dans ce cas, il est possible d’utiliser un index partiel qui, en plus, sera très petit, car il n’indexera qu’une faible quantité de données par rapport à la totalité de la table :
2.
3.
4.
5.
6.
7.
8.
9.
EXPLAIN SELECT * FROM employes_big WHERE num_service<>4;
QUERY PLAN
-------------------------------------------------------------------------------
Gather (cost=1000.00..8264.74 rows=17 width=41)
Workers Planned: 2
-> Parallel Seq Scan on employes_big (cost=0.00..7263.04 rows=7 width=41)
Filter: (num_service <> 4)
(4 rows)
La création d’un index partiel permet d’en tirer partie :
2.
3.
4.
5.
6.
7.
8.
9.
CREATE INDEX ON employes_big(num_service) WHERE num_service<>4;
EXPLAIN SELECT * FROM employes_big WHERE num_service<>4;
QUERY PLAN
----------------------------------------------------------------
Index Scan using employes_big_num_service_idx1 on employes_big
(cost=0.14..12.35 rows=17 width=40)
(1 row)
Paramétrage de PostgreSQL
Plusieurs paramètres de PostgreSQL influencent l’optimiseur sur l’utilisation ou non d’un index :
- random_page_cost : indique à PostgreSQL la vitesse d’un accès aléatoire par rapport à un accès séquentiel (seq_page_cost) ;
- effective_cache_size : indique à PostgreSQL une estimation de la taille du cache disque du système.
Le paramètre random_page_cost a une grande influence sur l’utilisation des index en général. Il indique à PostgreSQL le coût d’un accès disque aléatoire. Il est à comparer au paramètre seq_page_cost qui indique à PostgreSQL le coût d’un accès disque séquentiel. Ces coûts d’accès sont purement arbitraires et n’ont aucune réalité physique.
Dans sa configuration par défaut, PostgreSQL estime qu’un accès aléatoire est quatre fois plus coûteux qu’un accès séquentiel. Les accès aux index étant par nature aléatoires alors que les parcours de table sont par nature séquentiels, modifier ce paramètre revient à favoriser l’un par rapport à l’autre. Cette valeur est bonne dans la plupart des cas. Mais si le serveur de bases de données dispose d’un système disque rapide, c’est-à-dire une bonne carte RAID et plusieurs disques SAS rapides en RAID10, ou du SSD, il est possible de baisser ce paramètre à 3, voire 2.
Enfin, le paramètre effective_cache_size indique à PostgreSQL une estimation de la taille du cache disque du système (total du shared buffers et du cache du système). Une bonne pratique est de positionner ce paramètre à 2/3 de la quantité totale de RAM du serveur. Sur un système Linux, il est possible de donner une estimation plus précise en s’appuyant sur la valeur de colonne cached de la commande free. Mais si le cache n’est que peu utilisé, la valeur trouvée peut être trop basse pour pleinement favoriser l’utilisation des index.
Pour aller plus loin, n’hésitez pas à consulter cet article de blog,
VI-I-7. Écriture du SQL▲
-
NOT IN avec une sous-requête :
- à remplacer par NOT EXISTS .
-
Utilisation systématique de UNION au lieu de UNION ALL :
- entraîne un tri systématique .
-
Sous-requête dans le SELECT :
- utiliser LATERAL .
La façon dont une requête SQL est écrite peut aussi avoir un effet négatif sur les performances. Il n’est pas possible d’écrire tous les cas possibles, mais certaines formes d’écritures reviennent souvent.
La clause NOT IN n’est pas performante lorsqu’elle est utilisée avec une sous-requête. L’optimiseur ne parvient pas à exécuter ce type de requête efficacement.
2.
3.
4.
SELECT *
FROM services
WHERE num_service NOT IN (SELECT num_service
FROM employes_big);
Il est nécessaire de la réécrire avec la clause NOT EXISTS, par exemple :
2.
3.
4.
5.
SELECT *
FROM services s
WHERE NOT EXISTS (SELECT 1
FROM employes_big e
WHERE s.num_service = e.num_service);
VI-J. Outils▲
- pgAdmin.
- OmniDB.
- explain.depesz.com.
- pev.
- auto_explain.
- plantuner.
- hypopg.
Il existe quelques outils intéressants dans le cadre du planificateur : deux applications externes pour mieux appréhender un plan d’exécution, deux modules pour changer le comportement du planificateur.
VI-J-1. pgAdmin▲
- Vision graphique d’un EXPLAIN.
- Une icône par nœud.
- La taille des flèches dépend de la quantité de données.
- Le détail de chaque nœud est affiché en survolant les nœuds.
pgAdmin propose depuis très longtemps un affichage graphique de l’EXPLAIN. Cet affichage est intéressant, car il montre simplement l’ordre dans lequel les opérations sont effectuées. Chaque nœud est représenté par une icône. Les flèches entre chaque nœud indiquent où sont envoyés les flux de données, la taille de la flèche précisant la volumétrie des données.
Les statistiques ne sont affichées qu’en survolant les nœuds.
VI-J-2. pgAdmin - copie d’écran▲
|
|
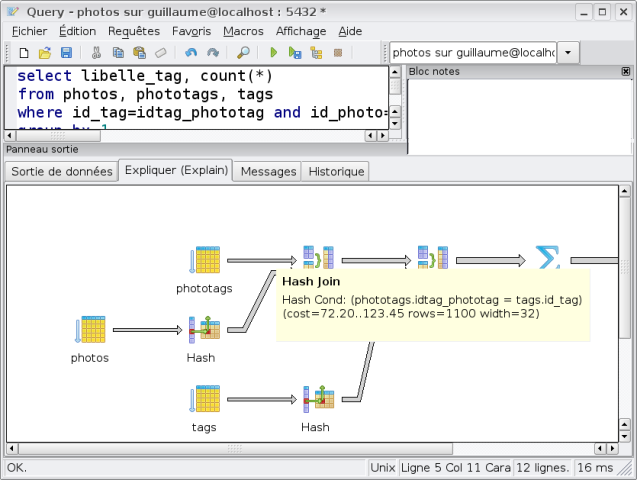
Voici un exemple d’un EXPLAIN graphique réalisé par pgAdmin 3. En passant la souris sur les nœuds, un message affiche les informations statistiques sur le nœud.
pgAdmin 4 dispose aussi d’un tel système.
VI-J-3. OmniDB▲
- Vision graphique d’un EXPLAIN.
- Un affichage textuel amélioré.
-
Deux affichages graphiques sous forme d’arbre :
- pas de détail de chaque nœud,
- taille du nœud dépendante du coût.
OmniDB est un outil d’administration pour PostgreSQL assez récent. Depuis sa version 2.2, il propose un affichage graphique de l’EXPLAIN. Cet affichage est intéressant, car il montre simplement l’ordre dans lequel les opérations sont effectuées. Chaque nœud est représenté par un élément de l’arbre. Les flèches entre chaque nœud indiquent où sont envoyés les flux de données, la taille du nœud dépendant de son coût.
Malheureusement, pour l’instant, les statistiques ne sont pas affichées.
L’affichage texte a un petit plus (une colorisation) permettant de trouver rapidement le nœud le plus coûteux.
VI-J-4. OmniDB - copie d’écran 1▲
|
|
Voici un exemple d’un EXPLAIN texte réalisé par OmniDB. Le fond coloré permet de déduire rapidement que le nœud Sort est le plus coûteux.
VI-J-5. OmniDB - copie d’écran 2▲
|
|
Ceci est le premier affichage graphique disponible avec OmniDB. Il s’agit d’une représentation sous la forme d’un arbre, un peu comme pgAdmin, les icônes en moins, la taille du nœud en plus.
VI-J-6. OmniDB - copie d’écran 3▲
|
|
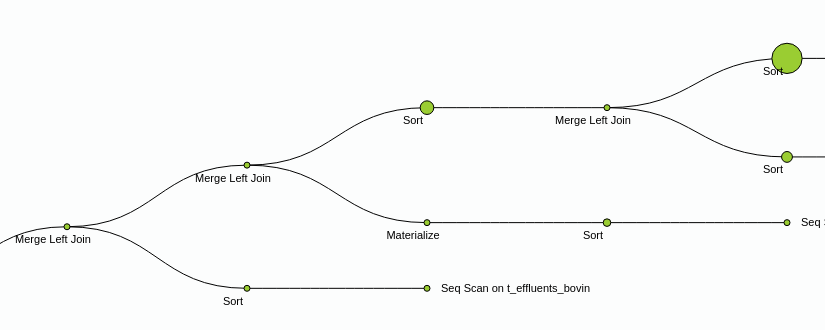
Ceci est le deuxième affichage graphique disponible avec OmniDB. Il s’agit d’une représentation sous la forme d’un arbre, un peu comme pgAdmin, les icônes en moins, la taille du nœud en plus.
VI-J-7. Site explain.depesz.com▲
- Site web proposant un affichage particulier du EXPLAIN ANALYZE.
- Il ne travaille que sur les informations réelles.
-
Les lignes sont colorées pour indiquer les problèmes :
- blanc, tout va bien,
- jaune, inquiétant,
- marron, plus inquiétant,
- rouge, très inquiétant.
- Installable en local
Hubert Lubaczewski est un contributeur très connu dans la communauté PostgreSQL. Il publie notamment un grand nombre d’articles sur les nouveautés des prochaines versions. Cependant, il est aussi connu pour avoir créé un site web d’analyse des plans d’exécution. Ce site web est disponible à cette adresse.
Il suffit d’aller sur ce site, de coller le résultat d’un EXPLAIN ANALYZE, et le site affichera le plan d’exécution avec des codes couleurs pour bien distinguer les nœuds performants des autres.
Le code couleur est simple :
- Blanc, tout va bien.
- Jaune, inquiétant.
- Marron, plus inquiétant.
- Rouge, très inquiétant.
Plutôt que d’utiliser ce serveur web, il est possible d’installer ce site en local :
VI-J-8. explain.depesz.com - copie d’écran▲
|
|
Cet exemple montre un affichage d’un plan sur le site explain.depesz.com.
Voici la signification des différentes colonnes :
- Exclusive : durée passée exclusivement sur un nœud ;
- Inclusive : durée passée sur un nœud et ses fils ;
- Rows x : facteur d’échelle de l’erreur d’estimation du nombre de lignes ;
- Rows : nombre de lignes renvoyées ;
- Loops : nombre de boucles.
Sur une exécution de 600 ms, un tiers est passé à lire la table avec un parcours séquentiel.
VI-J-9. Site pev▲
-
Site web proposant un affichage particulier du EXPLAIN ANALYZE :
- mais différent de celui de Depesz .
- Fournir un plan d’exécution en JSON.
- Installable en local.
PEV est un outil librement téléchargeable sur ce dépôt github. Il offre un affichage graphique du plan d’exécution et indique le nœud le plus coûteux, le plus long, le plus volumineux, etc.
Il est utilisable sur internet, mais est aussi installable en local.
VI-J-10. pev - copie d’écran▲
|
|
VI-J-11. Extension auto_explain▲
- Extension officielle PostgreSQL.
- Connaître les requêtes lentes est bien.
- Mais difficile de connaître leur plan d’exécution au moment où elles ont été lentes.
- D’où le module auto_explain.
Le but est donc de tracer automatiquement le plan d’exécution des requêtes. Pour éviter de trop écrire dans les fichiers de trace, il est possible de ne tracer que les requêtes dont la durée d’exécution a dépassé une certaine limite. Pour cela, il faut configurer le paramètre auto_explain.log_min_duration. D’autres options existent, qui permettent d’activer ou non certaines options du EXPLAIN : log_analyze, log_verbose, log_buffers, log_format.
VI-J-12. Extension plantuner▲
- Extension PostgreSQL.
-
Suivant la configuration :
- interdit l’utilisation de certains index,
- force à zéro les statistiques d’une table vide.
-
Intéressant sur un serveur de développement pour tester les plans :
- pas sur un serveur de production.
Cette extension est disponible à cette adresse. L’un de ses auteurs a publié récemment un article intéressant sur son utilisation.
Le dépôt se récupère avec la commande suivante :
git clone git://sigaev.ru/plantuner.git
L’outil une fois compilé et installé, la configuration est basée sur trois paramètres :
- plantuner.enable_index pour préciser les index à activer ;
- plantuner.disable_index pour préciser les index à désactiver ;
- plantuner.fix_empty_table pour forcer à zéro les statistiques des tables de 0 bloc.
Ils sont configurables à chaud, comme le montre l’exemple suivant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
LOAD 'plantuner';
EXPLAIN (COSTS OFF)
SELECT * FROM employes_big WHERE date_embauche='1000-01-01';
QUERY PLAN
-----------------------------------------------------------------
Index Scan using employes_big_date_embauche_idx on employes_big
Index Cond: (date_embauche = '1000-01-01'::date)
(2 rows)
SET plantuner.disable_index='employes_big_date_embauche_idx';
EXPLAIN (COSTS OFF)
SELECT * FROM employes_big WHERE date_embauche='1000-01-01';
QUERY PLAN
------------------------------------------------------
Gather
Workers Planned: 2
-> Parallel Seq Scan on employes_big
Filter: (date_embauche = '1000-01-01'::date)
(4 rows)
Un des intérêts de cette extension est de pouvoir interdire l’utilisation d’un index, afin de pouvoir ensuite le supprimer de manière transparente, c’est-à-dire sans bloquer aucune requête applicative.
Cependant, généralement, cette extension a sa place sur un serveur de développement, pas sur un serveur de production. En tout cas, pas dans le but de tromper le planificateur.
VI-J-13. Extension hypopg▲
- Extension PostgreSQL.
-
Création d’index hypothétique pour tester leur intérêt :
- avant de les créer pour de vrai.
Cette extension est disponible sur GitHub. Il existe quatre fonctions principales :
- hypopg_create_index() pour créer un index hypothétique ;
- hypopg_drop_index() pour supprimer un index hypothétique particulier ou hypopg_reset() pour tous les supprimer ;
- hypopg_liste_indexes() pour les lister.
Notez qu’en quittant la session, tous les index hypothétiques restants et créés sur cette session sont supprimés.
Voici un exemple d’utilisation :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
CREATE EXTENSION hypopg;
EXPLAIN SELECT * FROM employes_big WHERE prenom='Gaston';
QUERY PLAN
-------------------------------------------------------------------------------
Gather (cost=1000.00..8263.14 rows=1 width=41)
Workers Planned: 2
-> Parallel Seq Scan on employes_big (cost=0.00..7263.04 rows=1 width=41)
Filter: ((prenom)::text = 'Gaston'::text)
(4 rows)
SELECT * FROM hypopg_create_index('CREATE INDEX ON employes_big(prenom)');
indexrelid | indexname
------------+----------------------------------
24591 | <24591>btree_employes_big_prenom
(1 row)
EXPLAIN SELECT * FROM employes_big WHERE prenom='Gaston';
QUERY PLAN
-------------------------------------------------------------------
Index Scan using <24591>btree_employes_big_prenom on employes_big
(cost=0.05..4.07 rows=1 width=41)
Index Cond: ((prenom)::text = 'Gaston'::text)
(2 rows)
SELECT * FROM hypopg_list_indexes();
indexrelid | indexname | nspname | relname | amname
------------+----------------------------------+---------+--------------+--------
24591 | <24591>btree_employes_big_prenom | public | employes_big | btree
(1 row)
SELECT * FROM hypopg_reset();
hypopg_reset
--------------
(1 row)
CREATE INDEX ON employes_big(prenom);
EXPLAIN SELECT * FROM employes_big WHERE prenom='Gaston';
QUERY PLAN
----------------------------------------------------------
Index Scan using employes_big_prenom_idx on employes_big
(cost=0.42..4.44 rows=1 width=41)
Index Cond: ((prenom)::text = 'Gaston'::text)
(2 rows)
VI-K. Conclusion▲
- Planificateur très avancé.
- Mais faillible.
- Cependant, ne pensez pas être plus intelligent que le planificateur.
Certains SGBD concurrents supportent les hints, qui permettent au DBA de forcer l’optimiseur à choisir des plans d’exécution qu’il avait jugés trop coûteux. Ces hints sont exprimés sous la forme de commentaires et ne seront donc pas pris en compte par PostgreSQL, qui ne gère pas ces hints.
L’avis de la communauté PostgreSQL (voir https://wiki.postgresql.org/wiki/OptimizerHintsDiscussion) est que les hints mènent à des problèmes de maintenabilité du code applicatif, interfèrent avec les mises à jour, risquent d’être contre-productifs au fur et à mesure que vos tables grossissent, et sont généralement inutiles. Sur le long terme, il vaut mieux rapporter un problème rencontré avec l’optimiseur pour qu’il soit définitivement corrigé.
Si le plan d’exécution généré n’est pas optimal, il est préférable de chercher à comprendre d’où vient l’erreur. Nous avons vu dans ce module quelles pouvaient être les causes entraînant des erreurs d’estimation :
- Mauvaise écriture de requête.
- Modèle de données pas optimal.
- Statistiques pas à jour.
- Colonnes corrélées.
- …
VI-L. Annexe : Nœuds d’un plan▲
-
Quatre types de nœuds :
- Parcours (de table, d’index, de TID, etc.).
- Jointures (Nested Loop, Sort/Merge Join, Hash Join).
- Opérateurs sur des ensembles (Append, Except, Intersect, etc.).
- Et quelques autres (Sort, Aggregate, Unique, Limit, Materialize).
Un plan d’exécution est un arbre. Chaque nœud de l’arbre est une opération à effectuer par l’exécuteur. Le planificateur arrange les nœuds pour que le résultat final soit le bon, et qu’il soit récupéré le plus rapidement possible.
Il y a quatre types de nœuds :
-
les parcours, qui permettent de lire les données dans les tables en passant :
- soit par la table,
- soit par l’index ;
- les jointures, qui permettent de joindre deux ensembles de données ;
- les opérateurs sur des ensembles, qui là aussi vont joindre deux ensembles ou plus ;
- et les opérations sur un seul ensemble : tri, limite, agrégat, etc.
Cette annexe a pour but d’aller dans le détail sur chaque type de nœuds, ses avantages et inconvénients.
VI-L-1. Parcours▲
- Ne prend rien en entrée.
-
Mais renvoie un ensemble de données :
- trié ou non, filtré ou non.
-
Exemples typiques :
- parcours séquentiel d’une table, avec ou sans filtrage des enregistrements produits,
- parcours par un index, avec ou sans filtrage supplémentaire.
Les parcours sont les seules opérations qui lisent les données des tables (standard, temporaires ou non journalisées). Elles ne prennent donc rien en entrée et fournissent un ensemble de données en sortie. Cet ensemble peut être trié ou non, filtré ou non.
Il existe trois types de parcours que nous allons détailler :
- le parcours de table ;
- le parcours d’index ;
- le parcours de bitmap index.
Tous les trois peuvent recevoir des filtres supplémentaires en sortie.
Nous verrons aussi que PostgreSQL propose d’autres types de parcours.
VI-L-2. Parcours de table▲
-
Parcours séquentiel de la table (Sequential Scan ou SeqScan) :
- parallélisation possible (Parallel SeqScan).
- Aussi appelé Full table scan par d’autres SGBD.
-
La table est lue entièrement :
- même si seulement quelques lignes satisfont la requête,
- sauf dans le cas de la clause LIMIT sans ORDER BY.
- Elle est lue séquentiellement par blocs de 8 ko.
- Optimisation : synchronize_seqscans.
Le parcours le plus simple est le parcours séquentiel. La table est lue complètement, de façon séquentielle, par blocs de 8 ko. Les données sont lues dans l’ordre physique sur disque, donc les données ne sont pas envoyées triées au nœud supérieur.
Cela fonctionne dans tous les cas, car il n’y a besoin de rien de plus pour le faire : un parcours d’index nécessite un index, un parcours de table ne nécessite rien de plus que la table.
Le parcours de table est intéressant pour les performances dans deux cas :
- les très petites tables ;
- les grosses tables où la majorité des lignes doit être renvoyée.
Voici quelques exemples à partir de ce jeu de tests :
2.
3.
CREATE TABLE t1 (c1 integer);
INSERT INTO t1 (c1) SELECT generate_series(1, 100000);
ANALYZE t1;
Ici, nous faisons une lecture complète de la table. De ce fait, un parcours séquentiel sera plus rapide du fait de la rapidité de la lecture séquentielle des blocs :
EXPLAIN SELECT * FROM t1;
QUERY PLAN
----------------------------------------------------------
Seq Scan on t1 (cost=0.00..1443.00 rows=100000 width=4)
(1 row)Le coût est relatif au nombre de blocs lus, au nombre de lignes décodées et à la valeur des paramètres seq_page_cost et cpu_tuple_cost. Si un filtre est ajouté, cela aura un coût supplémentaire dû à l’application du filtre sur toutes les lignes de la table (pour trouver celles qui correspondent à ce filtre) :
2.
3.
4.
5.
6.
EXPLAIN SELECT * FROM t1 WHERE c1=1000;
QUERY PLAN
-----------------------------------------------------
Seq Scan on t1 (cost=0.00..1693.00 rows=1 width=4)
Filter: (c1 = 1000)
(2 rows)
Ce coût supplémentaire dépend du nombre de lignes dans la table et de la valeur du paramètre cpu_operator_cost ou de la valeur du paramètre COST de la fonction appelée. L’exemple ci-dessus montre le coût (1693) en utilisant l’opérateur standard d’égalité. Maintenant, si on crée une fonction qui utilise cet opérateur (mais écrite en PL/pgSQL, cela reste invisible pour PostgreSQL), avec un coût forcé à 10 000, cela donne :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
CREATE FUNCTION egal(integer,integer) RETURNS boolean LANGUAGE plpgsql AS $$
begin
return $1 = $2;
end
$$
COST 10000;
EXPLAIN SELECT * FROM t1 WHERE egal(c1, 1000);
QUERY PLAN
------------------------------------------------------------
Seq Scan on t1 (cost=0.00..2501443.00 rows=33333 width=4)
Filter: egal(c1, 1000)
(2 rows)
La ligne Filter indique le filtre réalisé. Le nombre de lignes indiqué par rows= est le nombre de lignes après filtrage. Pour savoir combien de lignes ne satisfont pas le prédicat de la clause WHERE, il faut exécuter la requête et donc utiliser l’option ANALYZE :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
EXPLAIN (ANALYZE,BUFFERS)
SELECT * FROM t1 WHERE c1=1000;
QUERY PLAN
-----------------------------------------------------
Seq Scan on t1 (cost=0.00..1693.00 rows=1 width=4)
(actual time=0.236..19.615 rows=1 loops=1)
Filter: (c1 = 1000)
Rows Removed by Filter: 99999
Buffers: shared hit=443
Planning time: 0.110 ms
Execution time: 19.649 ms
(6 rows)
Il s’agit de la ligne Rows Removed by Filter.
L’option BUFFERS permet en plus de savoir le nombre de blocs lus dans le cache et hors du cache.
Le calcul réalisé pour le coût final est le suivant :
2.
3.
4.
5.
6.
7.
8.
9.
SELECT
round((
current_setting('seq_page_cost')::numeric*relpages +
current_setting('cpu_tuple_cost')::numeric*reltuples +
current_setting('cpu_operator_cost')::numeric*reltuples
)::numeric, 2)
AS cout_final
FROM pg_class
WHERE relname='employes';
Une optimisation des parcours séquentiels a eu lieu en version 8.3. Auparavant, quand deux processus parcouraient en même temps la même table de façon séquentielle, ils lisaient chacun la table. À partir de la 8.3, si le paramètre synchronize_seqscans est activé, le processus qui entame une lecture séquentielle cherche en premier lieu si un autre processus ne ferait pas une lecture séquentielle de la même table. Si c’est le cas, le second processus démarre son parcours de table à l’endroit où le premier processus est en train de lire, ce qui lui permet de profiter des données mises en cache par ce processus. L’accès au disque étant bien plus lent que l’accès mémoire, les processus restent naturellement synchronisés pour le reste du parcours de la table, et les lectures ne sont donc réalisées qu’une seule fois. Le début de la table restera à lire indépendamment. Cette optimisation permet de diminuer le nombre de blocs lus par chaque processus en cas de lectures parallèles de la même table.
Il est possible, pour des raisons de tests, ou pour tenter de maintenir la compatibilité avec du code partant de l’hypothèse (erronée) que les données d’une table sont toujours retournées dans le même ordre, de désactiver ce type de parcours en positionnant le paramètre synchronize_seqscans à off.
Une nouvelle optimisation vient de la parallélisation. Depuis la version 9.6, il est possible d’obtenir un parcours de table parallélisé. Dans ce cas, le nœud s’appelle un Parallel Seq Scan. Le processus responsable de la requête demande l’exécution de plusieurs processus, appelés des workers qui auront tous pour charge de lire la table et d’appliquer le filtre. Chaque worker travaillera sur des blocs différents. Le prochain bloc à lire est enregistré en mémoire partagée. Quand un worker a terminé de travailler sur un bloc, il consulte la mémoire partagée pour connaître le prochain bloc à traiter, et incrémente ce numéro pour que le worker suivant puisse travailler sur un autre bloc. Il n’y a aucune assurance que chaque worker travaillera sur le même nombre de blocs. Voici un exemple de plan parallélisé pour un parcours de table :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
EXPLAIN (ANALYZE,BUFFERS)
SELECT sum(c2) FROM t1 WHERE c1 BETWEEN 100000 AND 600000;
QUERY PLAN
-------------------------------------------------------------------------
Finalize Aggregate (cost=12196.94..12196.95 rows=1 width=8)
(actual time=91.886..91.886 rows=1 loops=1)
Buffers: shared hit=1277
-> Gather (cost=12196.73..12196.94 rows=2 width=8)
(actual time=91.874..91.880 rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=1277
-> Partial Aggregate (cost=11196.73..11196.74 rows=1 width=8)
(actual time=83.760..83.760 rows=1 loops=3)
Buffers: shared hit=4425
-> Parallel Seq Scan on t1
(cost=0.00..10675.00 rows=208692 width=4)
(actual time=12.727..62.608 rows=166667 loops=3)
Filter: ((c1 >= 100000) AND (c1 <= 600000))
Rows Removed by Filter: 166666
Buffers: shared hit=4425
Planning time: 0.528 ms
Execution time: 94.877 ms
(14 rows)
Dans ce cas, le planificateur a prévu l’exécution de deux workers, et deux ont bien été lancés lors de l’exécution de la requête.
VI-L-3. Parcours d’index▲
- Parcours aléatoire de l’index.
-
Pour chaque enregistrement correspondant à la recherche :
- parcours non séquentiel de la table (pour vérifier la visibilité de la ligne).
-
Sur d’autres SGBD, cela revient à un :
- INDEX RANGE SCAN, suivi d’un TABLE ACCESS BY INDEX ROWID.
- Gros gain en performance quand le filtre est très sélectif.
- L’ensemble de lignes renvoyé est trié.
-
Parallélisation possible :
- Btree uniquement,
- v10+.
Parcourir une table prend du temps, surtout quand on cherche à ne récupérer que quelques lignes de cette table. Le but d’un index est donc d’utiliser une structure de données optimisée pour satisfaire une recherche particulière (on parle de prédicat).
Cette structure est un arbre. La recherche consiste à suivre la structure de l’arbre pour trouver le premier enregistrement correspondant au prédicat, puis suivre les feuilles de l’arbre jusqu’au dernier enregistrement vérifiant le prédicat. De ce fait, et étant donné la façon dont l’arbre est stocké sur disque, cela peut provoquer des déplacements de la tête de lecture.
L’autre problème des performances sur les index (mais cette fois, spécifique à PostgreSQL) est que les informations de visibilité des lignes sont uniquement stockées dans la table. Cela veut dire que, pour chaque élément de l’index correspondant au filtre, il va falloir lire la ligne dans la table pour vérifier si cette dernière est visible pour la transaction en cours. Il est de toute façon, pour la plupart des requêtes, nécessaire d’aller inspecter l’enregistrement de la table pour récupérer les autres colonnes nécessaires au bon déroulement de la requête, qui ne sont la plupart du temps pas stockées dans l’index. Ces enregistrements sont habituellement éparpillés dans la table, et retournés dans un ordre totalement différent de leur ordre physique par le parcours sur l’index. Cet accès à la table génère donc énormément d’accès aléatoires. Or, ce type d’activité est généralement le plus lent sur un disque magnétique. C’est pourquoi le parcours d’une large portion d’un index est très lent. PostgreSQL ne cherchera à utiliser un index que s’il suppose qu’il aura peu de lignes à récupérer.
Voici l’algorithme permettant un parcours d’index avec PostgreSQL :
-
Pour tous les éléments de l’index :
- chercher l’élément souhaité dans l’index,
- lorsqu’un élément est trouvé : vérifier qu’il est visible par la transaction en lisant la ligne dans la table et récupérer les colonnes supplémentaires de la table.
Cette manière de procéder est identique à ce que proposent d’autres SGBD sous les termes d’INDEX RANGE SCAN, suivi d’un TABLE ACCESS BY INDEX ROWID.
Un parcours d’index est donc très coûteux, principalement à cause des déplacements de la tête de lecture. Le paramètre lié au coût de lecture aléatoire d’une page est par défaut 4 fois supérieur à celui de la lecture séquentielle d’une page. Ce paramètre s’appelle random_page_cost. Un parcours d’index n’est préférable à un parcours de table que si la recherche ne va ramener qu’un très faible pourcentage de la table. Et dans ce cas, le gain possible est très important par rapport à un parcours séquentiel de table. Par contre, il se révèle très lent pour lire un gros pourcentage de la table (les accès aléatoires diminuent spectaculairement les performances).
Il est à noter que, contrairement au parcours de table, le parcours d’index renvoie les données triées. C’est le seul parcours à le faire. Il peut même servir à honorer la clause ORDER BY d’une requête. L’index est aussi utilisable dans le cas des tris descendants. Dans ce cas, le nœud est nommé Index Scan Backward. Ce renvoi de données triées est très intéressant lorsqu’il est utilisé en conjonction avec la clause LIMIT.
Il ne faut pas oublier aussi le coût de mise à jour de l’index. Si un index n’est pas utilisé, il coûte cher en maintenance (ajout des nouvelles entrées, suppression des entrées obsolètes, etc.).
Enfin, il est à noter que ce type de parcours est consommateur aussi en CPU.
Voici un exemple montrant les deux types de parcours et ce que cela occasionne comme lecture disque. Commençons par créer une table, lui insérer quelques données et lui ajouter un index :
2.
3.
4.
CREATE TABLE t1 (c1 integer, c2 integer);
INSERT INTO t1 VALUES (1,2), (2,4), (3,6);
CREATE INDEX i1 ON t1(c1);
ANALYZE t1;
Essayons maintenant de lire la table avec un simple parcours séquentiel :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM t1 WHERE c1=2;
QUERY PLAN
--------------------------------------------------
Seq Scan on t1 (cost=0.00..1.04 rows=1 width=8)
(actual time=0.020..0.023 rows=1 loops=1)
Filter: (c1 = 2)
Rows Removed by Filter: 2
Buffers: shared hit=1
Planning time: 0.163 ms
Execution time: 0.065 ms
(6 rows)
Seq Scan est le titre du nœud pour un parcours séquentiel. Profitons-en pour noter qu’il a fait de lui-même un parcours séquentiel. En effet, la table est tellement petite (8 ko) qu’utiliser l’index coûterait forcément plus cher. Grâce à l’option BUFFERS, nous savons que seul un bloc a été lu.
Pour faire un parcours d’index, nous allons désactiver les parcours séquentiels et réinitialiser les statistiques :
SET enable_seqscan TO off;
Il existe aussi un paramètre, appelé enable_indexscan, pour désactiver les parcours d’index.
Maintenant relançons la requête :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM t1 WHERE c1=2;
QUERY PLAN
-------------------------------------------------------------
Index Scan using i1 on t1 (cost=0.13..8.15 rows=1 width=8)
(actual time=0.117..0.121 rows=1 loops=1)
Index Cond: (c1 = 2)
Buffers: shared hit=1 read=1
Planning time: 0.174 ms
Execution time: 0.174 ms
(5 rows)
Nous avons bien un parcours d’index. Vérifions les statistiques sur l’activité :
2.
3.
4.
5.
6.
7.
8.
9.
10.
SELECT relname,
heap_blks_read, heap_blks_hit,
idx_blks_read, idx_blks_hit
FROM pg_statio_user_tables
WHERE relname='t1';
relname | heap_blks_read | heap_blks_hit | idx_blks_read | idx_blks_hit
---------+----------------+---------------+---------------+--------------
t1 | 0 | 1 | 1 | 0
(1 row)
Une page disque a été lue dans l’index (colonne idx_blks_read à 1) et une autre a été lue dans la table (colonne heap_blks_hit à 1). Le plus impactant est l’accès aléatoire sur l’index et la table. Il serait bon d’avoir une lecture de l’index, puis une lecture séquentielle de la table. C’est le but du Bitmap Index Scan.
VI-L-4. Parcours d’index bitmap▲
- En VO : Bitmap Index Scan / Bitmap Heap Scan.
-
Diminuer les déplacements de la tête de lecture en découplant le parcours de l’index du parcours de la table :
- lecture en un bloc de l’index,
- tri des blocs à parcourir dans la table (9.5+),
- lecture en un bloc de la partie intéressante de la table.
-
Pouvoir combiner plusieurs index en mémoire :
- nœud BitmapAnd,
- nœud BitmapOr.
-
Coût de démarrage généralement important :
- parcours moins intéressant avec une clause LIMIT.
-
Parallélisation possible :
- Btree uniquement,
- v10+.
Contrairement à d’autres SGBD, un index bitmap n’a aucune existence sur disque. Il est créé en mémoire lorsque son utilisation a un intérêt. Le but est de diminuer les déplacements de la tête de lecture en découplant le parcours de l’index du parcours de la table :
- lecture en un bloc de l’index ;
- tri des blocs à parcourir dans la table (9.3+) dans l’ordre physique de la table, pas dans l’ordre logique de l’index ;
- lecture en un bloc de la partie intéressante de la table.
Il est souvent utilisé quand il y a un grand nombre de valeurs à filtrer, notamment pour les clauses IN et ANY. En voici un exemple :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
CREATE TABLE t1(c1 integer, c2 integer);
INSERT INTO t1 SELECT i, i+1 FROM generate_series(1, 1000) AS i;
CREATE INDEX ON t1(c1);
CREATE INDEX ON t1(c2);
ANALYZE t1;
EXPLAIN SELECT * FROM t1 WHERE c1 IN (10, 40, 60, 100, 600);
QUERY PLAN
--------------------------------------------------------------------------
Bitmap Heap Scan on t1 (cost=17.45..22.85 rows=25 width=8)
Recheck Cond: (c1 = ANY ('{10,40,60,100,600}'::integer[]))
-> Bitmap Index Scan on t1_c1_idx (cost=0.00..17.44 rows=25 width=0)
Index Cond: (c1 = ANY ('{10,40,60,100,600}'::integer[]))
(4 rows)
La partie Bitmap Index Scan concerne le parcours de l’index, et la partie Bitmap Heap Scan concerne le parcours de table.
L’algorithme pourrait être décrit ainsi :
- chercher tous les éléments souhaités dans l’index ;
- les placer dans une structure (de TID) de type bitmap en mémoire ;
- faire un parcours séquentiel partiel de la table.
Ce champ de bits a deux codages possibles :
- un bit par ligne ;
- ou un bit par bloc si trop de données.
Dans ce dernier (mauvais) cas, il y a une étape de revérification (Recheck Condition).
Ce type d’index présente un autre gros intérêt : pouvoir combiner plusieurs index en mémoire. Les bitmaps de TID se combinent facilement avec des opérations booléennes AND et OR. Dans ce cas, on obtient les nœuds BitmapAnd et BitmapOr. Voici un exemple de ce dernier :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
b1=# EXPLAIN SELECT * FROM t1
WHERE c1 IN (10, 40, 60, 100, 600) OR c2 IN (300, 400, 500);
QUERY PLAN
-------------------------------------------------------------------------------
Bitmap Heap Scan on t1 (cost=30.32..36.12 rows=39 width=8)
Recheck Cond: ((c1 = ANY ('{10,40,60,100,600}'::integer[]))
OR (c2 = ANY ('{300,400,500}'::integer[])))
-> BitmapOr (cost=30.32..30.32 rows=40 width=0)
-> Bitmap Index Scan on t1_c1_idx
(cost=0.00..17.44 rows=25 width=0)
Index Cond: (c1 = ANY ('{10,40,60,100,600}'::integer[]))
-> Bitmap Index Scan on t1_c2_idx
(cost=0.00..12.86 rows=15 width=0)
Index Cond: (c2 = ANY ('{300,400,500}'::integer[]))
(7 rows)
Le coût de démarrage est généralement important à cause de la lecture préalable de l’index et du tri des TID. Du coup, ce type de parcours est moins intéressant si une clause LIMIT est présente. Un parcours d’index simple sera généralement choisi dans ce cas.
Le paramètre enable_bitmapscan permet d’activer ou de désactiver l’utilisation des parcours d’index bitmap.
À noter que ce type de parcours n’est disponible qu’à partir de PostgreSQL 8.1.
VI-L-5. Parcours d’index seul▲
-
Avant la 9.2, pour une requête de ce type :
- SELECT c1 FROM t1 WHERE c1<10 .
-
PostgreSQL devait lire l’index et la table :
- car les informations de visibilité ne se trouvent que dans la table.
-
En 9.2, le planificateur peut utiliser la « Visibility Map » :
- nouveau nœud « Index Only Scan »,
- Index B-Tree (9.2+),
- Index SP-GiST (9.2+),
- Index GiST (9.5+) => types : point, box, inet, range.
Voici un exemple en 9.1 :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
b1=# CREATE TABLE demo_i_o_scan (a int, b text);
CREATE TABLE
b1=# INSERT INTO demo_i_o_scan
b1-# SELECT random()*10000000, a
b1-# FROM generate_series(1,10000000) a;
INSERT 0 10000000
b1=# CREATE INDEX demo_idx ON demo_i_o_scan (a,b);
CREATE INDEX
b1=# VACUUM ANALYZE demo_i_o_scan ;
VACUUM
b1=# EXPLAIN ANALYZE SELECT * FROM demo_i_o_scan
b1=# WHERE a BETWEEN 10000 AND 100000;
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on demo_i_o_scan (cost=2299.83..59688.65 rows=89565 width=11)
(actual time=209.569..3314.717 rows=89877 loops=1)
Recheck Cond: ((a >= 10000) AND (a <= 100000))
-> Bitmap Index Scan on demo_idx (cost=0.00..2277.44 rows=89565 width=0)
(actual time=197.177..197.177 rows=89877 loops=1)
Index Cond: ((a >= 10000) AND (a <= 100000))
Total runtime: 3323.497 ms
(5 rows)
b1=# EXPLAIN ANALYZE SELECT * FROM demo_i_o_scan
b1=# WHERE a BETWEEN 10000 AND 100000;
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on demo_i_o_scan (cost=2299.83..59688.65 rows=89565 width=11)
(actual time=48.620..269.907 rows=89877 loops=1)
Recheck Cond: ((a >= 10000) AND (a <= 100000))
-> Bitmap Index Scan on demo_idx (cost=0.00..2277.44 rows=89565 width=0)
(actual time=35.780..35.780 rows=89877 loops=1)
Index Cond: ((a >= 10000) AND (a <= 100000))
Total runtime: 273.761 ms
(5 rows)
Donc 3 secondes pour la première exécution (avec un cache pas forcément vide), et 273 millisecondes pour la deuxième exécution (et les suivantes, non affichées ici).
Voici ce que cet exemple donne en 9.2 :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
b1=# CREATE TABLE demo_i_o_scan (a int, b text);
CREATE TABLE
b1=# INSERT INTO demo_i_o_scan
b1-# SELECT random()*10000000, a
b1-# FROM (select generate_series(1,10000000)) AS t(a);
INSERT 0 10000000
b1=# CREATE INDEX demo_idx ON demo_i_o_scan (a,b);
CREATE INDEX
b1=# VACUUM ANALYZE demo_i_o_scan ;
VACUUM
b1=# EXPLAIN ANALYZE SELECT * FROM demo_i_o_scan
b1=# WHERE a BETWEEN 10000 AND 100000;
QUERY PLAN
--------------------------------------------------------------------------------
Index Only Scan using demo_idx on demo_i_o_scan
(cost=0.00..3084.77 rows=86656 width=11)
(actual time=0.080..97.942 rows=89432 loops=1)
Index Cond: ((a >= 10000) AND (a <= 100000))
Heap Fetches: 0
Total runtime: 108.134 ms
(4 rows)
b1=# EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM demo_i_o_scan
b1=# WHERE a BETWEEN 10000 AND 100000;
QUERY PLAN
--------------------------------------------------------------------------------
Index Only Scan using demo_idx on demo_i_o_scan
(cost=0.00..3084.77 rows=86656 width=11)
(actual time=0.024..26.954 rows=89432 loops=1)
Index Cond: ((a >= 10000) AND (a <= 100000))
Heap Fetches: 0
Buffers: shared hit=347
Total runtime: 34.352 ms
(5 rows)
Donc, même à froid, il est déjà pratiquement trois fois plus rapide que la version 9.1, à chaud. La version 9.2 est dix fois plus rapide à chaud.
Essayons maintenant en désactivant les parcours d’index seul :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
b1=# SET enable_indexonlyscan TO off;
SET
b1=# EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM demo_i_o_scan
b1=# WHERE a BETWEEN 10000 AND 100000;
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on demo_i_o_scan (cost=2239.88..59818.53 rows=86656 width=11)
(actual time=29.256..2992.289 rows=89432 loops=1)
Recheck Cond: ((a >= 10000) AND (a <= 100000))
Rows Removed by Index Recheck: 6053582
Buffers: shared hit=346 read=43834 written=2022
-> Bitmap Index Scan on demo_idx (cost=0.00..2218.21 rows=86656 width=0)
(actual time=27.004..27.004 rows=89432 loops=1)
Index Cond: ((a >= 10000) AND (a <= 100000))
Buffers: shared hit=346
Total runtime: 3000.502 ms
(8 rows)
b1=# EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM demo_i_o_scan
b1=# WHERE a BETWEEN 10000 AND 100000;
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on demo_i_o_scan (cost=2239.88..59818.53 rows=86656 width=11)
(actual time=23.533..1141.754 rows=89432 loops=1)
Recheck Cond: ((a >= 10000) AND (a <= 100000))
Rows Removed by Index Recheck: 6053582
Buffers: shared hit=2 read=44178
-> Bitmap Index Scan on demo_idx (cost=0.00..2218.21 rows=86656 width=0)
(actual time=21.592..21.592 rows=89432 loops=1)
Index Cond: ((a >= 10000) AND (a <= 100000))
Buffers: shared hit=2 read=344
Total runtime: 1146.538 ms
(8 rows)
On retombe sur les performances de la version 9.1.
Maintenant, essayons avec un cache vide (niveau PostgreSQL et système) :
- en 9.1
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
b1=# EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM demo_i_o_scan
b1=# WHERE a BETWEEN 10000 AND 100000;
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on demo_i_o_scan (cost=2299.83..59688.65 rows=89565 width=11)
(actual time=126.624..9750.245 rows=89877 loops=1)
Recheck Cond: ((a >= 10000) AND (a <= 100000))
Buffers: shared hit=2 read=44250
-> Bitmap Index Scan on demo_idx (cost=0.00..2277.44 rows=89565 width=0)
(actual time=112.542..112.542 rows=89877 loops=1)
Index Cond: ((a >= 10000) AND (a <= 100000))
Buffers: shared hit=2 read=346
Total runtime: 9765.670 ms
(7 rows)
- En 9.2
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
b1=# EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM demo_i_o_scan
b1=# WHERE a BETWEEN 10000 AND 100000;
QUERY PLAN
--------------------------------------------------------------------------------
Index Only Scan using demo_idx on demo_i_o_scan
(cost=0.00..3084.77 rows=86656 width=11)
(actual time=11.592..63.379 rows=89432 loops=1)
Index Cond: ((a >= 10000) AND (a <= 100000))
Heap Fetches: 0
Buffers: shared hit=2 read=345
Total runtime: 70.188 ms
(5 rows)
La version 9.1 met 10 secondes à exécuter la requête, alors que la version 9.2 ne met que 70 millisecondes (elle est donc 142 fois plus rapide).
Voir aussi cet article de blog.
VI-L-6. Parcours : autres▲
- TID Scan.
- Function Scan.
- Values.
- Result.
Il existe d’autres parcours, bien moins fréquents ceci dit.
TID est l’acronyme de Tuple ID. C’est en quelque sorte un pointeur vers une ligne. Un TID Scan est un parcours de TID. Ce type de parcours est généralement utilisé en interne par PostgreSQL. Notez qu’il est possible de le désactiver via le paramètre enable_tidscan.
Un Function Scan est utilisé par les fonctions renvoyant des ensembles (appelées SRF pour Set Returning Functions). En voici un exemple :
b1=# EXPLAIN SELECT * FROM generate_series(1, 1000);
QUERY PLAN
------------------------------------------------------------------------
Function Scan on generate_series (cost=0.00..10.00 rows=1000 width=4)
(1 row)VALUES est une clause de l’instruction INSERT, mais VALUES peut aussi être utilisé comme une table dont on spécifie les valeurs. Par exemple :
b1=# VALUES (1), (2);
column1
---------
1
2
(2 rows)
b1=# SELECT * FROM (VALUES ('a', 1), ('b', 2), ('c', 3)) AS tmp(c1, c2);
c1 | c2
----+----
a | 1
b | 2
c | 3
(3 rows)Le planificateur utilise un nœud spécial appelé Values Scan pour indiquer un parcours sur cette clause :
b1=# EXPLAIN
b1-# SELECT *
b1-# FROM (VALUES ('a', 1), ('b', 2), ('c', 3))
b1-# AS tmp(c1, c2);
QUERY PLAN
--------------------------------------------------------------
Values Scan on "*VALUES*" (cost=0.00..0.04 rows=3 width=36)
(1 row)Enfin, le nœud Result n’est pas à proprement parler un nœud de type parcours. Il y ressemble dans le fait qu’il ne prend aucun ensemble de données en entrée et en renvoie un en sortie. Son but est de renvoyer un ensemble de données suite à un calcul. Par exemple :
b1=# EXPLAIN SELECT 1+2;
QUERY PLAN
------------------------------------------
Result (cost=0.00..0.01 rows=1 width=0)
(1 row)VI-L-7. Jointures▲
-
Prend deux ensembles de données en entrée :
- l’une est appelée inner (interne),
- l’autre est appelée outer (externe).
- Et renvoie un seul ensemble de données.
-
Exemples typiques :
- Nested Loop, Merge Join, Hash Join.
Le but d’une jointure est de grouper deux ensembles de données pour n’en produire qu’un seul. L’un des ensembles est appelé ensemble interne (inner set), l’autre est appelé ensemble externe (outer set).
Le planificateur de PostgreSQL est capable de traiter les jointures grâce à trois nœuds :
- Nested Loop, une boucle imbriquée ;
- Merge Join, un parcours des deux ensembles triés ;
- Hash Join, une jointure par tests des données hachées.
VI-L-8. Nested Loop▲
-
Pour chaque ligne de la relation externe :
-
pour chaque ligne de la relation interne :
- si la condition de jointure est avérée : émettre la ligne en résultat.
-
- L’ensemble externe n’est parcouru qu’une fois.
-
L’ensemble interne est parcouru pour chaque ligne de l’ensemble externe :
- avoir un index utilisable sur l’ensemble interne augmente fortement les performances.
Étant donné le pseudo-code indiqué ci-dessus, on s’aperçoit que l’ensemble externe n’est parcouru qu’une fois alors que l’ensemble interne est parcouru pour chaque ligne de l’ensemble externe. Le coût de ce nœud est donc proportionnel à la taille des ensembles. Il est intéressant pour les petits ensembles de données, et encore plus lorsque l’ensemble interne dispose d’un index satisfaisant la condition de jointure.
En théorie, il s’agit du type de jointure le plus lent, mais il a un gros intérêt : il n’est pas nécessaire de trier les données ou de les hacher avant de commencer à traiter les données. Il a donc un coût de démarrage très faible, ce qui le rend très intéressant si cette jointure est couplée à une clause LIMIT, ou si le nombre d’itérations (donc le nombre d’enregistrements de la relation externe) est faible.
Il est aussi très intéressant, car il s’agit du seul nœud capable de traiter des jointures sur des conditions différentes de l’égalité ainsi que des jointures de type CROSS JOIN.
Voici un exemple avec deux parcours séquentiels :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
b1=# EXPLAIN SELECT *
FROM pg_class, pg_namespace
WHERE pg_class.relnamespace=pg_namespace.oid;
QUERY PLAN
-------------------------------------------------------------------------
Nested Loop (cost=0.00..37.18 rows=281 width=307)
Join Filter: (pg_class.relnamespace = pg_namespace.oid)
-> Seq Scan on pg_class (cost=0.00..10.81 rows=281 width=194)
-> Materialize (cost=0.00..1.09 rows=6 width=117)
-> Seq Scan on pg_namespace (cost=0.00..1.06 rows=6 width=117)
(5 rows)
Et un exemple avec un parcours séquentiel et un parcours d’index :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
b1=# SET random_page_cost TO 0.5;
b1=# EXPLAIN SELECT *
FROM pg_class, pg_namespace
WHERE pg_class.relnamespace=pg_namespace.oid;
QUERY PLAN
-------------------------------------------------------------------------
Nested Loop (cost=0.00..33.90 rows=281 width=307)
-> Seq Scan on pg_namespace (cost=0.00..1.06 rows=6 width=117)
-> Index Scan using pg_class_relname_nsp_index on pg_class
(cost=0.00..4.30 rows=94 width=194)
Index Cond: (relnamespace = pg_namespace.oid)
(4 rows)
Le paramètre enable_nestloop permet d’activer ou de désactiver ce type de nœud.
VI-L-9. Merge Join▲
- Trier l’ensemble interne.
- Trier l’ensemble externe.
-
Tant qu’il reste des lignes dans un des ensembles :
- lire les deux ensembles en parallèle,
-
lorsque la condition de jointure est avérée :
- émettre la ligne en résultat.
- Parcourir les deux ensembles triés (d’où Sort-Merge Join).
- Ne gère que les conditions avec égalité.
- Produit un ensemble résultat trié.
- Le plus rapide sur de gros ensembles de données.
Contrairement au Nested Loop, le Merge Join ne lit qu’une fois chaque ligne, sauf pour les valeurs dupliquées. C’est d’ailleurs son principal atout.
L’algorithme est assez simple. Les deux ensembles de données sont tout d’abord triés, puis ils sont parcourus ensemble. Lorsque la condition de jointure est vraie, la ligne résultante est envoyée dans l’ensemble de données en sortie.
L’inconvénient de cette méthode est que les données en entrée doivent être triées. Trier les données peut prendre du temps, surtout si les ensembles de données sont volumineux. Cela étant dit, le Merge Join peut s’appuyer sur un index pour accélérer l’opération de tri (ce sera alors forcément un Index Scan). Une table clusterisée peut aussi accélérer l’opération de tri. Néanmoins, il faut s’attendre à avoir un coût de démarrage important pour ce type de nœud, ce qui fait qu’il sera facilement disqualifié si une clause LIMIT est à exécuter après la jointure.
Le gros avantage du tri sur les données en entrée est que les données reviennent triées. Cela peut avoir son avantage dans certains cas.
Voici un exemple pour ce nœud :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
b1=# EXPLAIN SELECT *
FROM pg_class, pg_namespace
WHERE pg_class.relnamespace=pg_namespace.oid;
QUERY PLAN
-------------------------------------------------------------------------
Merge Join (cost=23.38..27.62 rows=281 width=307)
Merge Cond: (pg_namespace.oid = pg_class.relnamespace)
-> Sort (cost=1.14..1.15 rows=6 width=117)
Sort Key: pg_namespace.oid
-> Seq Scan on pg_namespace (cost=0.00..1.06 rows=6 width=117)
-> Sort (cost=22.24..22.94 rows=281 width=194)
Sort Key: pg_class.relnamespace
-> Seq Scan on pg_class (cost=0.00..10.81 rows=281 width=194)
(8 rows)
Le paramètre enable_mergejoin permet d’ activer ou de désactiver ce type de nœud.
VI-L-10. Hash Join▲
- Calculer le hachage de chaque ligne de l’ensemble interne.
-
Tant qu’il reste des lignes dans l’ensemble externe :
- hacher la ligne lue,
- comparer ce hachage aux lignes hachées de l’ensemble interne,
-
si une correspondance est trouvée :
- émettre la ligne trouvée en résultat.
- Ne gère que les conditions avec égalité.
- Idéal pour joindre une grande table à une petite table.
- Coût de démarrage important à cause du hachage de la table.
La vérification de la condition de jointure peut se révéler assez lente dans beaucoup de cas : elle nécessite un accès à un enregistrement par un index ou un parcours de la table interne à chaque itération dans un Nested Loop par exemple. Le Hash Join cherche à supprimer ce problème en créant une table de hachage de la table interne. Cela sous-entend qu’il faut au préalable calculer le hachage de chaque ligne de la table interne. Ensuite, il suffit de parcourir la table externe, hacher chaque ligne l’une après l’autre et retrouver le ou les enregistrements de la table interne pouvant correspondre à la valeur hachée de la table externe. On vérifie alors qu’ils répondent bien aux critères de jointure (il peut y avoir des collisions dans un hachage, ou des prédicats supplémentaires à vérifier).
Ce type de nœud est très rapide à condition d’avoir suffisamment de mémoire pour stocker le résultat du hachage de l’ensemble interne. Du coup, le paramétrage de work_mem peut avoir un gros impact. De même, diminuer le nombre de colonnes récupérées permet de diminuer la mémoire à utiliser pour le hachage et du coup d’améliorer les performances d’un Hash Join. Cependant, si la mémoire est insuffisante, il est possible de travailler par groupes de lignes (batch). L’algorithme est alors une version améliorée de l’algorithme décrit plus haut, permettant justement de travailler en partitionnant la table interne (on parle de Hybrid Hash Join). Il est à noter que ce type de nœud est souvent idéal pour joindre une grande table à une petite table.
Le coût de démarrage peut se révéler important à cause du hachage de la table interne. Il ne sera probablement pas utilisé par l’optimiseur si une clause LIMIT est à exécuter après la jointure.
Attention, les données retournées par ce nœud ne sont pas triées.
De plus, ce type de nœud peut être très lent si l’estimation de la taille des tables est mauvaise.
Voici un exemple de Hash Join :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
b1=# EXPLAIN SELECT *
FROM pg_class, pg_namespace
WHERE pg_class.relnamespace=pg_namespace.oid;
QUERY PLAN
------------------------------------------------------------------------
Hash Join (cost=1.14..15.81 rows=281 width=307)
Hash Cond: (pg_class.relnamespace = pg_namespace.oid)
-> Seq Scan on pg_class (cost=0.00..10.81 rows=281 width=194)
-> Hash (cost=1.06..1.06 rows=6 width=117)
-> Seq Scan on pg_namespace (cost=0.00..1.06 rows=6 width=117)
(5 rows)
Le paramètre enable_hashjoin permet d’ activer ou de désactiver ce type de nœud.
VI-L-11. Suppression d’une jointure▲
2.
3.
FROM pg_class
LEFT JOIN pg_namespace
ON pg_class.relnamespace=pg_namespace.oid;
SELECTpg_class.relname, pg_class.reltuples.- Un index unique existe sur la colonne oid de pg_namespace.
-
Jointure inutile :
- sa présence ne change pas le résultat.
- PostgreSQL peut supprimer la jointure à partir de la 9.0.
Sur la requête ci-dessus, la jointure est inutile. En effet, il existe un index unique sur la colonne oid de la table pg_namespace. De plus, aucune colonne de la table pg_namespace ne va apparaître dans le résultat. Autrement dit, que la jointure soit présente ou non, cela ne va pas changer le résultat. Dans ce cas, il est préférable de supprimer la jointure. Si le développeur ne le fait pas, PostgreSQL le fera (pour les versions 9.0 et ultérieures de PostgreSQL). Cet exemple le montre.
Voici la requête exécutée en 8.4 :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
b1=# EXPLAIN SELECT pg_class.relname, pg_class.reltuples
FROM pg_class
LEFT JOIN pg_namespace ON pg_class.relnamespace=pg_namespace.oid;
QUERY PLAN
------------------------------------------------------------------------
Hash Left Join (cost=1.14..12.93 rows=244 width=68)
Hash Cond: (pg_class.relnamespace = pg_namespace.oid)
-> Seq Scan on pg_class (cost=0.00..8.44 rows=244 width=72)
-> Hash (cost=1.06..1.06 rows=6 width=4)
-> Seq Scan on pg_namespace (cost=0.00..1.06 rows=6 width=4)
(5 rows)
Et la même requête exécutée en 9.0 :
2.
3.
4.
5.
6.
7.
b1=# EXPLAIN SELECT pg_class.relname, pg_class.reltuples
FROM pg_class
LEFT JOIN pg_namespace ON pg_class.relnamespace=pg_namespace.oid;
QUERY PLAN
------------------------------------------------------------
Seq Scan on pg_class (cost=0.00..10.81 rows=281 width=72)
(1 row)
On constate que la jointure est ignorée.
Ce genre de requête peut fréquemment survenir, surtout avec des générateurs de requêtes comme les ORM. L’utilisation de vues imbriquées peut aussi être la source de ce type de problème.
VI-L-12. Ordre de jointure▲
- Trouver le bon ordre de jointure est un point clé dans la recherche de performances.
- Nombre de possibilités en augmentation factorielle avec le nombre de tables.
- Si petit nombre, recherche exhaustive.
-
Sinon, utilisation d’heuristiques et de GEQO :
- limite le temps de planification et l’utilisation de mémoire,
- join_collapse_limit, from_collapse_limit : limites de huit tables.
Sur une requête comme SELECT * FROM a, b, c..., les tables a, b et c ne sont pas forcément jointes dans cet ordre. PostgreSQL teste différents ordres pour obtenir les meilleures performances.
Prenons comme exemple la requête suivante :
SELECT * FROM a JOIN b ON a.id=b.id JOIN c ON b.id=c.id;
Avec une table a contenant un million de lignes, une table b n’en contenant que 1000 et une table c en contenant seulement 10, et une configuration par défaut, son plan d’exécution est celui-ci :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
b1=# EXPLAIN SELECT * FROM a JOIN b ON a.id=b.id JOIN c ON b.id=c.id;
QUERY PLAN
---------------------------------------------------------------------------
Nested Loop (cost=1.23..18341.35 rows=1 width=12)
Join Filter: (a.id = b.id)
-> Seq Scan on b (cost=0.00..15.00 rows=1000 width=4)
-> Materialize (cost=1.23..18176.37 rows=10 width=8)
-> Hash Join (cost=1.23..18176.32 rows=10 width=8)
Hash Cond: (a.id = c.id)
-> Seq Scan on a (cost=0.00..14425.00 rows=1000000 width=4)
-> Hash (cost=1.10..1.10 rows=10 width=4)
-> Seq Scan on c (cost=0.00..1.10 rows=10 width=4)
(9 rows)
Le planificateur préfère joindre tout d’ abord la table a à la table c, puis son résultat à la table b. Cela lui permet d’avoir un ensemble de données en sortie plus petit (donc moins de consommation mémoire) avant de faire la jointure avec la table b.
Cependant, si PostgreSQL se trouve face à une jointure de 25 tables, le temps de calculer tous les plans possibles en prenant en compte l’ordre des jointures sera très important. En fait, plus le nombre de tables jointes est important, et plus le temps de planification va augmenter. Il est nécessaire de prévoir une échappatoire à ce système. En fait, il en existe plusieurs. Les paramètres from_collapse_limit et join_collapse_limit permettent de spécifier une limite en nombre de tables. Si cette limite est dépassée, PostgreSQL ne cherchera plus à traiter tous les cas possibles de réordonnancement des jointures. Par défaut, ces deux paramètres valent 8, ce qui fait que, dans notre exemple, le planificateur a bien cherché à changer l’ordre des jointures. En configurant ces paramètres à une valeur plus basse, le plan va changer :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
b1=# SET join_collapse_limit TO 2;
SET
b1=# EXPLAIN SELECT * FROM a JOIN b ON a.id=b.id JOIN c ON b.id=c.id;
QUERY PLAN
---------------------------------------------------------------------
Nested Loop (cost=27.50..18363.62 rows=1 width=12)
Join Filter: (a.id = c.id)
-> Hash Join (cost=27.50..18212.50 rows=1000 width=8)
Hash Cond: (a.id = b.id)
-> Seq Scan on a (cost=0.00..14425.00 rows=1000000 width=4)
-> Hash (cost=15.00..15.00 rows=1000 width=4)
-> Seq Scan on b (cost=0.00..15.00 rows=1000 width=4)
-> Materialize (cost=0.00..1.15 rows=10 width=4)
-> Seq Scan on c (cost=0.00..1.10 rows=10 width=4)
(9 rows)
Avec un join_collapse_limit à 2, PostgreSQL décide de ne pas tester l’ordre des jointures. Le plan fourni fonctionne tout aussi bien, mais son estimation montre qu’elle semble être moins performante (coût de 18 363 au lieu de 18 341 précédemment).
Pour des requêtes avec de très nombreuses tables (décisionnel…), pour ne pas avoir à réordonner les tables dans la clause FROM, on peut monter les valeurs de join_collapse_limit ou from_collapse_limit le temps de la session ou pour un couple utilisateur/base précis. Le faire au niveau global risque de faire exploser les temps de planification d’autres requêtes.
Une autre technique mise en place pour éviter de tester tous les plans possibles est GEQO (GEnetic Query Optimizer). Cette technique est très complexe, et dispose d’un grand nombre de paramètres que très peu savent réellement configurer. Comme tout algorithme génétique, il fonctionne par introduction de mutations aléatoires sur un état initial donné. Il permet de planifier rapidement une requête complexe, et de fournir un plan d’exécution acceptable.
Malgré l’introduction de ces mutations aléatoires, le moteur arrive tout de même à conserver un fonctionnement déterministe (depuis la version 9.1, voir ce commit pour plus de détails). Tant que le paramètre geqo_seed ainsi que les autres paramètres contrôlant GEQO restent inchangés, le plan obtenu pour une requête donnée restera inchangé. Il est possible de faire varier la valeur de geqo_seed pour obtenir d’autres plans (voir la documentation officielle pour approfondir ce point).
VI-L-13. Opérations ensemblistes▲
- Prend un ou plusieurs ensembles de données en entrée.
- Et renvoie un ensemble de données.
- Concernent principalement les requêtes sur des tables partitionnées ou héritées.
-
Exemples typiques :
- Append,
- Intersect,
- Except.
Ce type de nœud prend un ou plusieurs ensembles de données en entrée et renvoie un seul ensemble de données. Cela concerne surtout les requêtes visant des tables partitionnées ou héritées.
VI-L-14. Append▲
- Prend plusieurs ensembles de données.
-
Fournit un ensemble de données en sortie :
- non trié.
-
Utilisé par les requêtes :
- sur des tables héritées (partitionnement inclus),
- ayant des UNION ALL et des UNION,
- attention que le UNION sans ALL élimine les duplicats, ce qui nécessite une opération supplémentaire de tri.
Un nœud Append a pour but de concaténer plusieurs ensembles de données pour n’en faire qu’un, non trié. Ce type de nœud est utilisé dans les requêtes concaténant explicitement des tables (clause UNION) ou implicitement (requêtes sur une table mère).
Supposons que la table t1 soit une table mère. Plusieurs tables héritent de cette table : t1_0, t1_1, t1_2 et t1_3. Voici ce que donne un SELECT sur la table mère :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
b1=# EXPLAIN SELECT * FROM t1;
QUERY PLAN
------------------------------------------------------------------------
Result (cost=0.00..89.20 rows=4921 width=36)
-> Append (cost=0.00..89.20 rows=4921 width=36)
-> Seq Scan on t1 (cost=0.00..0.00 rows=1 width=36)
-> Seq Scan on t1_0 t1 (cost=0.00..22.30 rows=1230 width=36)
-> Seq Scan on t1_1 t1 (cost=0.00..22.30 rows=1230 width=36)
-> Seq Scan on t1_2 t1 (cost=0.00..22.30 rows=1230 width=36)
-> Seq Scan on t1_3 t1 (cost=0.00..22.30 rows=1230 width=36)
(7 rows)
Nouvel exemple avec un filtre sur la clé de partitionnement :
b1=# SHOW constraint_exclusion ;
constraint_exclusion
----------------------
off
(1 row)
b1=# EXPLAIN SELECT * FROM t1 WHERE c1>250;
QUERY PLAN
-----------------------------------------------------------------------
Result (cost=0.00..101.50 rows=1641 width=36)
-> Append (cost=0.00..101.50 rows=1641 width=36)
-> Seq Scan on t1 (cost=0.00..0.00 rows=1 width=36)
Filter: (c1 > 250)
-> Seq Scan on t1_0 t1 (cost=0.00..25.38 rows=410 width=36)
Filter: (c1 > 250)
-> Seq Scan on t1_1 t1 (cost=0.00..25.38 rows=410 width=36)
Filter: (c1 > 250)
-> Seq Scan on t1_2 t1 (cost=0.00..25.38 rows=410 width=36)
Filter: (c1 > 250)
-> Seq Scan on t1_3 t1 (cost=0.00..25.38 rows=410 width=36)
Filter: (c1 > 250)
(12 rows)Le paramètre constraint_exclusion permet d’éviter de parcourir les tables filles qui ne peuvent pas accueillir les données qui nous intéressent. Pour que le planificateur comprenne qu’il peut ignorer certaines tables filles, ces dernières doivent avoir des contraintes CHECK qui assurent le planificateur qu’elles ne peuvent pas contenir les données en question :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
b1=# SHOW constraint_exclusion ;
constraint_exclusion
----------------------
on
(1 row)
b1=# EXPLAIN SELECT * FROM t1 WHERE c1>250;
QUERY PLAN
-----------------------------------------------------------------------
Result (cost=0.00..50.75 rows=821 width=36)
-> Append (cost=0.00..50.75 rows=821 width=36)
-> Seq Scan on t1 (cost=0.00..0.00 rows=1 width=36)
Filter: (c1 > 250)
-> Seq Scan on t1_2 t1 (cost=0.00..25.38 rows=410 width=36)
Filter: (c1 > 250)
-> Seq Scan on t1_3 t1 (cost=0.00..25.38 rows=410 width=36)
Filter: (c1 > 250)
(8 rows)
Une requête utilisant UNION ALL passera aussi par un nœud Append :
2.
3.
4.
5.
6.
7.
8.
b1=# EXPLAIN SELECT 1 UNION ALL SELECT 2;
QUERY PLAN
------------------------------------------------------
Result (cost=0.00..0.04 rows=2 width=4)
-> Append (cost=0.00..0.04 rows=2 width=4)
-> Result (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
(4 rows)
UNION ALL récupère toutes les lignes des deux ensembles de données, même en cas de duplicat. Pour n’avoir que les lignes distinctes, il est possible d’utiliser UNION sans la clause ALL, mais cela nécessite un tri des données pour faire la distinction (un peu comme un Merge Join).
Attention : le UNION sans ALL élimine les duplicats, ce qui nécessite une opération supplémentaire de tri :
2.
3.
4.
5.
6.
7.
8.
9.
10.
b1=# EXPLAIN SELECT 1 UNION SELECT 2;
QUERY PLAN
------------------------------------------------------------
Unique (cost=0.05..0.06 rows=2 width=0)
-> Sort (cost=0.05..0.06 rows=2 width=0)
Sort Key: (1)
-> Append (cost=0.00..0.04 rows=2 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
(6 rows)
VI-L-15. MergeAppend▲
- Append avec optimisation.
- Fournit un ensemble de données en sortie trié.
-
Utilisé par les requêtes :
- UNION ALL ou partitionnement/héritage,
- utilisant des parcours triés,
- idéal avec LIMIT.
Le nœud MergeAppend est une optimisation spécifiquement conçue pour le partitionnement, introduite en 9.1.
Cela permet de répondre plus efficacement aux requêtes effectuant un tri sur un UNION ALL, soit explicite, soit induit par un héritage/partitionnement. Considérons la requête suivante :
2.
3.
4.
5.
6.
7.
SELECT *
FROM (
SELECT t1.a, t1.b FROM t1
UNION ALL
SELECT t2.a, t2.c FROM t2
) t
ORDER BY a;
Il est facile de répondre à cette requête si l’on dispose d’un index sur les colonnes a des tables t1 et t2 : il suffit de parcourir chaque index en parallèle (assurant le tri sur a), en renvoyant la valeur la plus petite.
Pour comparaison, avant la 9.1 et l’introduction du nœud MergeAppend, le plan obtenu était celui-ci :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
QUERY PLAN
--------------------------------------------------------------------------------
Sort (cost=24129.64..24629.64 rows=200000 width=22)
(actual time=122.705..133.403 rows=200000 loops=1)
Sort Key: t1.a
Sort Method: quicksort Memory: 21770kB
-> Result (cost=0.00..6520.00 rows=200000 width=22)
(actual time=0.013..76.527 rows=200000 loops=1)
-> Append (cost=0.00..6520.00 rows=200000 width=22)
(actual time=0.012..54.425 rows=200000 loops=1)
-> Seq Scan on t1 (cost=0.00..2110.00 rows=100000 width=23)
(actual time=0.011..19.379 rows=100000 loops=1)
-> Seq Scan on t2 (cost=0.00..4410.00 rows=100000 width=22)
(actual time=1.531..22.050 rows=100000 loops=1)
Total runtime: 141.708 ms
Depuis la 9.1, l’optimiseur est capable de détecter qu’il existe un parcours paramétré, renvoyant les données triées sur la clé demandée (a), et utilise la stratégie MergeAppend :
2.
3.
4.
5.
6.
7.
8.
9.
10.
QUERY PLAN
--------------------------------------------------------------------------------
Merge Append (cost=0.72..14866.72 rows=300000 width=23)
(actual time=0.040..76.783 rows=300000 loops=1)
Sort Key: t1.a
-> Index Scan using t1_pkey on t1 (cost=0.29..3642.29 rows=100000 width=22)
(actual time=0.014..18.876 rows=100000 loops=1)
-> Index Scan using t2_pkey on t2 (cost=0.42..7474.42 rows=200000 width=23)
(actual time=0.025..35.920 rows=200000 loops=1)
Total runtime: 85.019 ms
Cette optimisation est d’autant plus intéressante si l’on utilise une clause LIMIT.
Sans MergeAppend :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
QUERY PLAN
--------------------------------------------------------------------------------
Limit (cost=9841.93..9841.94 rows=5 width=22)
(actual time=119.946..119.946 rows=5 loops=1)
-> Sort (cost=9841.93..10341.93 rows=200000 width=22)
(actual time=119.945..119.945 rows=5 loops=1)
Sort Key: t1.a
Sort Method: top-N heapsort Memory: 25kB
-> Result (cost=0.00..6520.00 rows=200000 width=22)
(actual time=0.008..75.482 rows=200000 loops=1)
-> Append (cost=0.00..6520.00 rows=200000 width=22)
(actual time=0.008..53.644 rows=200000 loops=1)
-> Seq Scan on t1
(cost=0.00..2110.00 rows=100000 width=23)
(actual time=0.006..18.819 rows=100000 loops=1)
-> Seq Scan on t2
(cost=0.00..4410.00 rows=100000 width=22)
(actual time=1.550..22.119 rows=100000 loops=1)
Total runtime: 119.976 ms
(9 lignes)
Avec MergeAppend :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
Limit (cost=0.72..0.97 rows=5 width=23)
(actual time=0.055..0.060 rows=5 loops=1)
-> Merge Append (cost=0.72..14866.72 rows=300000 width=23)
(actual time=0.053..0.058 rows=5 loops=1)
Sort Key: t1.a
-> Index Scan using t1_pkey on t1
(cost=0.29..3642.29 rows=100000 width=22)
(actual time=0.033..0.036 rows=3 loops=1)
-> Index Scan using t2_pkey on t2
(cost=0.42..7474.42 rows=200000 width=23) =
(actual time=0.019..0.021 rows=3 loops=1)
Total runtime: 0.117 ms
On voit ici que chacun des parcours d’index renvoie trois lignes, ce qui est suffisant pour renvoyer les cinq lignes ayant la plus faible valeur pour a.
VI-L-16. Autres▲
-
Nœud HashSetOp Except :
- instructions EXCEPT et EXCEPT ALL.
-
Nœud HashSetOp Intersect :
- instructions INTERSECT et INTERSECT ALL.
La clause UNION permet de concaténer deux ensembles de données. Les clauses EXCEPT et INTERSECT permettent de supprimer une partie de deux ensembles de données.
Voici un exemple basé sur EXCEPT :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
b1=# EXPLAIN SELECT oid FROM pg_proc
EXCEPT SELECT oid FROM pg_proc;
QUERY PLAN
--------------------------------------------------------------------
HashSetOp Except (cost=0.00..219.39 rows=2342 width=4)
-> Append (cost=0.00..207.68 rows=4684 width=4)
-> Subquery Scan on "*SELECT* 1"
(cost=0.00..103.84 rows=2342 width=4)
-> Seq Scan on pg_proc
(cost=0.00..80.42 rows=2342 width=4)
-> Subquery Scan on "*SELECT* 2"
(cost=0.00..103.84 rows=2342 width=4)
-> Seq Scan on pg_proc
(cost=0.00..80.42 rows=2342 width=4)
(6 rows)
Et un exemple basé sur INTERSECT :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
b1=# EXPLAIN SELECT oid FROM pg_proc
INTERSECT SELECT oid FROM pg_proc;
QUERY PLAN
--------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..219.39 rows=2342 width=4)
-> Append (cost=0.00..207.68 rows=4684 width=4)
-> Subquery Scan on "*SELECT* 1"
(cost=0.00..103.84 rows=2342 width=4)
-> Seq Scan on pg_proc
(cost=0.00..80.42 rows=2342 width=4)
-> Subquery Scan on "*SELECT* 2"
(cost=0.00..103.84 rows=2342 width=4)
-> Seq Scan on pg_proc
(cost=0.00..80.42 rows=2342 width=4)
(6 rows)
VI-L-17. Divers▲
- Prend un ensemble de données en entrée.
- Et renvoie un ensemble de données.
-
Exemples typiques :
- Sort,
- Aggregate,
- Unique,
- Limit,
- InitPlan, SubPlan.
Tous les autres nœuds que nous allons voir prennent un seul ensemble de données en entrée et en renvoient un aussi. Ce sont des nœuds d’opérations simples comme le tri, l’agrégat, l’unicité, la limite, etc.
VI-L-18. Sort▲
-
Utilisé pour le ORDER BY :
- mais aussi DISTINCT, GROUP BY, UNION,
- les jointures de type Merge Join.
- Gros délai de démarrage.
-
Trois types de tri :
- En mémoire, tri quicksort,
- En mémoire, tri top-N heapsort (si clause LIMIT),
- Sur disque.
PostgreSQL peut faire un tri de trois façons.
Les deux premières sont manuelles. Il lit toutes les données nécessaires et les trie en mémoire. La quantité de mémoire utilisable dépend du paramètre work_mem. S’il n’a pas assez de mémoire, il utilisera un stockage sur disque. La rapidité du tri dépend principalement de la mémoire utilisable, mais aussi de la puissance des processeurs. Le tri effectué est un tri quicksort sauf si une clause LIMIT existe, auquel cas le tri sera un top-N heapsort. La troisième méthode est de passer par un index Btree. En effet, ce type d’index stocke les données de façon triée. Dans ce cas, PostgreSQL n’a pas besoin de mémoire.
Le choix entre ces trois méthodes dépend principalement de work_mem. En fait, le pseudo-code ci-dessous explique ce choix :
Si les données de tri tiennent dans work_mem
Si une clause LIMIT est présente
Tri top-N heapsort
Sinon
Tri quicksort
Sinon
Tri sur disqueVoici quelques exemples :
- un tri externe :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
b1=# EXPLAIN ANALYZE SELECT 1 FROM t2 ORDER BY id;
QUERY PLAN
------------------------------------------------------------------------
Sort (cost=150385.45..153040.45 rows=1062000 width=4)
(actual time=807.603..941.357 rows=1000000 loops=1)
Sort Key: id
Sort Method: external sort Disk: 17608kB
-> Seq Scan on t2 (cost=0.00..15045.00 rows=1062000 width=4)
(actual time=0.050..143.918 rows=1000000 loops=1)
Total runtime: 1021.725 ms
(5 rows)
- un tri en mémoire :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
b1=# SET work_mem TO '100MB';
SET
b1=# EXPLAIN ANALYZE SELECT 1 FROM t2 ORDER BY id;
QUERY PLAN
------------------------------------------------------------------------
Sort (cost=121342.45..123997.45 rows=1062000 width=4)
(actual time=308.129..354.035 rows=1000000 loops=1)
Sort Key: id
Sort Method: quicksort Memory: 71452kB
-> Seq Scan on t2 (cost=0.00..15045.00 rows=1062000 width=4)
(actual time=0.088..142.787 rows=1000000 loops=1)
Total runtime: 425.160 ms
(5 rows)
- un tri en mémoire :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
b1=# EXPLAIN ANALYZE SELECT 1 FROM t2 ORDER BY id LIMIT 10000;
QUERY PLAN
------------------------------------------------------------------------
Limit (cost=85863.56..85888.56 rows=10000 width=4)
(actual time=271.674..272.980 rows=10000 loops=1)
-> Sort (cost=85863.56..88363.56 rows=1000000 width=4)
(actual time=271.671..272.240 rows=10000 loops=1)
Sort Key: id
Sort Method: top-N heapsort Memory: 1237kB
-> Seq Scan on t2 (cost=0.00..14425.00 rows=1000000 width=4)
(actual time=0.031..146.306 rows=1000000 loops=1)
Total runtime: 273.665 ms
(6 rows)
- un tri par un index :
2.
3.
4.
5.
6.
7.
8.
9.
10.
b1=# CREATE INDEX ON t2(id);
CREATE INDEX
b1=# EXPLAIN ANALYZE SELECT 1 FROM t2 ORDER BY id;
QUERY PLAN
------------------------------------------------------------------------
Index Scan using t2_id_idx on t2
(cost=0.00..30408.36 rows=1000000 width=4)
(actual time=0.145..308.651 rows=1000000 loops=1)
Total runtime: 355.175 ms
(2 rows)
Le paramètre enable_sort permet de défavoriser l’utilisation d’un tri. Dans ce cas, le planificateur tendra à préférer l’utilisation d’un index, qui retourne des données déjà triées.
Augmenter la valeur du paramètre work_mem aura l’effet inverse : favoriser un tri plutôt que l’utilisation d’un index.
VI-L-19. Aggregate▲
- Agrégat complet.
- Pour un seul résultat.
Il existe plusieurs façons de réaliser un agrégat :
- l’agrégat standard ;
- l’agrégat par tri des données ;
- et l’agrégat par hachage.
Ces deux derniers sont utilisés quand la clause SELECT contient des colonnes en plus de la fonction d’agrégat.
Par exemple, pour un seul résultat COUNT(*), nous aurons ce plan d’exécution :
2.
3.
4.
5.
6.
b1=# EXPLAIN SELECT count(*) FROM pg_proc;
QUERY PLAN
-----------------------------------------------------------------
Aggregate (cost=86.28..86.29 rows=1 width=0)
-> Seq Scan on pg_proc (cost=0.00..80.42 rows=2342 width=0)
(2 rows)
Seul le parcours séquentiel est possible ici, car COUNT() doit compter toutes les lignes.
Autre exemple avec une fonction d’agrégat max :
2.
3.
4.
5.
6.
b1=# EXPLAIN SELECT max(proname) FROM pg_proc;
QUERY PLAN
------------------------------------------------------------------
Aggregate (cost=92.13..92.14 rows=1 width=64)
-> Seq Scan on pg_proc (cost=0.00..80.42 rows=2342 width=64)
(2 rows)
Il existe une autre façon de récupérer la valeur la plus petite ou la plus grande : passer par l’index. Ce sera très rapide, car l’index est trié.
2.
3.
4.
5.
6.
7.
8.
9.
10.
b1=# EXPLAIN SELECT max(oid) FROM pg_proc;
QUERY PLAN
------------------------------------------------------------------------
Result (cost=0.13..0.14 rows=1 width=0)
InitPlan 1 (returns $0)
-> Limit (cost=0.00..0.13 rows=1 width=4)
-> Index Scan Backward using pg_proc_oid_index on pg_proc
(cost=0.00..305.03 rows=2330 width=4)
Index Cond: (oid IS NOT NULL)
(5 rows)
Il est à noter que ce n’est pas valable pour les valeurs de type booléen jusqu’en 9.2.
VI-L-20. Hash Aggregate▲
- Hachage de chaque n-uplet de regroupement (GROUP BY).
- Accès direct à chaque n-uplet pour appliquer fonction d’agrégat.
- Intéressant si l’ensemble des valeurs distinctes tient en mémoire, dangereux sinon.
Voici un exemple de ce type de nœud :
2.
3.
4.
5.
6.
b1=# EXPLAIN SELECT proname, count(*) FROM pg_proc GROUP BY proname;
QUERY PLAN
------------------------------------------------------------------
HashAggregate (cost=92.13..111.24 rows=1911 width=64)
-> Seq Scan on pg_proc (cost=0.00..80.42 rows=2342 width=64)
(2 rows)
Le hachage occupe de la place en mémoire, le plan n’est choisi que si PostgreSQL estime que si la table de hachage générée tient dans work_mem. C’est le seul type de nœud qui peut dépasser work_mem : la seule façon d’utiliser le HashAggregate est en mémoire, il est donc agrandi s’il est trop petit.
Quant au paramètre enable_hashagg, il permet d’activer et de désactiver l’utilisation de ce type de nœud.
VI-L-21. Group Aggregate▲
- Reçoit des données déjà triées.
-
Parcours des données :
- regroupement du groupe précédent arrivé à une donnée différente.
Voici un exemple de ce type de nœud :
2.
3.
4.
5.
6.
7.
8.
b1=# EXPLAIN SELECT proname, count(*) FROM pg_proc GROUP BY proname;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=211.50..248.17 rows=1911 width=64)
-> Sort (cost=211.50..217.35 rows=2342 width=64)
Sort Key: proname
-> Seq Scan on pg_proc (cost=0.00..80.42 rows=2342 width=64)
(4 rows)
Un parcours d’index est possible pour remplacer le parcours séquentiel et le tri.
VI-L-22. Unique▲
- Reçoit des données déjà triées.
-
Parcours des données :
- renvoi de la donnée précédente une fois arrivé à une donnée différente.
- Résultat trié.
Le nœud Unique permet de ne conserver que les lignes différentes. L’opération se réalise en triant les données, puis en parcourant le résultat trié. Là aussi, un index aide à accélérer ce type de nœud.
En voici un exemple :
2.
3.
4.
5.
6.
7.
8.
b1=# EXPLAIN SELECT DISTINCT pronamespace FROM pg_proc;
QUERY PLAN
-----------------------------------------------------------------------
Unique (cost=211.57..223.28 rows=200 width=4)
-> Sort (cost=211.57..217.43 rows=2343 width=4)
Sort Key: pronamespace
-> Seq Scan on sample4 (cost=0.00..80.43 rows=2343 width=4)
(4 rows)
VI-L-23. Limit▲
- Permet de limiter le nombre de résultats renvoyés.
-
Utilisé par :
- clauses LIMIT et OFFSET d’une requête SELECT,
- fonctions min() et max() quand il n’y a pas de clause WHERE et qu’il y a un index.
- Le nœud précédent sera de préférence un nœud dont le coût de démarrage est peu élevé (SeqScan, NestedLoop).
Voici un exemple de l’utilisation d’un nœud Limit :
2.
3.
4.
5.
6.
b1=# EXPLAIN SELECT 1 FROM pg_proc LIMIT 10;
QUERY PLAN
-----------------------------------------------------------------
Limit (cost=0.00..0.34 rows=10 width=0)
-> Seq Scan on pg_proc (cost=0.00..80.42 rows=2342 width=0)
(2 rows)
VI-M. Travaux pratiques▲
VI-M-1. Énoncés▲
Préambule
- Utilisez \timing dans psql pour afficher les temps d’exécution de la recherche.
- Afin d’éviter tout effet dû au cache, autant du plan que des pages de données, nous utilisons parfois une sous-requête avec un résultat non déterministe (random).
- N’oubliez pas de lancer plusieurs fois les requêtes. Vous pouvez les rappeler avec \g, ou utiliser la touche flèche haut du clavier si votre installation utilise readline ou libedit.
- Vous devrez disposer de la base cave pour ce TP.
-
Les valeurs (taille, temps d’exécution) varieront à cause de plusieurs critères :
- les machines sont différentes ;
- le jeu de données peut avoir partiellement changé depuis la rédaction du TP.
VI-M-1-a. Affichage de plans de requêtes simples▲
Recherche de motif texte
- Affichez le plan de cette requête (sur la base cave) :
SELECT*FROMappellationWHERElibelleLIKE'Brouilly%';
Que constatez-vous ?
- Affichez maintenant le nombre de blocs accédés par cette requête.
- Cette requête ne passe pas par un index. Essayez de lui forcer la main.
- L’index n’est toujours pas utilisé. L’index « par défaut » n’est pas capable de répondre à des questions sur motif.
- Créez un index capable de réaliser ces opérations. Testez à nouveau le plan.
- Réactivez enable_seqscan. Testez à nouveau le plan.
- Quelle est la conclusion ?
Recherche de motif texte avancé
La base cave ne contient pas de données textuelles appropriées, nous allons en utiliser une autre.
- Lancez textes.sql ou textes_10pct.sql (préférable sur une machine peu puissante, ou une instance PostgreSQL non paramétrée).
- psql
<textes_10pct.sql
Ce script crée une table textes, contenant le texte intégral d’un grand nombre de livres en français du projet Gutenberg, soit 10 millions de lignes pour 85 millions de mots.
Nous allons rechercher toutes les références à « Fantine » dans les textes. On devrait trouver beaucoup d’enregistrements provenant des « Misérables ».
- La méthode SQL standard pour écrire cela est :
SELECT*FROMtextesWHEREcontenu ILIKE'%fantine%';
Exécutez cette requête, et regardez son plan d’exécution.
Nous lisons toute la table à chaque fois. C’est normal et classique avec une base de données : non seulement la recherche est insensible à la casse, mais elle commence par %, ce qui est incompatible avec une indexation btree classique.
Nous allons donc utiliser l’extension pg_trgm :
- Créez un index trigramme :
2.
3.
textes=# CREATE EXTENSION pg_trgm;
CREATE INDEX idx_trgm ON textes USING gist (contenu gist_trgm_ops);
-- ou CREATE INDEX idx_trgm ON textes USING gin (contenu gin_trgm_ops);
- Quelle est la taille de l’index ?
- Réexécutez la requête. Que constatez-vous ?
- Suivant que vous ayez opté pour GiST ou GIN, refaites la manipulation avec l’autre méthode d’indexation.
- Essayez de créer un index « Full Text » à la place de l’index trigramme. Quels sont les résultats ?
Optimisation d’une requête
Schéma de la base cave
|
|
Optimisation 1
Nous travaillerons sur la requête contenue dans le fichier requete1.sql pour cet exercice :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
-- \timing
-- explain analyze
select
m.annee||' - '||a.libelle as millesime_region,
sum(s.nombre) as contenants,
sum(s.nombre*c.contenance) as litres
from
contenant c
join stock s
on s.contenant_id = c.id
join (select round(random()*50)+1950 as annee) m
on s.annee = m.annee
join vin v
on s.vin_id = v.id
left join appellation a
on v.appellation_id = a.id
group by m.annee||' - '||a.libelle;
- Exécuter la requête telle quelle et noter le plan et le temps d’exécution.
- Créer un index sur la colonne stock.annee.
- Exécuter la requête juste après la création de l’index.
- Faire un ANALYZE stock.
- Exécuter à nouveau la requête.
- Interdire à PostgreSQL les sequential scans avec la commande set enable_seqscan to off; dans votre session dans psql.
- Exécuter à nouveau la requête.
- Tenter de réécrire la requête pour l’optimiser.
Optimisation 2
L’exercice nous a amenés à la réécriture de la requête.
- Voici la requête que nous avons à présent :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
explain analyze
select
s.annee||' - '||a.libelle as millesime_region,
sum(s.nombre) as contenants,
sum(s.nombre*c.contenance) as litres
from
contenant c
join stock s
on s.contenant_id = c.id
join vin v
on s.vin_id = v.id
left join appellation a
on v.appellation_id = a.id
where s.annee = (select round(random()*50)+1950 as annee)
group by s.annee||' - '||a.libelle;
Cette écriture n’est pas optimale, pourquoi ?
Indices
- Vérifiez le schéma de données de la base cave.
- Faites les requêtes de vérification nécessaires pour vous assurer que vous avez bien trouvé une anomalie dans la requête.
- Réécrivez la requête une nouvelle fois et faites un EXPLAIN ANALYZE pour vérifier que le plan d’exécution est plus simple et plus rapide avec cette nouvelle écriture.
Optimisation 3
Un dernier problème existe dans cette requête. Il n’est visible qu’en observant le plan d’exécution de la requête précédente.
Indice
Cherchez une opération présente dans le plan qui n’apparaît pas dans la requête. Comment modifier la requête pour éviter cette opération ?
Corrélation entre colonnes
- Importez le fichier correlations.sql.
Dans la table villes, on trouve les villes et leur code postal. Ces colonnes sont très fortement corrélées, mais pas identiques : plusieurs villes peuvent partager le même code postal, et une ville peut avoir plusieurs codes postaux. On peut aussi, bien sûr, avoir plusieurs villes avec le même nom, mais pas le même code postal (dans des départements différents par exemple). Pour obtenir la liste des villes pouvant poser problème :
2.
3.
4.
5.
6.
7.
8.
9.
10.
SELECT *
FROM villes
WHERE localite IN
(SELECT localite
FROM villes
GROUP BY localite HAVING count(*) >1)
AND codepostal IN
(SELECT codepostal
FROM villes
GROUP BY codepostal HAVING count(*) >1);
Avec cette requête, on récupère toutes les villes ayant plusieurs occurrences et dont au moins une possède un code postal partagé. Ces villes ont donc besoin du code postal ET du nom pour être identifiées.
Un exemple de requête problématique est le suivant :
2.
3.
4.
5.
SELECT * FROM colis
WHERE id_ville IN
(SELECT id_ville FROM villes
WHERE localite ='PARIS'
AND codepostal LIKE '75%')
- Exécutez cette requête, et regardez son plan d’exécution. Où est le problème ?
- Exécutez cette requête sans la dernière clause AND codepostal LIKE '75%'. Que constatez-vous ?
- Quelle solution pourrait-on adopter, si on doit réellement spécifier ces deux conditions ?
VI-M-1-b. Solutions▲
Affichage de plans de requêtes simples
Recherche de motif texte
- Affichez le plan de cette requête (sur la base cave).
SELECT*FROMappellationWHERElibelleLIKE'Brouilly%';
2.
3.
4.
5.
6.
cave=# explain SELECT * FROM appellation WHERE libelle LIKE 'Brouilly%';
QUERY PLAN
------------------------------------------------------------
Seq Scan on appellation (cost=0.00..6.99 rows=1 width=24)
Filter: (libelle ~~ 'Brouilly%'::text)
(2 lignes)
Que constatez-vous ?
- Affichez maintenant le nombre de blocs accédés par cette requête.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
cave=# explain (analyze,buffers) SELECT * FROM appellation
cave=# WHERE libelle LIKE 'Brouilly%';
QUERY PLAN
--------------------------------------------------------------------------------
Seq Scan on appellation (cost=0.00..6.99 rows=1 width=24)
(actual time=0.066..0.169 rows=1 loops=1)
Filter: (libelle ~~ 'Brouilly%'::text)
Rows Removed by Filter: 318
Buffers: shared hit=3
Total runtime: 0.202 ms
(5 lignes)
- Cette requête ne passe pas par un index. Essayez de lui forcer la main.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
cave=# set enable_seqscan TO off;
SET
cave=# explain (analyze,buffers) SELECT * FROM appellation
cave=# WHERE libelle LIKE 'Brouilly%';
QUERY PLAN
--------------------------------------------------------------------------------
Seq Scan on appellation (cost=10000000000.00..10000000006.99 rows=1 width=24)
(actual time=0.073..0.197 rows=1 loops=1)
Filter: (libelle ~~ 'Brouilly%'::text)
Rows Removed by Filter: 318
Buffers: shared hit=3
Total runtime: 0.238 ms
(5 lignes)
Passer enable_seqscan à off n’interdit pas l’utilisation des scans séquentiels. Il ne fait que les défavoriser fortement : regardez le coût estimé du scan séquentiel.
- L’index n’est toujours pas utilisé. L’index « par défaut » n’est pas capable de répondre à des questions sur motif.
En effet, l’index par défaut trie les données par la collation de la colonne de la table. Il lui est impossible de savoir que libelle LIKE 'Brouilly%' est équivalent à libelle >= 'Brouilly' AND libelle < 'Brouillz'. Ce genre de transformation n’est d’ailleurs pas forcément trivial, ni même possible. Il existe dans certaines langues des équivalences (ß et ss en allemand par exemple) qui rendent ce genre de transformation au mieux hasardeuse.
- Créez un index capable de ces opérations. Testez à nouveau le plan.
Pour pouvoir répondre à cette question, on doit donc avoir un index spécialisé, qui compare les chaînes non plus par rapport à leur collation, mais à leur valeur binaire (octale en fait).
2.
CREATE INDEX appellation_libelle_key_search
ON appellation (libelle text_pattern_ops);
On indique par cette commande à PostgreSQL de ne plus utiliser la classe d’opérateurs habituelle de comparaison de texte, mais la classe text_pattern_ops, qui est spécialement faite pour les recherches LIKE 'xxxx%' : cette classe ne trie plus les chaînes par leur ordre alphabétique, mais par leur valeur octale.
Si on redemande le plan :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
cave=# EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM appellation
cave=# WHERE libelle LIKE 'Brouilly%';
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using appellation_libelle_key_search on appellation
(cost=0.27..8.29 rows=1 width=24)
(actual time=0.057..0.059 rows=1 loops=1)
Index Cond: ((libelle ~>=~ 'Brouilly'::text)
AND (libelle ~<~ 'Brouillz'::text))
Filter: (libelle ~~ 'Brouilly%'::text)
Buffers: shared hit=1 read=2
Total runtime: 0.108 ms
(5 lignes)
On utilise enfin un index.
- Réactivez enable_seqscan. Testez à nouveau le plan.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
cave=# reset enable_seqscan ;
RESET
cave=# explain (analyze,buffers) SELECT * FROM appellation
cave=# WHERE libelle LIKE 'Brouilly%';
QUERY PLAN
--------------------------------------------------------------------------------
Seq Scan on appellation (cost=0.00..6.99 rows=1 width=24)
(actual time=0.063..0.172 rows=1 loops=1)
Filter: (libelle ~~ 'Brouilly%'::text)
Rows Removed by Filter: 318
Buffers: shared hit=3
Total runtime: 0.211 ms
(5 lignes)
- Quelle est la conclusion ?
PostgreSQL choisit de ne pas utiliser cet index. Le temps d’exécution est pourtant un peu meilleur avec l’index (60 microsecondes contre 172 microsecondes). Néanmoins, cela n’est vrai que parce que les données sont en cache. En cas de données hors du cache, le plan par parcours séquentiel (Seq Scan) est probablement meilleur. Certes il prend plus de temps CPU puisqu’il doit consulter 318 enregistrements inutiles. Par contre, il ne fait qu’un accès à 3 blocs séquentiels (les 3 blocs de la table), ce qui est le plus sûr.
La table est trop petite pour que PostgreSQL considère l’utilisation d’un index.
Recherche de motif texte avancé
La base cave ne contient pas de données textuelles appropriées, nous allons en utiliser une autre.
- Lancez textes.sql ou textes_10pct.sql (préférable sur une machine peu puissante, ou une instance PostgreSQL non paramétrée).
psql < textes.sql
Ce script crée une table textes, contenant le texte intégral d’un grand nombre de livres en français du projet Gutenberg, soit 10 millions de lignes pour 85 millions de mots.
Nous allons rechercher toutes les références à « Fantine » dans les textes. On devrait trouver beaucoup d’enregistrements provenant des « Misérables ».
- La méthode SQL standard pour écrire cela est :
SELECT*FROMtextesWHEREcontenu ILIKE'%fantine%';
Exécutez cette requête, et regardez son plan d’exécution.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
textes=# explain (analyze,buffers) SELECT * FROM textes
textes=# WHERE contenu ILIKE '%fantine%';
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------
Seq Scan on textes (cost=0.00..325809.40 rows=874 width=102)
(actual time=224.634..22567.231 rows=921 loops=1)
Filter: (contenu ~~* '%fantine%'::text)
Rows Removed by Filter: 11421523
Buffers: shared hit=130459 read=58323
Total runtime: 22567.679 ms
(5 lignes)
Cette requête ne peut pas être optimisée avec les index standard (btree) : c’est une recherche insensible à la casse et avec plusieurs % dont un au début.
Avec GiST
- Créez un index trigramme:
2.
3.
4.
5.
textes=# CREATE EXTENSION pg_trgm;
textes=# CREATE INDEX idx_trgm ON textes USING gist (contenu gist_trgm_ops);
CREATE INDEX
Temps : 962794,399 ms
- Quelle est la taille de l’index ?
L’index fait cette taille (pour une table de 1,5 Go) :
2.
3.
4.
5.
textes=# select pg_size_pretty(pg_relation_size('idx_trgm'));
pg_size_pretty
----------------
2483 MB
(1 ligne)
- Réexécutez la requête. Que constatez-vous ?
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
textes=# explain (analyze,buffers) SELECT * FROM textes
textes=# WHERE contenu ILIKE '%fantine%';
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on textes (cost=111.49..3573.39 rows=912 width=102)
(actual time=1942.872..1949.393 rows=922 loops=1)
Recheck Cond: (contenu ~~* '%fantine%'::text)
Rows Removed by Index Recheck: 75
Buffers: shared hit=16030 read=144183 written=14741
-> Bitmap Index Scan on idx_trgm (cost=0.00..111.26 rows=912 width=0)
(actual time=1942.671..1942.671 rows=997 loops=1)
Index Cond: (contenu ~~* '%fantine%'::text)
Buffers: shared hit=16029 read=143344 written=14662
Total runtime: 1949.565 ms
(8 lignes)
Temps : 1951,175 ms
PostgreSQL dispose de mécanismes spécifiques avancés pour certains types de données. Ils ne sont pas toujours installés en standard, mais leur connaissance peut avoir un impact énorme sur les performances.
Le mécanisme GiST est assez efficace pour répondre à ce genre de questions. Il nécessite quand même un accès à un grand nombre de blocs, d’après le plan : 160 000 blocs lus, 15 000 écrits (dans un fichier temporaire, on pourrait s’en débarrasser en augmentant le work_mem). Le gain est donc important, mais pas gigantesque : le plan initial lisait 190 000 blocs. On gagne surtout en temps de calcul, car on accède directement aux bons enregistrements. Le parcours de l’index, par contre, est coûteux.
Avec GIN
- Créez un index trigramme :
2.
3.
4.
5.
textes=# CREATE EXTENSION pg_trgm;
textes=# CREATE INDEX idx_trgm ON textes USING gin (contenu gin_trgm_ops);
CREATE INDEX
Temps : 591534,917 ms
L’index fait cette taille (pour une table de 1,5Go) :
textes=# select pg_size_pretty(pg_total_relation_size('textes'));
pg_size_pretty
----------------
4346 MB
(1 ligne)L’index est très volumineux.
- Réexécutez la requête. Que constatez-vous ?
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
textes=# explain (analyze,buffers) SELECT * FROM textes
textes=# WHERE contenu ILIKE '%fantine%';
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on textes (cost=103.06..3561.22 rows=911 width=102)
(actual time=777.469..780.834 rows=921 loops=1)
Recheck Cond: (contenu ~~* '%fantine%'::text)
Rows Removed by Index Recheck: 75
Buffers: shared hit=2666
-> Bitmap Index Scan on idx_trgm (cost=0.00..102.83 rows=911 width=0)
(actual time=777.283..777.283 rows=996 loops=1)
Index Cond: (contenu ~~* '%fantine%'::text)
Buffers: shared hit=1827
Total runtime: 780.954 ms
(8 lignes)
PostgreSQL dispose de mécanismes spécifiques avancés pour certains types de données. Ils ne sont pas toujours installés en standard, mais leur connaissance peut avoir un impact énorme sur les performances. Le mécanisme GIN est vraiment très efficace pour répondre à ce genre de questions. Il s’agit de répondre en moins d’une seconde à « quelles lignes contiennent la chaîne “fantine” ? » sur 12 millions de lignes de texte. Les index GIN sont par contre très coûteux à maintenir. Ici, on n’accède qu’à 2 666 blocs, ce qui est vraiment excellent. Mais l’index est bien plus volumineux que l’index GiST.
Avec le Full Text Search
Le résultat sera bien sûr différent, et le FTS est moins souple.
Version GiST :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
textes=# create index idx_fts
on textes
using gist (to_tsvector('french',contenu));
CREATE INDEX
Temps : 1807467,811 ms
textes=# EXPLAIN (analyze,buffers) SELECT * FROM textes
textes=# WHERE to_tsvector('french',contenu) @@ to_tsquery('french','fantine');
QUERY PLAN
------------------------------------------------------------------------
Bitmap Heap Scan on textes (cost=2209.51..137275.87 rows=63109 width=97)
(actual time=648.596..659.733 rows=311 loops=1)
Recheck Cond: (to_tsvector('french'::regconfig, contenu) @@
'''fantin'''::tsquery)
Buffers: shared hit=37165
-> Bitmap Index Scan on idx_fts (cost=0.00..2193.74 rows=63109 width=0)
(actual time=648.493..648.493 rows=311 loops=1)
Index Cond: (to_tsvector('french'::regconfig, contenu) @@
'''fantin'''::tsquery)
Buffers: shared hit=37016
Total runtime: 659.820 ms
(7 lignes)
Temps : 660,364 ms
Et la taille de l’index :
textes=# select pg_size_pretty(pg_relation_size('idx_fts'));
pg_size_pretty
----------------
671 MB
(1 ligne)Version GIN :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
textes=# CREATE INDEX idx_fts ON textes
textes=# USING gin (to_tsvector('french',contenu));
CREATE INDEX
Temps : 491499,599 ms
textes=# EXPLAIN (analyze,buffers) SELECT * FROM textes
textes=# WHERE to_tsvector('french',contenu) @@ to_tsquery('french','fantine');
QUERY PLAN
------------------------------------------------------------------------------
Bitmap Heap Scan on textes (cost=693.10..135759.45 rows=63109 width=97)
(actual time=0.278..0.699 rows=311 loops=1)
Recheck Cond: (to_tsvector('french'::regconfig, contenu) @@
'''fantin'''::tsquery)
Buffers: shared hit=153
-> Bitmap Index Scan on idx_fts (cost=0.00..677.32 rows=63109 width=0)
(actual time=0.222..0.222 rows=311 loops=1)
Index Cond: (to_tsvector('french'::regconfig, contenu) @@
'''fantin'''::tsquery)
Buffers: shared hit=4
Total runtime: 0.793 ms
(7 lignes)
Temps : 1,534 ms
Taille de l’index :
textes=# select pg_size_pretty(pg_relation_size('idx_fts'));
pg_size_pretty
----------------
593 MB
(1 ligne)
On constate donc que le Full Text Search est bien plus efficace que le trigramme, du moins pour le Full Text Search + GIN : trouver 1 mot parmi plus de 100 millions, dans 300 endroits différents, dure 1,5 ms.
Par contre, le trigramme permet des recherches floues (orthographe approximative), et des recherches sur autre chose que des mots, même si ces points ne sont pas abordés ici.
Optimisation d’une requête
Optimisation 1
Nous travaillerons sur la requête contenue dans le fichier requete1.sql pour cet exercice :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
-- \timing
-- explain analyze
select
m.annee||' - '||a.libelle as millesime_region,
sum(s.nombre) as contenants,
sum(s.nombre*c.contenance) as litres
from
contenant c
join stock s
on s.contenant_id = c.id
join (select round(random()*50)+1950 as annee) m
on s.annee = m.annee
join vin v
on s.vin_id = v.id
left join appellation a
on v.appellation_id = a.id
group by m.annee||' - '||a.libelle;
L’exécution de la requête donne le plan suivant, avec un temps qui peut varier en fonction de la machine utilisée et de son activité:
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
HashAggregate (cost=12763.56..12773.13 rows=319 width=32)
(actual time=1542.472..1542.879 rows=319 loops=1)
-> Hash Left Join (cost=184.59..12741.89 rows=2889 width=32)
(actual time=180.263..1520.812 rows=11334 loops=1)
Hash Cond: (v.appellation_id = a.id)
-> Hash Join (cost=174.42..12663.10 rows=2889 width=20)
(actual time=179.426..1473.270 rows=11334 loops=1)
Hash Cond: (s.contenant_id = c.id)
-> Hash Join (cost=173.37..12622.33 rows=2889 width=20)
(actual time=179.401..1446.687 rows=11334 loops=1)
Hash Cond: (s.vin_id = v.id)
-> Hash Join (cost=0.04..12391.22 rows=2889 width=20)
(actual time=164.388..1398.643 rows=11334 loops=1)
Hash Cond: ((s.annee)::double precision =
((round((random() * 50::double precision)) +
1950::double precision)))
-> Seq Scan on stock s
(cost=0.00..9472.86 rows=577886 width=16)
(actual time=0.003..684.039 rows=577886 loops=1)
-> Hash (cost=0.03..0.03 rows=1 width=8)
(actual time=0.009..0.009 rows=1 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Result (cost=0.00..0.02 rows=1 width=0)
(actual time=0.005..0.006 rows=1 loops=1)
-> Hash (cost=97.59..97.59 rows=6059 width=8)
(actual time=14.987..14.987 rows=6059 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 237kB
-> Seq Scan on vin v
(cost=0.00..97.59 rows=6059 width=8)
(actual time=0.009..7.413 rows=6059 loops=1)
-> Hash (cost=1.02..1.02 rows=2 width=8)
(actual time=0.013..0.013 rows=2 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Seq Scan on contenant c
(cost=0.00..1.02 rows=2 width=8)
(actual time=0.003..0.005 rows=2 loops=1)
-> Hash (cost=6.19..6.19 rows=319 width=20)
(actual time=0.806..0.806 rows=319 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 17kB
-> Seq Scan on appellation a
(cost=0.00..6.19 rows=319 width=20)
(actual time=0.004..0.379 rows=319 loops=1)
Total runtime: 1543.242 ms
(23 rows)
Nous créons à présent un index sur stock.annee comme suit :
create index stock_annee on stock (annee) ;
Et exécutons à nouveau la requête. Hélas nous constatons que rien ne change, ni le plan, ni le temps pris par la requête.
Nous n’avons pas lancé ANALYZE, cela explique que l’optimiseur n’utilise pas l’index : il n’en a pas encore la connaissance.
ANALYZE STOCK ;
Le plan n’a toujours pas changé ! Ni le temps d’exécution !
Interdisons donc de faire les Seq scans à l’optimiseur :
SET ENABLE_SEQSCAN TO OFF;
Nous remarquons que le plan d’exécution est encore pire :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
HashAggregate (cost=40763.39..40772.96 rows=319 width=32)
(actual time=2022.971..2023.390 rows=319 loops=1)
-> Hash Left Join (cost=313.94..40741.72 rows=2889 width=32)
(actual time=18.149..1995.889 rows=11299 loops=1)
Hash Cond: (v.appellation_id = a.id)
-> Hash Join (cost=290.92..40650.09 rows=2889 width=20)
(actual time=17.172..1937.644 rows=11299 loops=1)
Hash Cond: (s.vin_id = v.id)
-> Nested Loop (cost=0.04..40301.43 rows=2889 width=20)
(actual time=0.456..1882.531 rows=11299 loops=1)
Join Filter: (s.contenant_id = c.id)
-> Hash Join (cost=0.04..40202.48 rows=2889 width=20)
(actual time=0.444..1778.149 rows=11299 loops=1)
Hash Cond: ((s.annee)::double precision =
((round((random() * 50::double precision)) +
1950::double precision)))
-> Index Scan using stock_pkey on stock s
(cost=0.00..37284.12 rows=577886 width=16)
(actual time=0.009..1044.061 rows=577886 loops=1)
-> Hash (cost=0.03..0.03 rows=1 width=8)
(actual time=0.011..0.011 rows=1 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Result (cost=0.00..0.02 rows=1 width=0)
(actual time=0.005..0.006 rows=1 loops=1)
-> Materialize (cost=0.00..12.29 rows=2 width=8)
(actual time=0.001..0.003 rows=2 loops=11299)
-> Index Scan using contenant_pkey on contenant c
(cost=0.00..12.28 rows=2 width=8)
(actual time=0.004..0.010 rows=2 loops=1)
-> Hash (cost=215.14..215.14 rows=6059 width=8)
(actual time=16.699..16.699 rows=6059 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 237kB
-> Index Scan using vin_pkey on vin v
(cost=0.00..215.14 rows=6059 width=8)
(actual time=0.010..8.871 rows=6059 loops=1)
-> Hash (cost=19.04..19.04 rows=319 width=20)
(actual time=0.936..0.936 rows=319 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 17kB
-> Index Scan using appellation_pkey on appellation a
(cost=0.00..19.04 rows=319 width=20)
(actual time=0.016..0.461 rows=319 loops=1)
Total runtime: 2023.742 ms
(22 rows)
Que faire alors ?
Il convient d’autoriser à nouveau les Seq scans, puis, peut-être, de réécrire la requête.
Nous réécrivons la requête comme suit (fichier requete2.sql) :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
explain analyze
select
s.annee||' - '||a.libelle as millesime_region,
sum(s.nombre) as contenants,
sum(s.nombre*c.contenance) as litres
from
contenant c
join stock s
on s.contenant_id = c.id
join vin v
on s.vin_id = v.id
left join appellation a
on v.appellation_id = a.id
where s.annee = (select round(random()*50)+1950 as annee)
group by s.annee||' - '||a.libelle;
Il y a une jointure en moins, ce qui est toujours appréciable. Nous pouvons faire cette réécriture parce que la requête select round(random()*50)+1950 as annee ne ramène qu’un seul enregistrement.
Voici le résultat :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
HashAggregate (cost=12734.64..12737.10 rows=82 width=28)
(actual time=265.899..266.317 rows=319 loops=1)
InitPlan 1 (returns $0)
-> Result (cost=0.00..0.02 rows=1 width=0)
(actual time=0.005..0.006 rows=1 loops=1)
-> Hash Left Join (cost=184.55..12712.96 rows=2889 width=28)
(actual time=127.787..245.314 rows=11287 loops=1)
Hash Cond: (v.appellation_id = a.id)
-> Hash Join (cost=174.37..12634.17 rows=2889 width=16)
(actual time=126.950..208.077 rows=11287 loops=1)
Hash Cond: (s.contenant_id = c.id)
-> Hash Join (cost=173.33..12593.40 rows=2889 width=16)
(actual time=126.925..181.867 rows=11287 loops=1)
Hash Cond: (s.vin_id = v.id)
-> Seq Scan on stock s
(cost=0.00..12362.29 rows=2889 width=16)
(actual time=112.101..135.932 rows=11287 loops=1)
Filter: ((annee)::double precision = $0)
-> Hash (cost=97.59..97.59 rows=6059 width=8)
(actual time=14.794..14.794 rows=6059 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 237kB
-> Seq Scan on vin v
(cost=0.00..97.59 rows=6059 width=8)
(actual time=0.010..7.321 rows=6059 loops=1)
-> Hash (cost=1.02..1.02 rows=2 width=8)
(actual time=0.013..0.013 rows=2 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Seq Scan on contenant c
(cost=0.00..1.02 rows=2 width=8)
(actual time=0.004..0.006 rows=2 loops=1)
-> Hash (cost=6.19..6.19 rows=319 width=20)
(actual time=0.815..0.815 rows=319 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 17kB
-> Seq Scan on appellation a
(cost=0.00..6.19 rows=319 width=20)
(actual time=0.004..0.387 rows=319 loops=1)
Total runtime: 266.663 ms
(21 rows)
Nous sommes ainsi passés de 2 s à 250 ms : la requête est donc environ 10 fois plus rapide.
Que peut-on conclure de cet exercice ?
- que la création d’un index est une bonne idée ; cependant l’optimiseur peut ne pas l’utiliser, pour de bonnes raisons ;
- qu’interdire les Seq scan est toujours une mauvaise idée (ne présumez pas de votre supériorité sur l’optimiseur !).
Optimisation 2
Voici la requête 2 telle que nous l’avons trouvée dans l’exercice précédent :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
explain analyze
select
s.annee||' - '||a.libelle as millesime_region,
sum(s.nombre) as contenants,
sum(s.nombre*c.contenance) as litres
from
contenant c
join stock s
on s.contenant_id = c.id
join vin v
on s.vin_id = v.id
left join appellation a
on v.appellation_id = a.id
where s.annee = (select round(random()*50)+1950 as annee)
group by s.annee||' - '||a.libelle;
On peut se demander si la jointure externe (LEFT JOIN) est fondée… On va donc vérifier l’utilité de la ligne suivante :
vin v left join appellation a on v.appellation_id = a.id
Cela se traduit par « récupérer tous les tuples de la table vin, et pour chaque correspondance dans appellation, la récupérer, si elle existe ».
En regardant la description de la table vin (\d vin dans psql), on remarque la contrainte de clé étrangère suivante :
2.
3.
« vin_appellation_id_fkey »
FOREIGN KEY (appellation_id)
REFERENCES appellation(id)
Cela veut dire qu’on a la certitude que pour chaque vin, si une référence à la table appellation est présente, elle est nécessairement vérifiable.
De plus, on remarque :
appellation_id | integer | not null
Ce qui veut dire que la valeur de ce champ ne peut être nulle. Elle contient donc obligatoirement une valeur qui est présente dans la table appellation.
On peut vérifier au niveau des tuples en faisant un COUNT(*) du résultat, une fois en INNER JOIN et une fois en LEFT JOIN. Si le résultat est identique, la jointure externe ne sert à rien :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
select count(*)
from vin v
inner join appellation a on (v.appellation_id = a.id);
count
-------
6057
select count(*)
from vin v
left join appellation a on (v.appellation_id = a.id);
count
-------
6057
On peut donc réécrire la requête 2 sans la jointure externe inutile, comme on vient de le démontrer :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
explain analyze
select
s.annee||' - '||a.libelle as millesime_region,
sum(s.nombre) as contenants,
sum(s.nombre*c.contenance) as litres
from
contenant c
join stock s
on s.contenant_id = c.id
join vin v
on s.vin_id = v.id
join appellation a
on v.appellation_id = a.id
where s.annee = (select round(random()*50)+1950 as annee)
group by s.annee||' - '||a.libelle;
Voici le résultat :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
HashAggregate (cost=12734.64..12737.10 rows=82 width=28)
(actual time=266.916..267.343 rows=319 loops=1)
InitPlan 1 (returns $0)
-> Result (cost=0.00..0.02 rows=1 width=0)
(actual time=0.005..0.006 rows=1 loops=1)
-> Hash Join (cost=184.55..12712.96 rows=2889 width=28)
(actual time=118.759..246.391 rows=11299 loops=1)
Hash Cond: (v.appellation_id = a.id)
-> Hash Join (cost=174.37..12634.17 rows=2889 width=16)
(actual time=117.933..208.503 rows=11299 loops=1)
Hash Cond: (s.contenant_id = c.id)
-> Hash Join (cost=173.33..12593.40 rows=2889 width=16)
(actual time=117.914..182.501 rows=11299 loops=1)
Hash Cond: (s.vin_id = v.id)
-> Seq Scan on stock s
(cost=0.00..12362.29 rows=2889 width=16)
(actual time=102.903..135.451 rows=11299 loops=1)
Filter: ((annee)::double precision = $0)
-> Hash (cost=97.59..97.59 rows=6059 width=8)
(actual time=14.979..14.979 rows=6059 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 237kB
-> Seq Scan on vin v
(cost=0.00..97.59 rows=6059 width=8)
(actual time=0.010..7.387 rows=6059 loops=1)
-> Hash (cost=1.02..1.02 rows=2 width=8)
(actual time=0.009..0.009 rows=2 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Seq Scan on contenant c
(cost=0.00..1.02 rows=2 width=8)
(actual time=0.002..0.004 rows=2 loops=1)
-> Hash (cost=6.19..6.19 rows=319 width=20)
(actual time=0.802..0.802 rows=319 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 17kB
-> Seq Scan on appellation a
(cost=0.00..6.19 rows=319 width=20)
(actual time=0.004..0.397 rows=319 loops=1)
Total runtime: 267.688 ms
(21 rows)
Cette réécriture n’a pas d’effet sur le temps d’exécution de la requête dans notre cas. Mais il est probable qu’avec des cardinalités différentes dans la base, cette réécriture aurait eu un impact. Remplacer un LEFT JOIN par un JOIN est le plus souvent intéressant, car il laisse davantage de liberté au moteur sur le sens de planification des requêtes.
Optimisation 3
Si on observe attentivement le plan, on constate qu’on a toujours le parcours séquentiel de la table stock, qui est notre plus grosse table. Pourquoi a-t-il lieu ?
Si on regarde le filtre (ligne Filter) du parcours de la table stock, on constate qu’il est écrit :
Filter: ((annee)::double precision = $0)
Ceci signifie que pour tous les enregistrements de la table, l’année est convertie en nombre en double précision (un nombre à virgule flottante), afin d’être comparée à $0, une valeur filtre appliquée à la table. Cette valeur est le résultat du calcul :
select round(random()*50)+1950 as annee
comme indiquée par le début du plan (les lignes de l’initplan 1).
Pourquoi compare-t-il l’année, déclarée comme un entier (integer), en la convertissant en un nombre à virgule flottante ?
Parce que la fonction round() retourne un nombre à virgule flottante. La somme d’un nombre à virgule flottante et d’un entier est évidemment un nombre à virgule flottante. Si on veut que la fonction round() retourne un entier, il faut forcer explicitement sa conversion, via CAST(xxx as int) ou ::int.
Réécrivons encore une fois cette requête :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
explain analyze
select
s.annee||' - '||a.libelle as millesime_region,
sum(s.nombre) as contenants,
sum(s.nombre*c.contenance) as litres
from
contenant c
join stock s
on s.contenant_id = c.id
join vin v
on s.vin_id = v.id
join appellation a
on v.appellation_id = a.id
where s.annee = (select cast(round(random()*50) as int)+1950 as annee)
group by s.annee||' - '||a.libelle;
Voici son plan :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
HashAggregate (cost=1251.12..1260.69 rows=319 width=28)
(actual time=138.418..138.825 rows=319 loops=1)
InitPlan 1 (returns $0)
-> Result (cost=0.00..0.02 rows=1 width=0)
(actual time=0.005..0.006 rows=1 loops=1)
-> Hash Join (cost=267.86..1166.13 rows=11329 width=28)
(actual time=31.108..118.193 rows=11389 loops=1)
Hash Cond: (s.contenant_id = c.id)
-> Hash Join (cost=266.82..896.02 rows=11329 width=28)
(actual time=31.071..80.980 rows=11389 loops=1)
Hash Cond: (s.vin_id = v.id)
-> Index Scan using stock_annee on stock s
(cost=0.00..402.61 rows=11331 width=16)
(actual time=0.049..17.191 rows=11389 loops=1)
Index Cond: (annee = $0)
-> Hash (cost=191.08..191.08 rows=6059 width=20)
(actual time=31.006..31.006 rows=6059 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 313kB
-> Hash Join (cost=10.18..191.08 rows=6059 width=20)
(actual time=0.814..22.856 rows=6059 loops=1)
Hash Cond: (v.appellation_id = a.id)
-> Seq Scan on vin v
(cost=0.00..97.59 rows=6059 width=8)
(actual time=0.005..7.197 rows=6059 loops=1)
-> Hash (cost=6.19..6.19 rows=319 width=20)
(actual time=0.800..0.800 rows=319 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 17kB
-> Seq Scan on appellation a
(cost=0.00..6.19 rows=319 width=20)
(actual time=0.002..0.363 rows=319 loops=1)
-> Hash (cost=1.02..1.02 rows=2 width=8)
(actual time=0.013..0.013 rows=2 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Seq Scan on contenant c (cost=0.00..1.02 rows=2 width=8)
(actual time=0.003..0.006 rows=2 loops=1)
Total runtime: 139.252 ms
(21 rows)
On constate qu’on utilise enfin l’index de stock. Le temps d’exécution a encore été divisé par deux.
N.B. : Ce problème d’incohérence de type était la cause du plus gros ralentissement de la requête. En reprenant la requête initiale, et en ajoutant directement le cast, la requête s’exécute déjà en 160 millisecondes.
Corrélation entre colonnes
Importez le fichier correlations.sql.
createdb correlations
psql correlations < correlations.sql- Exécutez cette requête, et regardez son plan d’exécution. Où est le problème ?
Cette requête a été exécutée dans un environnement où le cache a été intégralement vidé, pour être dans la situation la plus défavorable possible. Vous obtiendrez probablement des performances meilleures, surtout si vous réexécutez cette requête.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
explain (analyze,buffers)
SELECT * FROM colis WHERE id_ville IN (
SELECT id_ville
FROM villes
WHERE localite ='PARIS'
AND codepostal LIKE '75%'
);
QUERY PLAN
--------------------------------------------------------------------------------
Nested Loop (cost=6.75..13533.81 rows=3265 width=16)
(actual time=38.020..364383.516 rows=170802 loops=1)
Buffers: shared hit=91539 read=82652
I/O Timings: read=359812.828
-> Seq Scan on villes (cost=0.00..1209.32 rows=19 width=
(actual time=23.979..45.383 rows=940 loops=1)
Filter: ((codepostal ~~ '75%'::text) AND (localite = 'PARIS'::text))
Rows Removed by Filter: 54015
Buffers: shared hit=1 read=384
I/O Timings: read=22.326
-> Bitmap Heap Scan on colis (cost=6.75..682.88 rows=181 width=16)
(actual time=1.305..387.239 rows=182 loops=940)
Recheck Cond: (id_ville = villes.id_ville)
Buffers: shared hit=91538 read=82268
I/O Timings: read=359790.502
-> Bitmap Index Scan on idx_colis_ville
(cost=0.00..6.70 rows=181 width=0)
(actual time=0.115..0.115 rows=182 loops=940)
Index Cond: (id_ville = villes.id_ville)
Buffers: shared hit=2815 read=476
I/O Timings: read=22.862
Total runtime: 364466.458 ms
(17 lignes)
On constate que l’optimiseur part sur une boucle extrêmement coûteuse : 940 parcours sur colis, par id_ville. En moyenne, ces parcours durent environ 400 ms. Le résultat est vraiment très mauvais.
Il fait ce choix parce qu’il estime que la condition
localite ='PARIS' AND codepostal LIKE '75%'
va ramener 19 enregistrements. En réalité, elle en ramène 940, soit 50 fois plus, d’où un très mauvais choix. Pourquoi PostgreSQL fait-il cette erreur ?
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
marc=# EXPLAIN SELECT * FROM villes;
QUERY PLAN
-------------------------------------------------------------
Seq Scan on villes (cost=0.00..934.55 rows=54955 width=27)
(1 ligne)
marc=# EXPLAIN SELECT * FROM villes WHERE localite='PARIS';
QUERY PLAN
------------------------------------------------------------
Seq Scan on villes (cost=0.00..1071.94 rows=995 width=27)
Filter: (localite = 'PARIS'::text)
(2 lignes)
marc=# EXPLAIN SELECT * FROM villes WHERE codepostal LIKE '75%';
QUERY PLAN
-------------------------------------------------------------
Seq Scan on villes (cost=0.00..1071.94 rows=1042 width=27)
Filter: (codepostal ~~ '75%'::text)
(2 lignes)
marc=# EXPLAIN SELECT * FROM villes WHERE localite='PARIS'
marc=# AND codepostal LIKE '75%';
QUERY PLAN
------------------------------------------------------------------------
Seq Scan on villes (cost=0.00..1209.32 rows=19 width=27)
Filter: ((codepostal ~~ '75%'::text) AND (localite = 'PARIS'::text))
(2 lignes)
D’après les statistiques, villes contient 54 955 enregistrements, 995 contenant PARIS (presque 2 %), 1042 commençant par 75 (presque 2 %).
Il y a donc 2 % d’enregistrements vérifiant chaque critère (c’est normal, ils sont presque équivalents). PostgreSQL, n’ayant aucune autre information, part de l’hypothèse que les colonnes ne sont pas liées, et qu’il y a donc 2 % de 2 % (soit environ 0,04 %) des enregistrements qui vérifient les deux.
Si on fait le calcul exact, on a donc :
![]()
soit 18,8 enregistrements (arrondi à 19) qui vérifient le critère. Ce qui est évidemment faux.
- Exécutez cette requête sans la dernière clause AND codepostal LIKE '75%'. Que constatez-vous ?
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
explain (analyze,buffers) select * from colis where id_ville in (
select id_ville from villes where localite ='PARIS'
);
QUERY PLAN
--------------------------------------------------------------------------------
Hash Semi Join (cost=1083.86..183312.59 rows=173060 width=16)
(actual time=48.975..4362.348 rows=170802 loops=1)
Hash Cond: (colis.id_ville = villes.id_ville)
Buffers: shared hit=7 read=54435
I/O Timings: read=1219.212
-> Seq Scan on colis (cost=0.00..154053.55 rows=9999955 width=16)
(actual time=6.178..2228.259 rows=9999911 loops=1)
Buffers: shared hit=2 read=54052
I/O Timings: read=1199.307
-> Hash (cost=1071.94..1071.94 rows=954 width=
(actual time=42.676..42.676 rows=940 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 37kB
Buffers: shared hit=2 read=383
I/O Timings: read=19.905
-> Seq Scan on villes (cost=0.00..1071.94 rows=954 width=
(actual time=35.900..41.957 rows=940 loops=1)
Filter: (localite = 'PARIS'::text)
Rows Removed by Filter: 54015
Buffers: shared hit=2 read=383
I/O Timings: read=19.905
Total runtime: 4375.105 ms
(17 lignes)
Cette fois-ci, le plan est bon, et les estimations aussi.
- Quelle solution pourrait-on adopter, si on doit réellement spécifier ces deux conditions ?
On pourrait indexer sur une fonction des deux. C’est maladroit, mais malheureusement la seule solution sûre :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
CREATE FUNCTION test_ville (ville text,codepostal text) RETURNS text
IMMUTABLE LANGUAGE SQL as $$
SELECT ville || '-' || codepostal
$$ ;
CREATE INDEX idx_test_ville ON villes (test_ville(localite , codepostal));
ANALYZE villes;
EXPLAIN (analyze,buffers) SELECT * FROM colis WHERE id_ville IN (
SELECT id_ville
FROM villes
WHERE test_ville(localite,codepostal) LIKE 'PARIS-75%'
);
QUERY PLAN
--------------------------------------------------------------------------------
Hash Semi Join (cost=1360.59..183924.46 rows=203146 width=16)
(actual time=46.127..3530.348 rows=170802 loops=1)
Hash Cond: (colis.id_ville = villes.id_ville)
Buffers: shared hit=454 read=53989
-> Seq Scan on colis (cost=0.00..154054.11 rows=9999911 width=16)
(actual time=0.025..1297.520 rows=9999911 loops=1)
Buffers: shared hit=66 read=53989
-> Hash (cost=1346.71..1346.71 rows=1110 width=8)
(actual time=46.024..46.024 rows=940 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 37kB
Buffers: shared hit=385
-> Seq Scan on villes (cost=0.00..1346.71 rows=1110 width=8)
(actual time=37.257..45.610 rows=940 loops=1)
Filter: (((localite || '-'::text) || codepostal) ~~
'PARIS-75%'::text)
Rows Removed by Filter: 54015
Buffers: shared hit=385
Total runtime: 3543.838 ms
On constate qu’avec cette méthode il n’y a plus d’erreur d’estimation. Elle est bien sûr très pénible à utiliser, et ne doit donc être réservée qu’aux quelques rares requêtes ayant été identifiées comme ayant un comportement pathologique.
On peut aussi créer une colonne supplémentaire maintenue par un trigger, plutôt qu’un index : cela sera moins coûteux à maintenir, et permettra d’avoir la même statistique.
VI-M-2. Conclusion▲
Que peut-on conclure de cet exercice ?
- que la réécriture est souvent la meilleure des solutions : interrogez-vous toujours sur la façon dont vous écrivez vos requêtes, plutôt que de mettre en doute PostgreSQL a priori ;
-
que la réécriture de requête est souvent complexe - néanmoins, surveillez un certain nombre de choses :
- casts implicites suspects,
- jointures externes inutiles,
- sous-requêtes imbriquées,
- jointures inutiles (données constantes).
