


III. Création d’objet et mises à jour▲
III-A. Introduction▲
- DDL, gérer les objets.
- DML, écrire des données.
- Gérer les transactions.
Le module précédent nous a permis de voir comment lire des données à partir de requêtes SQL. Ce module a pour but de présenter la création et la gestion des objets dans la base de données (par exemple les tables), ainsi que l’ajout, la suppression et la modification de données.
Une dernière partie sera consacrée aux transactions.
III-A-1. Menu▲
- DDL (Data Definition Language).
- DML (Data Manipulation Language).
- TCL (Transaction Control Language).
III-A-2. Objectifs▲
- Savoir créer, modifier et supprimer des objets.
- Savoir utiliser les contraintes d’intégrité.
- Savoir mettre à jour les données.
- Savoir utiliser les transactions.
III-B. DDL▲
-
DDL :
- Data Definition Language,
- langage de définition de données.
- Permet de créer des objets dans la base de données.
Les ordres DDL (acronyme de Data Definition Language) permettent de créer des objets dans la base de données et notamment la structure de base du standard SQL : les tables.
III-B-1. Objets d’une base de données▲
-
Objets définis par la norme SQL :
- schémas,
- séquences,
- tables,
- contraintes,
- domaines,
- vues,
- fonctions,
- triggers.
La norme SQL définit un certain nombre d’objets standards qu’il est possible de créer en utilisant les ordres DDL. D’autres types d’objets existent bien entendu, comme les domaines. Les ordres DDL permettent également de créer des index, bien qu’ils ne soient pas définis dans la norme SQL.
La seule structure de données possible dans une base de données relationnelle est la table.
III-B-2. Créer des objets▲
- Ordre CREATE.
- Syntaxe spécifique au type d’objet.
- Exemple :
CREATESCHEMAs1;. - La création d’objets passe généralement par l’ordre CREATE. La syntaxe dépend fortement du type d’objet. Voici trois exemples :
2.
3.
CREATE SCHEMA s1;
CREATE TABLE t1 (c1 integer, c2 text);
CREATE SEQUENCE s1 INCREMENT BY 5 START 10;
Pour créer un objet, il faut être propriétaire du schéma ou de la base auquel appartiendra l’objet ou avoir le droit CREATE sur le schéma ou la base.
III-B-3. Modifier des objets▲
- Ordre ALTER.
-
Syntaxe spécifique pour modifier la définition d’un objet, exemple:
- renommage :
ALTERtype_objet ancien_nomRENAMETOnouveau_nom ; - changement de propriétaire :
ALTERtype_objet nom_objetOWNERTOproprietaire ;- changement de schéma :
ALTERtype_objet nom_objetSETSCHEMAnom_schema ;
- renommage :
Modifier un objet veut dire modifier ses propriétés. On utilise dans ce cas l’ordre ALTER. Il faut être propriétaire de l’objet pour pouvoir le faire.
Deux propriétés sont communes à tous les objets : le nom de l’objet et son propriétaire. Deux autres sont fréquentes et dépendent du type de l’objet : le schéma et le tablespace. Les autres propriétés dépendent directement du type de l’objet.
III-B-4. Supprimer des objets▲
- Ordre DROP.
-
Exemples :
- supprimer un objet :
DROPtype_objet nom_objet ; - supprimer un objet et ses dépendances :
DROPtype_objet nom_objetCASCADE;
- supprimer un objet :
Seul un propriétaire peut supprimer un objet. Il utilise pour cela l’ordre DROP. Pour les objets ayant des dépendances, l’option CASCADE permet de tout supprimer d’un coup. C’est très pratique, et c’est en même temps très dangereux : il faut donc utiliser cette option à bon escient.
III-B-5. Schéma▲
- Identique à un espace de nommage.
- Permet d’organiser les tables de façon logique.
- Possibilité d’avoir des objets de même nom dans des schémas différents.
- Pas d’imbrication (contrairement à des répertoires par exemple).
-
Schéma public :
- créé par défaut dans une base de données PostgreSQL.
La notion de schéma dans PostgreSQL est à rapprocher de la notion d’espace de nommage (ou namespace) de certains langages de programmation. Le catalogue système qui contient la définition des schémas dans PostgreSQL s’appelle d’ailleurs pg_namespace.
Les schémas sont utilisés pour répartir les objets de façon logique, suivant un schéma interne à l’entreprise. Ils servent aussi à faciliter la gestion des droits (il suffit de révoquer le droit d’utilisation d’un schéma à un utilisateur pour que les objets contenus dans ce schéma ne soient plus accessibles à cet utilisateur).
Un schéma public est créé par défaut dans toute nouvelle base de données. Tout le monde a le droit d’y créer des objets. Il est cependant possible de révoquer ce droit ou supprimer ce schéma.
III-B-6. Gestion d’un schéma▲
CREATESCHEMAnom_schéma.ALTERSCHEMAnom_schéma.- Renommage
- L’ordre
CREATESCHEMApermet de créer un schéma. Il suffit de lui spécifier le nom du schéma.CREATESCHEMAoffre d’autres possibilités qui sont rarement utilisées.
L’ordre ALTER SCHEMA nom_schema RENAME TO nouveau_nom_schema permet de renommer un schéma. L’ordre ALTER SCHEMA nom_schema OWNER TO proprietaire permet de donner un nouveau propriétaire au schéma.
Enfin, l’ordre DROP SCHEMA permet de supprimer un schéma. La clause IF EXISTS permet d’éviter la levée d’une erreur si le schéma n’existe pas (très utile dans les scripts SQL). La clause CASCADE permet de supprimer le schéma, ainsi que tous les objets qui sont positionnés dans le schéma.
Exemples
Création d’un schéma reference :
CREATE SCHEMA reference;
Une table peut être créée dans ce schéma :
2.
3.
4.
5.
6.
CREATE TABLE reference.communes (
commune text,
codepostal char(5),
departement text,
codeinsee integer
);
La suppression directe du schéma ne fonctionne pas, car il porte encore la table communes :
2.
3.
4.
DROP SCHEMA reference;
ERROR: cannot drop schema reference because other objects depend on it
DETAIL: table reference.communes depends on schema reference
HINT: Use DROP ... CASCADE to drop the dependent objects too.
L’option CASCADE permet de supprimer le schéma et ses objets dépendants :
DROP SCHEMA reference CASCADE;
NOTICE: drop cascades to table reference.communesIII-B-7. Accès aux objets▲
-
Nommage explicite
- nom_schema.nom_objet
-
Chemin de recherche de schéma :
- paramètre search_path,
SETsearch_path=schema1,schema2,public;,- par défaut : $user, public,
Le paramètre search_path permet de définir un chemin de recherche pour pouvoir retrouver les tables dont le nom n’est pas qualifié par le nom de son schéma. PostgreSQL procédera de la même façon que le système avec la variable $PATH : il recherche la table dans le premier schéma listé. S’il trouve une table portant ce nom dans le schéma, il préfixe le nom de table avec celui du schéma. S’il ne trouve pas de table de ce nom dans le schéma, il effectue la même opération sur le prochain schéma de la liste du search_path. S’il n’a trouvé aucune table de ce nom dans les schémas listés par search_path, PostgreSQL lève une erreur.
Comme beaucoup d’autres paramètres, le search_path peut être positionné à différents endroits. Par défaut, il est assigné à $user, public, c’est-à-dire que le premier schéma de recherche portera le nom de l’utilisateur courant, et le second schéma de recherche est public.
On peut vérifier la variable search_path à l’aide de la commande SHOW :
2.
3.
4.
5.
SHOW search_path;
search_path
----------------
"$user",public
(1 row)
Pour obtenir une configuration particulière, la variable search_path peut être positionnée dans le fichier postgresql.conf :
search_path = '"$user",public'
Cette variable peut aussi être positionnée au niveau d’un utilisateur. Chaque fois que l’utilisateur se connectera, il prendra le search_path de sa configuration spécifique :
ALTER ROLE nom_role SET search_path = "$user", public;
Cela peut aussi se faire au niveau d’une base de données. Chaque fois qu’un utilisateur se connectera à la base, il prendra le search_path de cette base, sauf si l’utilisateur a déjà une configuration spécifique :
ALTER DATABASE nom_base SET search_path = "$user", public;
La variable search_path peut également être positionnée pour un utilisateur particulier, dans une base particulière :
ALTER ROLE nom_role IN DATABASE nom_base SET search_path = "$user", public;
Enfin, la variable search_path peut être modifiée dynamiquement dans la session avec la commande SET :
SET search_path = "$user", public;
Avant la version 9.3, les requêtes préparées et les fonctions conservaient en mémoire le plan d’exécution des requêtes. Ce plan ne faisait plus référence aux noms des objets, mais à leurs identifiants. Du coup, un search_path changeant entre deux exécutions d’une requête préparée ou d’une fonction ne permettait pas de cibler une table différente. Voici un exemple le montrant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
-- création des objets
CREATE SCHEMA s1;
CREATE SCHEMA s2;
CREATE TABLE s1.t1 (c1 text);
CREATE TABLE s2.t1 (c1 text);
INSERT INTO s1.t1 VALUES('schéma s1');
INSERT INTO s2.t1 VALUES('schéma s2');
SELECT * FROM s1.t1;
c1
-----------
schéma s1
(1 row)
SELECT * FROM s2.t1;
c1
-----------
schéma s2
(1 row)
-- il y a bien des données différentes dans chaque table
SET search_path TO s1;
PREPARE req AS SELECT * FROM t1;
EXECUTE req;
c1
-----------
schéma s1
(1 row)
SET search_path TO s2;
EXECUTE req;
c1
-----------
schéma s1
(1 row)
-- malgré le changement de search_path, nous en sommes toujours
-- aux données de l'autre table
b1=# SELECT * FROM t1;
c1
-----------
schéma s2
(1 row)
Dans ce cas, il est préférable de configurer le paramètre search_path directement au niveau de la fonction.
À partir de la version 9.3, dès que le search_path change, les plans en cache sont supprimés (dans le cas de la fonction) ou recréés (dans le cas des requêtes préparées).
III-B-8. Séquences▲
-
Séquence :
- génère une séquence de nombres.
-
Paramètres :
- valeur minimale MINVALUE,
- valeur maximale MAXVALUE,
- valeur de départ START,
- incrément INCREMENT,
- cache CACHE,
- cycle autorisé CYCLE.
Les séquences sont des objets standards qui permettent de générer des séquences de valeurs. Elles sont utilisées notamment pour générer un numéro unique pour un identifiant ou, plus rarement, pour disposer d’un compteur informatif, mis à jour au besoin.
Le cache de la séquence a pour effet de générer un certain nombre de valeurs en mémoire afin de les mettre à disposition de la session qui a utilisé la séquence. Même si les valeurs précalculées ne sont pas consommées dans la session, elles seront consommées au niveau de la séquence. Cela peut avoir pour effet de créer des trous dans les séquences d’identifiants et de consommer très rapidement les numéros de séquence possibles. Le cache de séquence n’a pas besoin d’être ajusté sur des applications réalisant de petites transactions. Il permet en revanche d’améliorer les performances sur des applications qui utilisent massivement des numéros de séquences, notamment pour réaliser des insertions massives.
III-B-9. Création d’une séquence▲
2.
3.
4.
5.
6.
7.
CREATE SEQUENCE nom [ INCREMENT incrément ]
[ MINVALUE valeurmin | NO MINVALUE ]
[ MAXVALUE valeurmax | NO MAXVALUE ]
[ START [ WITH ] début ]
[ CACHE cache ]
[ [ NO ] CYCLE ]
[ OWNED BY { nom_table.nom_colonne | NONE } ]
La syntaxe complète est donnée ci-dessus.
Le mot-clé TEMPORARY ou TEMP permet de définir si la séquence est temporaire. Si tel est le cas, elle sera détruite à la déconnexion de l’utilisateur.
Le mot-clé INCREMENT définit l’incrément de la séquence, MINVALUE, la valeur minimale de la séquence et MAXVALUE, la valeur maximale. START détermine la valeur de départ initiale de la séquence, c’est-à-dire juste après sa création. La clause CACHE détermine le cache de séquence. CYCLE permet d’indiquer au SGBD que la séquence peut reprendre son compte à MINVALUE lorsqu’elle aura atteint MAXVALUE. La clause NO CYCLE indique que le rebouclage de la séquence est interdit, PostgreSQL lèvera alors une erreur lorsque la séquence aura atteint son MAXVALUE. Enfin, la clause OWNED BY détermine l’appartenance d’une séquence à une colonne d’une table. Ainsi, si la colonne est supprimée, la séquence sera implicitement supprimée.
Exemple de séquence avec rebouclage :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
CREATE SEQUENCE testseq INCREMENT BY 1 MINVALUE 3 MAXVALUE 5 CYCLE START WITH 4;
SELECT nextval('testseq');
nextval
---------
4
SELECT nextval('testseq');
nextval
---------
5
SELECT nextval('testseq');
nextval
---------
3
III-B-10. Modification d’une séquence▲
2.
3.
4.
5.
6.
7.
ALTER SEQUENCE nom [ INCREMENT increment ]
[ MINVALUE valeurmin | NO MINVALUE ]
[ MAXVALUE valeurmax | NO MAXVALUE ]
[ START [ WITH ] début ]
[ RESTART [ [ WITH ] nouveau_début ] ]
[ CACHE cache ] [ [ NO ] CYCLE ]
[ OWNED BY { nom_table.nom_colonne | NONE } ]
-
Il est aussi possible de modifier :
- le propriétaire,
- le schéma.
Les propriétés de la séquence peuvent être modifiées avec l’ordre ALTER SEQUENCE.
La séquence peut être affectée à un nouveau propriétaire :
ALTER SEQUENCE [ IF EXISTS ] nom OWNER TO nouveau_propriétaire
Elle peut être renommée :
ALTER SEQUENCE [ IF EXISTS ] nom RENAME TO nouveau_nom
Enfin, elle peut être positionnée dans un nouveau schéma :
ALTER SEQUENCE [ IF EXISTS ] nom SET SCHEMA nouveau_schema
III-B-11. Suppression d’une séquence▲
DROP SEQUENCE nom [, …]Voici la syntaxe complète de DROP SEQUENCE :
DROP SEQUENCE [ IF EXISTS ] nom [, ...] [ CASCADE | RESTRICT ]
Le mot-clé CASCADE permet de supprimer la séquence ainsi que tous les objets dépendants (par exemple la valeur par défaut d’une colonne).
III-B-12. Séquences, utilisation▲
-
Obtenir la valeur suivante :
- nextval('nom_sequence')
-
Obtenir la valeur courante :
- currval('nom_sequence'),
- mais nextval() doit être appelée avant dans la même session.
La fonction nextval() permet d’obtenir le numéro de séquence suivant. Son comportement n’est pas transactionnel. Une fois qu’un numéro est consommé, il n’est pas possible de revenir dessus, malgré un ROLLBACK de la transaction. La séquence est le seul objet à avoir un comportement de ce type.
La fonction currval() permet d’obtenir le numéro de séquence courant, mais son usage nécessite d’avoir utilisé nextval() dans la session.
Il est possible d’interroger une séquence avec une requête SELECT. Cela permet d’obtenir des informations sur la séquence, dont la dernière valeur utilisée dans la colonne last_value. Cet usage n’est pas recommandé en production et doit plutôt être utilisé à titre informatif.
Exemples
Utilisation d’une séquence simple :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
CREATE SEQUENCE testseq
INCREMENT BY 1 MINVALUE 10 MAXVALUE 20 START WITH 15 CACHE 1;
SELECT currval('testseq');
ERROR: currval of sequence "testseq" is not yet defined in this session
SELECT * FROM testseq ;
- [ RECORD 1 ]-+--------
sequence_name | testseq
last_value | 15
start_value | 15
increment_by | 1
max_value | 20
min_value | 10
cache_value | 5
log_cnt | 0
is_cycled | f
is_called | f
SELECT nextval('testseq');
nextval
---------
15
(1 row)
SELECT currval('testseq');
currval
---------
15
SELECT nextval('testseq');
nextval
---------
16
(1 row)
ALTER SEQUENCE testseq RESTART WITH 5;
ERROR: RESTART value (5) cannot be less than MINVALUE (10)
DROP SEQUENCE testseq;
Utilisation d’une séquence simple avec cache :
CREATE SEQUENCE testseq INCREMENT BY 1 CACHE 10;
SELECT nextval('testseq');
nextval
---------
1Déconnexion et reconnexion de l’utilisateur :
SELECT nextval('testseq');
nextval
---------
11Suppression en cascade d’une séquence :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
CREATE TABLE t2 (id serial);
\d t2
Table "s2.t2"
Column | Type | Modifiers
--------+---------+-------------------------------------------------
id | integer | not null default nextval('t2_id_seq'::regclass)
DROP SEQUENCE t2_id_seq;
ERROR: cannot drop sequence t2_id_seq because other objects depend on it
DETAIL: default for table t2 column id depends on sequence t2_id_seq
HINT: Use DROP ... CASCADE to drop the dependent objects too.
DROP SEQUENCE t2_id_seq CASCADE;
NOTICE: drop cascades to default for table t2 column id
\d t2
Table "s2.t2"
Column | Type | Modifiers
--------+---------+-----------
id | integer | not null
III-B-13. Type SERIAL▲
-
Type serial/bigserial/smallserial :
- séquence générée automatiquement,
- valeur par défaut nextval(...).
- (v 10+) Préférer un entier avec IDENTITY.
Certaines bases de données offrent des colonnes auto-incrémentées (autoincrement de MySQL ou identity de SQL Server).
PostgreSQL ne possède identity qu’à partir de la v 10. Jusqu’en 9.6, on pourra utiliser serial, un équivalent qui s’appuie sur les séquences et la possibilité d’appliquer une valeur par défaut à une colonne.
Par exemple, si l’on crée la table suivante :
CREATE TABLE exemple_serial (
id SERIAL PRIMARY KEY,
valeur INTEGER NOT NULL
);On s’aperçoit que table a été créée telle que demandé, mais qu’une séquence a aussi été créée. Elle porte un nom dérivé de la table associée à la colonne correspondant au type serial, terminé par seq :
postgres=# \d
List of relations
Schema | Name | Type | Owner
--------+-----------------------+----------+--------
public | exemple_serial | table | thomas
public | exemple_serial_id_seq | sequence | thomasEn examinant plus précisément la définition de la table, on s’aperçoit que la colonne id porte une valeur par défaut qui correspond à l’appel de la fonction nextval() sur la séquence qui a été créée implicitement :
postgres=# \d exemple_serial
Table "public.exemple_serial"
Column | Type | Modifiers
--------+---------+-------------------------------------------------------------
id | integer | not null default nextval('exemple_serial_id_seq'::regclass)
valeur | integer | not null
Indexes:
"exemple_serial_pkey" PRIMARY KEY, btree (id)smallserial et bigserial sont des variantes de serial s’appuyant sur des types d’entiers plus courts ou plus longs.
III-B-14. Domaines▲
-
Permet d’associer :
- un type standard,
- et une contrainte (optionnelle).
Un domaine est utilisé pour définir un type utilisateur qui est en fait un type utilisateur standard accompagné de la définition de contraintes particulières.
Les domaines sont utiles pour ramener la définition de contraintes communes à plusieurs colonnes sur un seul objet. La maintenance en est ainsi facilitée.
L’ordre CREATE DOMAIN permet de créer un domaine, ALTER DOMAIN permet de modifier sa définition, et enfin, DROP DOMAIN permet de supprimer un domaine.
Exemples :
Gestion d’un domaine salaire :
-- ajoutons le domaine et la table
CREATE DOMAIN salaire AS integer CHECK (VALUE > 0);
CREATE TABLE employes (id serial, nom text, paye salaire);
\d employes
Table « public.employes »
Colonne | Type | NULL-able | Par défaut
---------+---------+------------+--------------------------------------
id | integer | not null | nextval('employes_id_seq'::regclass)
nom | text | |
paye | salaire | |
-- insérons des données dans la nouvelle table
INSERT INTO employes (nom, paye) VALUES ('Albert', 1500);
INSERT INTO employes (nom, paye) VALUES ('Alphonse', 0);
ERROR: value for domain salaire violates check constraint "salaire_check"
-- erreur logique vu qu'on ne peut avoir qu'un entier strictement positif
INSERT INTO employes (nom, paye) VALUES ('Alphonse', 1000);
INSERT 0 1
INSERT INTO employes (nom, paye) VALUES ('Bertrand', NULL);
INSERT 0 1
-- tous les employés doivent avoir un salaire
-- il faut donc modifier la contrainte, pour s'assurer
-- qu'aucune valeur NULL ne soit saisi
ALTER DOMAIN salaire SET NOT NULL;
ERROR: column "paye" of table "employes" contains null values
-- la ligne est déjà présente, il faut la modifier
UPDATE employes SET paye=1500 WHERE nom='Bertrand';
-- maintenant, on peut ajouter la contrainte au domaine
ALTER DOMAIN salaire SET NOT NULL;
INSERT INTO employes (nom, paye) VALUES ('Delphine', NULL);
ERROR: domain salaire does not allow null values
-- la contrainte est bien vérifiée
-- supprimons maintenant la contrainte
DROP DOMAIN salaire;
ERROR: cannot drop type salaire because other objects depend on it
DETAIL: table employes column paye depends on type salaire
HINT: Use DROP ... CASCADE to drop the dependent objects too.
-- il n'est pas possible de supprimer le domaine, car il est référencé dans une
-- table. Il faut donc utiliser l'option CASCADE
b1=# DROP DOMAIN salaire CASCADE;
NOTICE: drop cascades to table employes column paye
DROP DOMAIN
-- le domaine a été supprimé, ainsi que toutes les colonnes ayant ce type
\d employes
Table « public.employes »
Colonne | Type | NULL-able | Par défaut
---------+---------+-----------+--------------------------------------
id | integer | not null | nextval('employes_id_seq'::regclass)
nom | text | |Création et utilisation d’un domaine code_postal_us :
CREATE DOMAIN code_postal_us AS TEXT
CHECK(
VALUE ~ '^\d{5}$'
OR VALUE ~ '^\d{5}-\d{4}$'
);
CREATE TABLE courrier_us (
id_adresse SERIAL PRIMARY KEY,
rue1 TEXT NOT NULL,
rue2 TEXT,
rue3 TEXT,
ville TEXT NOT NULL,
code_postal code_postal_us NOT NULL
);
INSERT INTO courrier_us (rue1,ville,code_postal)
VALUES ('51 Franklin Street', 'Boston, MA', '02110-1335' );
INSERT 0 1
INSERT INTO courrier_us (rue1,ville,code_postal)
VALUES ('10 rue d''Uzès','Paris','F-75002') ;
ERREUR: la valeur pour le domaine code_postal_us viole la contrainte de
vérification « code_postal_us_check »III-B-15. Tables▲
- Équivalent ensembliste d’une relation.
-
Composé principalement de :
- colonnes ordonnées,
- contraintes.
La table est l’élément de base d’une base de données. Elle est composée de colonnes (à sa création) et est remplie avec des enregistrements (lignes de la table). Sa définition peut aussi faire intervenir des contraintes, qui sont au niveau table ou colonne.
III-B-16. Création d’une table▲
- Définition de son nom.
-
Définition de ses colonnes :
- nom, type, contraintes éventuelles.
- Clauses de stockage.
- CREATE TABLE.
Pour créer une table, il faut donner son nom et la liste des colonnes. Une colonne est définie par son nom et son type, mais aussi des contraintes optionnelles.
Des options sont possibles pour les tables, comme les clauses de stockage. Dans ce cas, on sort du contexte logique pour se placer au niveau physique.
III-B-17. CREATE TABLE▲
CREATE TABLE nom_table (
definition_colonnes
definition_contraintes
) clause_stockage;La création d’une table passe par l’ordre CREATE TABLE. La définition des colonnes et des contraintes est entre parenthèses après le nom de la table.
III-B-18. Définition des colonnes▲
nom_colonne type [ COLLATE collation ] [ contrainte ]
[, …]Les colonnes sont indiquées l’une après l’autre, en les séparant par des virgules.
Deux informations sont obligatoires pour chaque colonne : le nom et le type de la colonne. Dans le cas d’une colonne contenant du texte, il est possible de fournir le collationnement de la colonne. Quelle que soit la colonne, il est ensuite possible d’ajouter des contraintes.
III-B-19. Valeur par défaut▲
-
DEFAULT :
- affectation implicite.
- Utiliser directement par les types sériés.
La clause DEFAULT permet d’affecter une valeur par défaut lorsqu’une colonne n’est pas référencée dans l’ordre d’insertion ou si une mise à jour réinitialise la valeur de la colonne à sa valeur par défaut.
Les types sériés définissent une valeur par défaut sur les colonnes de ce type. Cette valeur est le retour de la fonction nextval() sur la séquence affectée automatiquement à cette colonne.
Exemples :
Assignation d’une valeur par défaut :
CREATE TABLE valdefaut (
id integer,
i integer DEFAULT 0,
j integer DEFAULT 0
);
INSERT INTO valdefaut (id, i) VALUES (1, 10);
SELECT * FROM valdefaut ;
id | i | j
----+----+---
1 | 10 | 0
(1 row)III-B-20. Copie de la définition d’une table▲
- Création d’une table à partir d’une autre table :
CREATE TABLE ... (LIKE table clause_inclusion)
- Avec les valeurs par défaut des colonnes :
INCLUDING DEFAULTS
- Avec ses autres contraintes :
INCLUDING CONSTRAINTS
- Avec ses index :
INCLUDING INDEXES
L’ordre CREATE TABLE permet également de créer une table à partir de la définition d’une table déjà existante en utilisant la clause LIKE en lieu et place de la définition habituelle des colonnes. Par défaut, seule la définition des colonnes avec leur typage est reprise.
Les clauses INCLUDING permettent de récupérer d’autres éléments de la définition de la table, comme les valeurs par défaut (INCLUDING DEFAULTS), les contraintes d’intégrité (INCLUDING CONSTRAINTS), les index (INCLUDING INDEXES), les clauses de stockage (INCLUDING STORAGE) ainsi que les commentaires (INCLUDING COMMENTS). Si l’ensemble de ces éléments est repris, il est possible de résumer la clause INCLUDING à INCLUDING ALL.
La clause CREATE TABLE suivante permet de créer une table archive_evenements_2010 à partir de la définition de la table evenements :
2.
3.
4.
5.
6.
7.
8.
CREATE TABLE archive_evenements_2010
(LIKE evenements
INCLUDING DEFAULTS
INCLUDING CONSTRAINTS
INCLUDING INDEXES
INCLUDING STORAGE
INCLUDING COMMENTS
);
Elle est équivalente à :
CREATE TABLE archive_evenements_2010
(LIKE evenements
INCLUDING ALL
);III-B-21. Modification d’une table▲
- ALTER TABLE.
-
Définition de la table :
- renommage de la table,
- ajout/modification/suppression d’une colonne,
- déplacement dans un schéma différent,
- changement du propriétaire.
-
Définition des colonnes :
- renommage d’une colonne,
- changement de type d’une colonne,
-
Définition des contraintes :
- ajout/suppression d’une contrainte.
Pour modifier la définition d’une table (et non pas son contenu), il convient d’utiliser l’ordre ALTER TABLE. Il permet de traiter la définition de la table (nom, propriétaire, schéma, liste des colonnes), la définition des colonnes (ajout, modification de nom et de type, suppression… mais pas de changement au niveau de leur ordre), et la définition des contraintes (ajout et suppression).
III-B-22. Suppression d’une table▲
- Supprimer une table :
DROPTABLEnom_table; - Supprimer une table et tous les objets dépendants :
DROPTABLEnom_tableCASCADE;
L’ordre DROP TABLE permet de supprimer une table. L’ordre DROP TABLE ... CASCADE permet de supprimer une table ainsi que tous ses objets dépendants. Il peut s’agir de séquences rattachées à une colonne d’une table, à des colonnes référençant la table à supprimer, etc.
III-B-23. Contraintes d’intégrité▲
-
ACID :
- Cohérence,
- une transaction amène la base d’un état stable à un autre.
-
Assurent la cohérence des données :
- unicité des enregistrements,
- intégrité référentielle,
- vérification des valeurs,
- identité des enregistrements,
- règles sémantiques.
Les données dans les différentes tables ne sont pas indépendantes, mais obéissent à des règles sémantiques mises en place au moment de la conception du modèle conceptuel des données. Les contraintes d’intégrité ont pour principal objectif de garantir la cohérence des données entre elles, et donc de veiller à ce qu’elles respectent ces règles sémantiques. Si une insertion, une mise à jour ou une suppression viole ces règles, l’opération est purement et simplement annulée.
III-B-24. Clés primaires▲
- Identifie une ligne de manière unique.
- Une seule clé primaire par table.
- Une ou plusieurs colonnes.
-
À choisir parmi les clés candidates :
- parfois, utiliser une clé artificielle.
Une clé primaire permet d’identifier une ligne de façon unique, il n’en existe qu’une seule par table.
Une clé primaire garantit que toutes les valeurs de la ou des colonnes qui composent cette clé sont uniques et non nulles. Elle peut être composée d’une seule colonne ou de plusieurs colonnes, selon le besoin.
La clé primaire est déterminée au moment de la conception du modèle de données.
Les clés primaires créent implicitement un index qui permet de renforcer cette contrainte.
III-B-25. Déclaration d’une clé primaire▲
Construction :
[CONSTRAINT nom_contrainte]
PRIMARY KEY ( nom_colonne [, ... ] )Exemples :
Définition de la table region :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
CREATE TABLE region
(
id serial UNIQUE NOT NULL,
libelle text NOT NULL,
PRIMARY KEY(id)
);
INSERT INTO region VALUES (1, 'un');
INSERT INTO region VALUES (2, 'deux');
INSERT INTO region VALUES (NULL, 'trois');
ERROR: null value in column "id" violates not-null constraint
DETAIL: Failing row contains (null, trois).
INSERT INTO region VALUES (1, 'trois');
ERROR: duplicate key value violates unique constraint "region_pkey"
DETAIL: Key (id)=(1) already exists.
INSERT INTO region VALUES (3, 'trois');
SELECT * FROM region;
id | libelle
----+---------
1 | un
2 | deux
3 | trois
(3 rows)
III-B-26. Contrainte d’unicité▲
- Garantit l’unicité des valeurs d’une ou plusieurs colonnes.
- Permet les valeurs NULL.
- Clause UNIQUE.
- Contrainte UNIQUE != index UNIQUE.
Une contrainte d’unicité permet de garantir que les valeurs de la ou des colonnes sur lesquelles porte la contrainte sont uniques. Elle autorise néanmoins d’avoir plusieurs valeurs NULL, car elles ne sont pas considérées comme égales, mais de valeur inconnue (UNKNOWN).
Une contrainte d’unicité peut être créée simplement en créant un index UNIQUE approprié. Ceci est fortement déconseillé du fait que la contrainte ne sera pas référencée comme telle dans le schéma de la base de données. Il sera donc très facile de ne pas la remarquer au moment d’une reprise du schéma pour une évolution majeure de l’application. Une colonne possédant un index UNIQUE peut malgré tout être référencée par une clé étrangère.
Les contraintes d’unicité créent implicitement un index qui permet de renforcer cette unicité.
III-B-26-a. Déclaration d’une contrainte d’unicité▲
Construction :
[ CONSTRAINT nom_contrainte]
{ UNIQUE ( nom_colonne [, ... ] )III-B-27. Intégrité référentielle▲
-
Contrainte d’intégrité référentielle :
- ou clé étrangère.
- Référence une clé primaire ou un groupe de colonnes UNIQUE et NOT NULL.
- Garantit l’intégrité des données.
- FOREIGN KEY.
Une clé étrangère sur une table fait référence à une clé primaire ou une contrainte d’unicité d’une autre table. La clé étrangère garantit que les valeurs des colonnes de cette clé existent également dans la table portant la clé primaire ou la contrainte d’unicité. On parle de contrainte référentielle d’intégrité : la contrainte interdit les valeurs qui n’existent pas dans la table référencée.
Ainsi, la base cave définit une table region et une table appellation. Une appellation d’origine est liée au terroir et, par extension, à son origine géographique. La table appellation est donc liée par une clé étrangère à la table region : la colonne region_id de la table appellation référence la colonne id de la table region.
Cette contrainte permet d’empêcher les utilisateurs d’entrer dans la table appellation des identifiants de région (region_id) qui n’existent pas dans la table region.
Exemple
|
|
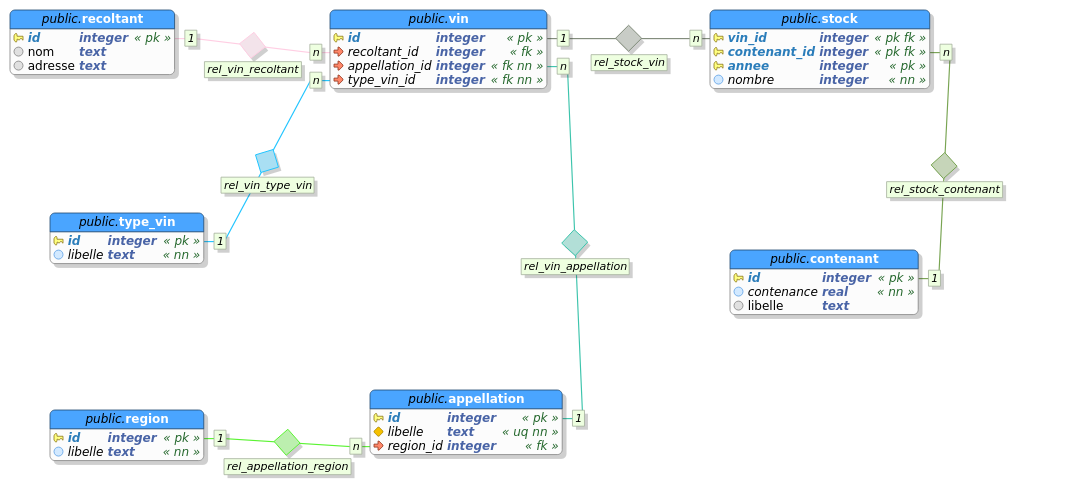
III-B-28. Déclaration d’une clé étrangère▲
2.
3.
4.
[ CONSTRAINT nom_contrainte ] FOREIGN KEY ( nom_colonne [, ...] )
REFERENCES table_reference [ (colonne_reference [, ... ] ) ]
[ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ]
[ ON DELETE action ] [ ON UPDATE action ] }
Exemples :
Définition de la table stock :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
CREATE TABLE stock
(
vin_id int not null,
contenant_id int not null,
annee int4 not null,
nombre int4 not null,
PRIMARY KEY(vin_id,contenant_id,annee),
FOREIGN KEY(vin_id) REFERENCES vin(id) ON DELETE CASCADE,
FOREIGN KEY(contenant_id) REFERENCES contenant(id) ON DELETE CASCADE
);
Création d’une table mère et d’une table fille. La table fille possède une clé étrangère qui référence la table mère :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
CREATE TABLE mere (id integer, t text);
CREATE TABLE fille (id integer, mere_id integer, t text);
ALTER TABLE mere ADD CONSTRAINT pk_mere PRIMARY KEY (id);
ALTER TABLE fille
ADD CONSTRAINT fk_mere_fille
FOREIGN KEY (mere_id)
REFERENCES mere (id)
MATCH FULL
ON UPDATE NO ACTION
ON DELETE CASCADE;
INSERT INTO mere (id, t) VALUES (1, 'val1'), (2, 'val2');
-- l'ajout de données dans la table fille qui font bien référence
-- à la table mere fonctionne
INSERT INTO fille (id, mere_id, t) VALUES (1, 1, 'val1');
INSERT INTO fille (id, mere_id, t) VALUES (2, 2, 'val2');
-- l'ajout de données dans la table fille qui ne font pas référence
-- à la table mere est annulé
INSERT INTO fille (id, mere_id, t) VALUES (3, 3, 'val3');
ERROR: insert or update on table "fille" violates foreign key constraint
"fk_mere_fille"
DETAIL: Key (mere_id)=(3) is not present in table "mere".
b1=# SELECT * FROM fille;
id | mere_id | t
----+---------+------
1 | 1 | val1
2 | 2 | val2
(2 rows)
-- mettre à jour la référence dans la table mere ne fonctionnera pas,
-- car la contrainte a été définie pour refuser les mises à jour
-- (ON UPDATE NO ACTION)
b1=# UPDATE mere SET id=3 WHERE id=2;
ERROR: update or delete on table "mere" violates foreign key constraint
"fk_mere_fille" on table "fille"
DETAIL: Key (id)=(2) is still referenced from table "fille".
-- par contre, la suppression d'une ligne de la table mere référencée dans la
-- table fille va propager la suppression jusqu'à la table fille
-- (ON DELETE CASCADE)
b1=# DELETE FROM mere WHERE id=2;
DELETE 1
b1=# SELECT * FROM fille;
id | mere_id | t
----+---------+------
1 | 1 | val1
(1 row)
b1=# SELECT * FROM mere;
id | t
----+------
1 | val1
(1 row)
III-B-28-a. Vérification simple ou complète▲
- Vérification complète ou partielle d’une clé étrangère.
-
MATCH.
- MATCH FULL (complète),
- MATCH SIMPLE (partielle).
La directive MATCH permet d’indiquer si la contrainte doit être entièrement vérifiée (MATCH FULL) ou si la clé étrangère autorise des valeurs NULL (MATCH SIMPLE). MATCH SIMPLE est la valeur par défaut.
Avec MATCH FULL, toutes les valeurs des colonnes qui composent la clé étrangère de la table référençant doivent avoir une correspondance dans la table référencée.
Avec MATCH SIMPLE, les valeurs des colonnes qui composent la clé étrangère de la table référençant peuvent comporter des valeurs NULL. Dans le cas des clés étrangères multicolonnes, toutes les colonnes peuvent ne pas être renseignées. Dans le cas des clés étrangères sur une seule colonne, la contrainte autorise les valeurs NULL.
Exemples :
Les exemples reprennent les tables mere et fille créées plus haut.
INSERT INTO fille VALUES (4, NULL, 'test');
SELECT * FROM fille;
id | mere_id | t
----+---------+------
1 | 1 | val1
2 | 2 | val2
4 | | test
(2 rows)III-B-29. Colonnes d’identité▲
- Identité d’un enregistrement.
-
GENERATED ... AS IDENTITY :
- ALWAYS,
- BY DEFAULT.
- Préférer à serial.
- Unicité non garantie sans contrainte explicite !
Cette contrainte permet d’avoir une colonne dont la valeur est incrémentée automatiquement, soit en permanence (clause ALWAYS), soit quand aucune valeur n’est saisie (clause BY DEFAULT). Cette solution au besoin d’auto-incrémentation des valeurs des colonnes satisfait le standard SQL, contrairement au pseudo-type serial qui était utilisé jusqu’à la version 10.
De plus, elle corrige certains défauts de ce pseudo-type. Avec le type serial, l’utilisation de CREATE TABLE .. LIKE copiait la contrainte de valeur par défaut sans changer le nom de la séquence. Il n’est pas possible d’ajouter ou de supprimer un pseudo-type serial avec l’instruction ALTER TABLE. La suppression de la contrainte DEFAULT d’un type serial ne supprime pas la séquence associée. Tout ceci fait que la définition d’une colonne d’identité est préférable à l’utilisation du pseudo-type serial.
Il reste obligatoire de définir une clé primaire ou unique si l’on tient à l’unicité des valeurs, car même une clause GENERATED ALWAYS AS IDENTITY peut être contournée avec une mise à jour portant la mention OVERRIDING SYSTEM VALUE.
Exemple :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
CREATE table personnes (id int GENERATED ALWAYS AS IDENTITY, nom TEXT);
CREATE TABLE
INSERT INTO personnes (nom) VALUES ('Dupont') ;
INSERT 0 1
INSERT INTO personnes (nom) VALUES ('Durand') ;
INSERT 0 1
SELECT * FROM personnes ;
id | nom
----+--------
1 | Dupont
2 | Durand
(2 lignes)
INSERT INTO personnes (id,nom) VALUES (3,'Martin') ;
ERROR: cannot insert into column "id"
DÉTAIL : Column "id" is an identity column defined as GENERATED ALWAYS.
ASTUCE : Use OVERRIDING SYSTEM VALUE to override.
INSERT INTO personnes (id,nom) OVERRIDING SYSTEM VALUE VALUES (3,'Martin') ;
INSERT 0 1
INSERT INTO personnes (id,nom) OVERRIDING SYSTEM VALUE VALUES (3,'Dupond') ;
INSERT 0 1
SELECT * FROM personnes ;
id | nom
----+--------
1 | Dupont
2 | Durand
3 | Martin
3 | Dupond
III-B-30. Mise à jour de la clé primaire▲
-
Que faire en cas de mise à jour d’une clé primaire ?
- les clés étrangères seront fausses.
- ON UPDATE.
- ON DELETE.
-
Définition d’une action au niveau de la clé étrangère :
- interdiction,
- propagation de la mise à jour,
- NULL,
- valeur par défaut.
Si des valeurs d’une clé primaire sont mises à jour ou supprimées, cela peut entraîner des incohérences dans la base de données si des valeurs de clés étrangères font référence aux valeurs de la clé primaire touchées par le changement.
Afin de pouvoir gérer cela, la norme SQL prévoit plusieurs comportements possibles. La clause ON UPDATE permet de définir comment le SGBD va réagir si la clé primaire référencée est mise à jour. La clause ON DELETE en fait de même pour les suppressions.
Les actions possibles sont :
- NO ACTION (ou RESTRICT), qui produit une erreur si une ligne référence encore la ou les lignes touchées par le changement.
- CASCADE, pour laquelle la mise à jour ou la suppression est propagée aux valeurs référençant la ou les lignes touchées par le changement.
- SET NULL, la valeur de la colonne devient NULL.
- SET DEFAULT, pour lequel la valeur de la colonne prend la valeur par défaut de la colonne.
Le comportement par défaut est NO ACTION, ce qui est habituellement recommandé pour éviter les suppressions en chaîne mal maîtrisées.
Exemples :
Les exemples reprennent les tables mere et fille créées plus haut.
Tentative d’insertion d’une ligne dont la valeur de mere_id n’existe pas dans la table mere :
2.
3.
4.
INSERT INTO fille (id, mere_id, t) VALUES (1, 3, 'val3');
ERROR: insert or update on table "fille" violates foreign key constraint
"fk_mere_fille"
DETAIL: Key (mere_id)=(3) is not present in table "mere".
Mise à jour d’une ligne de la table mere pour modifier son id. La clé étrangère est déclarée ON UPDATE NO ACTION, donc la mise à jour devrait être interdite :
2.
3.
4.
UPDATE mere SET id = 3 WHERE id = 1;
ERROR: update or delete on table "mere" violates foreign key constraint
"fk_mere_fille" on table "fille"
DETAIL: Key (id)=(1) is still referenced from table "fille".
Suppression d’une ligne de la table mere. La clé étrangère sur fille est déclarée ON DELETE CASCADE, la suppression sera donc propagée aux tables qui référencent la table mere :
DELETE FROM mere WHERE id = 1;
SELECT * FROM fille ;
id | mere_id | t
----+---------+------
2 | 2 | val2
(1 row)III-B-31. Vérifications▲
-
Présence d’une valeur :
- NOT NULL.
-
Vérification de la valeur d’une colonne :
- CHECK.
La clause NOT NULL permet de s’assurer que la valeur de la colonne portant cette contrainte est renseignée. Dit autrement, elle doit obligatoirement être renseignée. Par défaut, la colonne peut avoir une valeur NULL, donc n’est pas obligatoirement renseignée.
La clause CHECK spécifie une expression de résultat booléen que les nouvelles lignes ou celles mises à jour doivent satisfaire pour qu’une opération d’insertion ou de mise à jour réussisse. Les expressions de résultat TRUE ou UNKNOWN réussissent. Si une des lignes de l’opération d’insertion ou de mise à jour produit un résultat FALSE, une exception est levée et la base de données n’est pas modifiée. Une contrainte de vérification sur une colonne ne fait référence qu’à la valeur de la colonne, tandis qu’une contrainte sur la table fait référence à plusieurs colonnes.
Actuellement, les expressions CHECK ne peuvent ni contenir des sous-requêtes, ni faire référence à des variables autres que les colonnes de la ligne courante. C’est techniquement réalisable, mais non supporté.
III-B-31-a. Vérifications différées▲
-
Vérifications après chaque ordre SQL :
- problèmes de cohérence.
-
Différer les vérifications de contraintes :
- clause DEFERRABLE, NOT DEFERRABLE,
- INITIALLY DEFERED, INITIALLY IMMEDIATE.
Par défaut, toutes les contraintes d’intégrité sont vérifiées lors de l’exécution de chaque ordre SQL de modification, y compris dans une transaction. Cela peut poser des problèmes de cohérences de données : insérer dans une table fille alors qu’on n’a pas encore inséré les données dans la table mère, la clé étrangère de la table fille va rejeter l’insertion et annuler la transaction.
Le moment où les contraintes sont vérifiées est modifiable dynamiquement par l’ordre SET CONSTRAINTS :
SET CONSTRAINTS { ALL | nom [, ...] } { DEFERRED | IMMEDIATE }mais ce n’est utilisable que pour les contraintes déclarées comme différables.
Voici quelques exemples :
- Avec la définition précédente des tables mere et fille:
b1=# BEGIN;
UPDATE mere SET id=3 where id=1;
ERROR: update or delete on table "mere" violates foreign key constraint
"fk_mere_fille" on table "fille"
DETAIL: Key (id)=(1) is still referenced from table "fille".- Cette erreur survient aussi dans le cas où on demande que la vérification des contraintes soit différée pour cette transaction :
BEGIN;
SET CONSTRAINTS ALL DEFERRED;
UPDATE mere SET id=3 WHERE id=1;
ERROR: update or delete on table "mere" violates foreign key constraint
"fk_mere_fille" on table "fille"
DETAIL: Key (id)=(1) is still referenced from table "fille".- Il faut que la contrainte soit déclarée comme étant différable :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
CREATE TABLE mere (id integer, t text);
CREATE TABLE fille (id integer, mere_id integer, t text);
ALTER TABLE mere ADD CONSTRAINT pk_mere PRIMARY KEY (id);
ALTER TABLE fille
ADD CONSTRAINT fk_mere_fille
FOREIGN KEY (mere_id)
REFERENCES mere (id)
MATCH FULL
ON UPDATE NO ACTION
ON DELETE CASCADE
DEFERRABLE;
INSERT INTO mere (id, t) VALUES (1, 'val1'), (2, 'val2');
INSERT INTO fille (id, mere_id, t) VALUES (1, 1, 'val1');
INSERT INTO fille (id, mere_id, t) VALUES (2, 2, 'val2');
BEGIN;
SET CONSTRAINTS all deferred;
UPDATE mere SET id=3 WHERE id=1;
SELECT * FROM mere;
id | t
----+------
2 | val2
3 | val1
(2 rows)
SELECT * FROM fille;
id | mere_id | t
----+---------+------
1 | 1 | val1
2 | 2 | val2
(2 rows)
UPDATE fille SET mere_id=3 WHERE mere_id=1;
COMMIT;
III-B-31-b. Vérifications plus complexes▲
-
Un trigger :
- si une contrainte porte sur plusieurs tables,
- si sa vérification nécessite une sous-requête.
- Préférer les contraintes déclaratives.
Les contraintes d’intégrités du SGBD ne permettent pas d’exprimer une contrainte qui porte sur plusieurs tables ou simplement si sa vérification nécessite une sous-requête. Dans ce cas-là, il est nécessaire d’écrire un trigger spécifique qui sera déclenché après chaque modification pour valider la contrainte.
Il ne faut toutefois pas systématiser l’utilisation de triggers pour valider des contraintes d’intégrité. Cela aurait un impact fort sur les performances et sur la maintenabilité de la base de données. Il vaut mieux privilégier les contraintes déclaratives et n’envisager l’emploi de triggers que dans les cas où ils sont réellement nécessaires.
III-C. DML : mise à jour des données▲
-
SELECT peut lire les données d’une table ou plusieurs tables :
- mais ne peut pas les mettre à jour.
-
Ajout de données dans une table :
- INSERT.
-
Modification des données d’une table :
- UPDATE.
-
Suppression des données d’une table ;
- DELETE.
L’ordre SELECT permet de lire une ou plusieurs tables. Les mises à jour utilisent des ordres distincts.
L’ordre INSERT permet d’ajouter ou insérer des données dans une table. L’ordre UPDATE permet de modifier des lignes déjà existantes. Enfin, l’ordre DELETE permet de supprimer des lignes. Ces ordres ne peuvent travailler que sur une seule table à la fois. Si on souhaite par exemple insérer des données dans deux tables, il est nécessaire de réaliser deux INSERT distincts.
III-C-1. Ajout de données : INSERT▲
- Ajoute des lignes à partir des données de la requête.
- Ajoute des lignes à partir d’une requête SELECT.
- Syntaxe :
INSERT INTO nom_table [ ( nom_colonne [, ...] ) ]
{ liste_valeurs | requete }L’ordre INSERT insère de nouvelles lignes dans une table. Il permet d’insérer une ou plusieurs lignes spécifiées par les expressions de valeurs, ou zéro ou plusieurs lignes provenant d’une requête.
La liste des noms de colonnes est optionnelle. Si elle n’est pas spécifiée, alors PostgreSQL utilisera implicitement la liste de toutes les colonnes de la table dans l’ordre de leur déclaration, ou les N premiers noms de colonnes si seules N valeurs de colonnes sont fournies dans la clause VALUES ou dans la requête. L’ordre des noms des colonnes dans la liste n’a pas d’importance particulière, il suffit de nommer les colonnes mises à jour.
Chaque colonne absente de la liste, implicite ou explicite, se voit attribuer sa valeur par défaut, s’il y en a une ou NULL dans le cas contraire. Les expressions de colonnes qui ne correspondent pas au type de données déclarées sont transtypées automatiquement, dans la mesure du possible.
III-C-2. INSERT avec liste d’expressions▲
INSERT INTO nom_table [ ( nom_colonne [, ...] ) ]
VALUES ( { expression | DEFAULT } [, ...] ) [, ...]La clause VALUES permet de définir une liste d’expressions qui va constituer la ligne à insérer dans la base de données. Les éléments de cette liste d’expression sont séparés par une virgule. Cette liste d’expression est composée de constantes ou d’appels à des fonctions retournant une valeur, pour obtenir par exemple la date courante ou la prochaine valeur d’une séquence. Les valeurs fournies par la clause VALUES ou par la requête sont associées à la liste explicite ou implicite des colonnes de gauche à droite.
Exemples :
Insertion d’une ligne dans la table stock :
INSERT INTO stock (vin_id, contenant_id, annee, nombre)
VALUES (12, 1, 1935, 1);Insertion d’une ligne dans la table vin :
INSERT INTO vin (id, recoltant_id, appellation_id, type_vin_id)
VALUES (nextval('vin_id_seq'), 3, 6, 1);III-C-3. INSERT à partir d’un SELECT▲
INSERT INTO nom_table [ ( nom_colonne [, ...] ) ]
requêteL’ordre INSERT peut aussi prendre une requête SQL en entrée. Dans ce cas, INSERT va insérer autant de lignes dans la table d’arrivée qu’il y a de lignes retournées par la requête SELECT. L’ordre des colonnes retournées par SELECT doit correspondre à l’ordre des colonnes de la liste des colonnes. Leur type de données doit également correspondre.
Exemple :
Insertion dans une table stock2 à partir d’une requête SELECT sur la table stock1 :
INSERT INTO stock2 (vin_id, contenant_id, annee, nombre)
SELECT vin_id, contenant_id, annee, nombre FROM stock;III-C-4. INSERT et colonnes implicites▲
-
L’ordre physique peut changer dans le temps :
- résultats incohérents,
- requêtes en erreurs.
Il est préférable de lister explicitement les colonnes touchées par l’ordre INSERT afin de garder un ordre d’insertion déterministe. En effet, l’ordre des colonnes peut changer, notamment lorsque certains ETL sont utilisés pour modifier le type d’une colonne varchar(10) en varchar(11). Par exemple, pour la colonne username, l’ETL Kettle génère les ordres suivants :
2.
3.
4.
ALTER TABLE utilisateurs ADD COLUMN username_KTL VARCHAR(11);
UPDATE utilisateurs SET username_KTL=username;
ALTER TABLE utilisateurs DROP COLUMN username;
ALTER TABLE utilisateurs RENAME username_KTL TO username
Il génère des ordres SQL inutiles et consommateurs d’entrées/sorties disques, car il doit générer des ordres SQL compris par tous les SGBD du marché. Or, tous les SGBD ne permettent pas de changer le type d’une colonne aussi simplement que dans PostgreSQL.
Exemple :
Exemple de modification du schéma pouvant entraîner des problèmes d’insertion si les colonnes ne sont pas listées explicitement :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
CREATE TABLE insere (id integer PRIMARY KEY, col1 varchar(5), col2 integer);
INSERT INTO insere VALUES (1, 'XX', 10);
ALTER TABLE insere ADD COLUMN col1_tmp varchar(6);
UPDATE insere SET col1_tmp = col1;
ALTER TABLE insere DROP COLUMN col1;
ALTER TABLE insere RENAME COLUMN col1_tmp TO col1;
INSERT INTO insere VALUES (2, 'XXX', 10);
ERROR: invalid input syntax for integer: "XXX"
LINE 1: INSERT INTO insere VALUES (2, 'XXX', 10);
III-C-5. Mise à jour de données : UPDATE▲
- Ordre UPDATE.
-
Met à jour une ou plusieurs colonnes d’une même ligne :
- à partir des valeurs de la requête,
- à partir des anciennes valeurs,
- à partir d’une requête SELECT,
- à partir de valeurs d’une autre table.
L’ordre de mise à jour de lignes s’appelle UPDATE.
III-C-5-a. Construction d’UPDATE▲
2.
3.
4.
5.
6.
7.
8.
9.
UPDATE nom_table
SET
{
nom_colonne = { expression | DEFAULT }
|
( nom_colonne [, ...] ) = ( { expression | DEFAULT } [, ...] )
} [, ...]
[ FROM liste_from ]
[ WHERE condition | WHERE CURRENT OF nom_curseur ]
L’ordre UPDATE permet de mettre à jour les lignes d’une table.
L’ordre UPDATE ne met à jour que les lignes qui satisfont les conditions de la clause WHERE. La clause SET permet de définir les colonnes à mettre à jour. Les noms des colonnes mises à jour doivent faire partie de la table mise à jour.
Les valeurs mises à jour peuvent faire référence aux valeurs avant mise à jour de la colonne, dans ce cas on utilise la forme nom_colonne = nom_colonne. La partie de gauche référence la colonne à mettre à jour, la partie de droite est une expression qui permet de déterminer la valeur à appliquer à la colonne. La valeur à appliquer peut bien entendu être une référence à une ou plusieurs colonnes et elle peut être dérivée par une opération arithmétique.
La clause FROM ne fait pas partie de la norme SQL, mais certains SGBDR la supportent, notamment SQL Server et PostgreSQL. Elle permet de réaliser facilement la mise à jour d’une table à partir des valeurs d’une ou plusieurs tables annexes.
La norme SQL permet néanmoins de réaliser des mises à jour en utilisant une sous-requête, permettant d’éviter l’usage de la clause FROM.
Exemples :
Mise à jour du prix d’un livre particulier :
UPDATE livres SET prix = 10 WHERE isbn = '978-3-8365-3872-5';
Augmentation de 5% du prix des livres :
UPDATE livres SET prix = prix * 1.05;
Mise à jour d’une table employees à partir des données d’une table bonus_plan :
2.
3.
4.
UPDATE employees e
SET commission_rate = bp.commission_rate
FROM bonus_plan bp
ON (e.bonus_plan = bp.planid)
La même requête avec une sous-requête, conforme à la norme SQL :
2.
3.
4.
UPDATE employees
SET commission_rate = (SELECT commission_rate
FROM bonus_plan bp
WHERE bp.planid = employees.bonus_plan);
Lorsque plusieurs colonnes doivent être mises à jour à partir d’une jointure, il est possible d’utiliser ces deux écritures :
2.
3.
4.
5.
UPDATE employees e
SET commission_rate = bp.commission_rate,
commission_rate2 = bp.commission_rate2
FROM bonus_plan bp
ON (e.bonus_plan = bp.planid);
Et
2.
3.
4.
5.
UPDATE employees e
SET (commission_rate, commission_rate2) = (
SELECT bp.commission_rate, bp.commission_rate2
FROM bonus_plan bp ON (e.bonus_plan = bp.planid)
);
III-C-6. Suppression de données : DELETE▲
- Supprime les lignes répondant au prédicat.
- Syntaxe :
DELETE FROM nom_table [ [ AS ] alias ]
[ WHERE conditionL’ordre DELETE supprime l’ensemble des lignes qui répondent au prédicat de la clause WHERE.
DELETE FROM nom_table [ [ AS ] alias ]
[ WHERE condition | WHERE CURRENT OF nom_curseur ]Exemple :
Suppression d’un livre épuisé du catalogue :
DELETE FROM livres WHERE isbn = '978-0-8707-0635-6';
III-C-7. Clause RETURNING▲
- Spécifique à PostgreSQL
- Permet de retourner les lignes complètes ou partielles résultants de INSERT, UPDATE ou DELETE
- Syntaxe :
requete_sql RETURNING(*|expression)
La clause RETURNING est une extension de PostgreSQL. Elle permet de retourner les lignes insérées, mises à jour ou supprimées par un ordre DML de modification. Il est également possible de dériver une valeur retournée.
L’emploi de la clause RETURNING peut nécessiter des droits complémentaires sur les objets de la base.
Exemple :
Mise à jour du nombre de bouteilles en stock :
SELECT annee, nombre FROM stock
WHERE vin_id = 7 AND contenant_id = 1 AND annee = 1967;
annee | nombre
-------+--------
1967 | 17
(1 row)
UPDATE stock SET nombre = nombre - 1
WHERE vin_id = 7 AND contenant_id = 1 AND annee = 1967 RETURNING nombre;
nombre
--------
16
(1 row)III-D. Transactions▲
-
ACID :
- atomicité,
- un traitement se fait en entier ou pas du tout.
-
TCL pour Transaction Control Language :
- valide une transaction,
- annule une transaction,
- points de sauvegarde.
Les transactions sont une partie essentielle du langage SQL. Elles permettent de rendre atomique un certain nombre de requêtes. Le résultat de toutes les requêtes d’une transaction est validé ou pas, mais on ne peut pas avoir d’état intermédiaire.
Le langage SQL définit qu’une transaction peut être validée ou annulée. Ce sont respectivement les ordres COMMIT et ROLLBACK. Il est aussi possible de faire des points de reprise ou de sauvegarde dans une transaction. Ils se font en utilisant l’ordre SAVEPOINT.
III-D-1. Auto-commit et transactions▲
-
Par défaut, PostgreSQL fonctionne en auto-commit :
- à moins d’ouvrir explicitement une transaction.
-
Ouvrir une transaction :
- BEGIN TRANSACTION.
PostgreSQL fonctionne en auto-commit. Autrement dit, sans BEGIN, une requête est considérée comme une transaction complète et n’a donc pas besoin de COMMIT.
Une transaction débute toujours par un START ou un BEGIN.
III-D-2. Validation ou annulation d’une transaction▲
-
Valider une transaction :
- COMMIT.
-
Annuler une transaction :
- ROLLBACK.
- Sans validation, une transaction est forcément annulée.
Une transaction est toujours terminée par un COMMIT ou un END quand on veut que les modifications soient définitivement enregistrées, et par un ROLLBACK dans le cas contraire.
La transaction en cours d’une session qui se termine, quelle que soit la raison, sans COMMIT et sans ROLLBACK est considérée comme annulée.
Exemple :
Avant de retirer une bouteille du stock, on vérifie tout d’abord qu’il reste suffisamment de bouteilles en stock :
BEGIN TRANSACTION;
SELECT annee, nombre FROM stock WHERE vin_id = 7 AND contenant_id = 1
AND annee = 1967;
annee | nombre
-------+--------
1967 | 17
(1 row)
UPDATE stock SET nombre = nombre - 1
WHERE vin_id = 7 AND contenant_id = 1 AND annee = 1967 RETURNING nombre;
nombre
--------
16
(1 row)
COMMIT;III-D-3. Programmation▲
-
Certains langages implémentent des méthodes de gestion des transactions :
- PHP, Java, etc.
- Utiliser ces méthodes prioritairement.
La plupart des langages permettent de gérer les transactions à l’aide de méthodes ou fonctions particulières. Il est recommandé de les utiliser.
En Java, ouvrir une transaction revient à désactiver l’auto-commit :
2.
3.
4.
String url =
"jdbc:postgresql://localhost/test?user=fred&password=secret&ssl=true";
Connection conn = DriverManager.getConnection(url);
conn.setAutoCommit(false);
La transaction est confirmée (COMMIT) avec la méthode suivante :
conn.commit();
À l’inverse, elle est annulée (ROLLBACK) avec la méthode suivante :
conn.rollback();
III-D-4. Points de sauvegarde▲
-
Certains traitements dans une transaction peuvent être annulés :
- mais la transaction est atomique.
-
Définir un point de sauvegarde :
- SAVEPOINT nom_savepoint.
-
Valider le traitement depuis le dernier point de sauvegarde :
- RELEASE SAVEPOINT nom_savepoint.
-
Annuler le traitement depuis le dernier point de sauvegarde :
- ROLLBACK TO SAVEPOINT nom_savepoint.
Déroulé jusqu’au bout, le point de sauvegarde pourra être relâché (RELEASE SAVEPOINT), confirmant ainsi les traitements. Si le traitement tombe en erreur, il suffira de revenir au point de sauvegarde (ROLLBACK TO SAVEPOINT pour annuler uniquement cette partie du traitement sans affecter le reste de la transaction.
Les points de sauvegarde sont des éléments nommés, il convient donc de leur affecter un nom particulier. Leur nom doit être unique dans la transaction courante.
Les langages de programmation permettent également de gérer les points de sauvegarde en utilisant des méthodes dédiées. Par exemple, en Java :
Savepoint save1 = connection.setSavepoint();
En cas d’erreurs, la transaction peut être ramenée à l’état du point de sauvegarde avec :
connection.rollback(save1);
À l’inverse, un point de sauvegarde est relâché de la façon suivante :
connection.releaseSavepoint(save1);
Exemple :
Transaction avec un point de sauvegarde et la gestion de l’erreur :
BEGIN;
INSERT INTO mere (id, val_mere) VALUES (10, 'essai');
SAVEPOINT insert_fille;
INSERT INTO fille (id_fille, id_mere, val_fille) VALUES (1, 10, 'essai 2');
ERROR: duplicate key value violates unique constraint "fille_pkey"
DETAIL: Key (id_fille)=(1) already exists.
ROLLBACK TO SAVEPOINT insert_fille;
COMMIT;
SELECT * FROM mere;
id | val_mere
----+----------
1 | mere 1
2 | mere 2
10 | essaiIII-E. Conclusion▲
-
SQL : toujours un traitement d’ensembles d’enregistrements :
- c’est le côté relationnel.
-
Pour les définitions d’objets :
- CREATE, ALTER, DROP.
-
Pour les données :
- INSERT, UPDATE, DELETE.
Le standard SQL permet de traiter des ensembles d’enregistrements, que ce soit en lecture, en insertion, en modification et en suppression. Les ensembles d’enregistrements sont généralement des tables qui, comme tous les autres objets, sont créées (CREATE), modifiées (ALTER) et/ou supprimées (DROP).
III-F. Travaux pratiques▲
III-F-1. Énoncés▲
Pour cet exercice, les modifications de schéma doivent être effectuées par un rôle ayant suffisamment de droits pour modifier son schéma. Le rôle tpc_admin a les droits suffisants.
- Ajouter une colonne email de type text à la table contacts. Cette colonne va permettre de stocker l’adresse e-mail des clients et des fournisseurs. Ajouter également un commentaire décrivant cette colonne dans le catalogue de PostgreSQL (utiliser la commande COMMENT).
- Mettre à jour la table des contacts pour indiquer l’adresse e-mail de Client6657 qui est client6657@dalibo.com.
- Ajouter une contrainte d’intégrité qui valide que la valeur de la colonne email créée est bien formée (vérifier que la chaîne de caractères contient au moins le caractère @).
- Valider la contrainte dans une transaction de test.
- Déterminer quels sont les contacts qui disposent d’une adresse e-mail et afficher leur nom ainsi que le code de leur pays.
- La génération des numéros de commande est actuellement réalisée à l’aide de la séquence commandes_commande_id_seq. Cette méthode ne permet pas de garantir que tous les numéros de commande se suivent. Proposer une solution pour sérialiser la génération des numéros de commande. Autrement dit, proposer une méthode pour obtenir un numéro de commande sans avoir de « trou » dans la séquence en cas d’échec d’une transaction.
- Noter le nombre de lignes de la table pieces. Dans une transaction, majorer de 5% le prix des pièces de moins de 1500 € et minorer de 5 % le prix des pièces dont le prix actuel est égal ou supérieur à 1500 €. Vérifier que le nombre de lignes mises à jour au total correspond au nombre total de lignes de la table pieces.
- Dans une même transaction, créer un nouveau client en incluant l’ajout de l’ensemble des informations requises pour pouvoir le contacter. Un nouveau client a un solde égal à 0.
III-F-2. Solutions▲
- Ajouter une colonne email de type text à la table contacts. Cette colonne va permettre de stocker l’adresse e-mail des clients et des fournisseurs. Ajouter également un commentaire décrivant cette colonne dans le catalogue de PostgreSQL (utiliser la commande COMMENT).
2.
3.
4.
5.
6.
7.
ALTER TABLE contacts
ADD COLUMN email text
;
COMMENT ON COLUMN contacts.email IS
'Adresse e-mail du contact'
;
- Mettre à jour la table des contacts pour indiquer l’adresse e-mail de Client6657 qui est client6657@dalibo.com.
2.
3.
4.
UPDATE contacts
SET email = 'client6657@dalibo.com'
WHERE nom = 'Client6657'
;
- Vérifier les résultats :
2.
3.
4.
SELECT *
FROM contacts
WHERE nom = 'Client6657'
;
-
Ajouter une contrainte d’intégrité qui valide que la valeur de la colonne email créée est bien formée (vérifier que la chaîne de caractère contient au moins le caractère @).
Sélectionnez1.
2.
3.
4.ALTERTABLEcontactsADDCONSTRAINTchk_contacts_email_validCHECK(emailLIKE'%@%'); - Cette expression régulière est simplifiée et simpliste pour les besoins de l’exercice. Des expressions régulières plus complexes permettent de valider réellement une adresse e-mail.
Voici un exemple un tout petit peu plus évolué en utilisant une expression rationnelle simple, ici pour vérifier que la chaîne précédant le caractère @ contient au moins un caractère, et que la chaîne le suivant est une chaîne de caractères contenant un point :
2.
3.
4.
ALTER TABLE contacts
ADD CONSTRAINT chk_contacts_email_valid
CHECK (email ~ '.+@.+\..+')
;
- Valider la contrainte dans une transaction de test.
Démarrer la transaction :
BEGIN ;
Tenter de mettre à jour la table contacts avec une adresse e-mail ne répondant pas à la contrainte :
2.
3.
UPDATE contacts
SET email = 'test'
;
L’ordre UPDATE retourne l’erreur suivante, indiquant que l’expression régulière est fonctionnelle :
ERROR: new row for relation "contacts" violates check constraint
"chk_contacts_email_valid"
DETAIL: Failing row contains
(300001, Client1737, nkD, SA, 20-999-929-1440, test).La transaction est ensuite annulée :
ROLLBACK ;
- Déterminer quels sont les contacts qui disposent d’une adresse e-mail et afficher leur nom ainsi que le code de leur pays.
2.
3.
4.
SELECT nom, code_pays
FROM contacts
WHERE email IS NOT NULL
;
- La génération des numéros de commande est actuellement réalisée à l’aide de la séquence commandes_commande_id_seq. Cette méthode ne permet pas de garantir que tous les numéros de commande se suivent. Proposer une solution pour sérialiser la génération des numéros de commande. Autrement dit, proposer une méthode transactionnelle pour obtenir un numéro de commande, sans avoir de « trou » dans la séquence en cas d’échec d’une transaction.
La solution la plus simple pour imposer la sérialisation des numéros de commandes est d’utiliser une table de séquences. Une ligne de cette table correspondra au compteur des numéros de commande.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
-- création de la table qui va contenir la séquence :
CREATE TABLE numeros_sequences (
nom text NOT NULL PRIMARY KEY,
sequence integer NOT NULL
)
;
-- initialisation de la séquence :
INSERT INTO numeros_sequences (nom, sequence)
SELECT 'sequence_numero_commande', max(numero_commande)
FROM commandes
;
L’obtention d’un nouveau numéro de commande sera réalisée dans la transaction de création de la commande de la façon suivante :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
BEGIN ;
UPDATE numeros_sequences
SET sequence = sequence + 1
WHERE nom = 'numero_commande'
RETURNING sequence
;
/* insertion d'une nouvelle commande en utilisant le numéro de commande
retourné par la commande précédente :
INSERT INTO commandes (numero_commande, ...)
VALUES (<la nouvelle valeur de la séquence>, ...) ;
*/
COMMIT ;
L’ordre UPDATE pose un verrou exclusif sur la ligne mise à jour. Tant que la mise à jour n’aura pas été validée ou annulée par COMMIT ou ROLLBACK, le verrou posé va bloquer toutes les autres transactions qui tenteraient de mettre à jour cette ligne. De cette façon, toutes les transactions seront sérialisées.
Concernant la génération des numéros de séquence, si la transaction est annulée, alors le compteur sequence retrouvera sa valeur précédente et la transaction suivante obtiendra le même numéro de séquence. Si la transaction est validée, alors le compteur sequence est incrémenté. La transaction suivante verra alors cette nouvelle valeur et non plus l’ancienne. Cette méthode garantit qu’il n’y a pas de rupture de séquence.
Il va de soi que les transactions de création de commandes doivent être extrêmement courtes. Si une telle transaction est bloquée, toutes les transactions suivantes seront également bloquées, paralysant ainsi tous les utilisateurs de l’application.
- Noter le nombre de lignes de la table pieces. Dans une transaction, majorer de 5 % le prix des pièces de moins de 1500 € et minorer de 5 % le prix des pièces dont le prix actuel est égal ou supérieur à 1500 €. Vérifier que le nombre de lignes mises à jour au total correspond au nombre total de lignes de la table pieces.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
BEGIN ;
SELECT count(*)
FROM pieces
;
UPDATE pieces
SET prix = prix * 1.05
WHERE prix < 1500
;
UPDATE pieces
SET prix = prix * 0.95
WHERE prix >= 1500
;
Au total, la transaction a mis à jour 214200 (99922+114278) lignes, soit 14200 lignes de trop mises à jour.
Annuler la mise à jour :
ROLLBACK ;
Explication : Le premier UPDATE a majoré de 5 % les pièces dont le prix est inférieur à 1500 €. Or, tous les prix supérieurs à 1428,58 € passent la barre des 1500 € après le premier UPDATE. Le second UPDATE minore les pièces dont le prix est égal ou supérieur à 1500 €, ce qui inclut une partie des prix majorés par le précédent UPDATE. Certaines lignes ont donc subi deux modifications au lieu d’une. L’instruction CASE du langage SQL, qui sera abordée dans le prochain module, propose une solution à ce genre de problématique :
2.
3.
4.
5.
6.
7.
8.
UPDATE pieces
SET prix = (
CASE
WHEN prix < 1500 THEN prix * 1.05
WHEN prix >= 1500 THEN prix * 0.95
END
)
;
- Dans une même transaction, créer un nouveau client en incluant l’ajout de l’ensemble des informations requises pour pouvoir le contacter. Un nouveau client a un solde égal à 0.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
-- démarrer la transaction
BEGIN ;
-- créer le contact et récupérer le contact_id généré
INSERT INTO contacts (nom, adresse, telephone, code_pays)
VALUES ('M. Xyz', '3, Rue du Champignon, 96000 Champiville',
'+33554325432', 'FR')
RETURNING contact_id
;
-- réaliser l'insertion en utilisant le numéro de contact récupéré précédemment
INSERT INTO clients (solde, segment_marche, contact_id, commentaire)
-- par exemple ici avec le numéro 350002
VALUES (0, 'AUTOMOBILE', 350002, 'Client très important')
;
-- valider la transaction
COMMIT ;
