


IV. Plus loin avec SQL▲
IV-A. Préambule▲
- Après la définition des objets, leur lecture et leur écriture.
-
Aller plus loin dans l’écriture de requêtes :
- avec les jointures,
- avec les requêtes intégrées.
Maintenant que nous avons vu comment définir des objets, comment lire des données provenant de relations et comment écrire des données, nous allons pousser vers les perfectionnements du langage SQL. Nous allons notamment aborder la lecture de plusieurs tables en même temps, que ce soit par des jointures ou par des sous-requêtes.
IV-A-1. Menu▲
- Valeur NULL.
- Agrégats, GROUP BY, HAVING.
- Sous-requêtes.
- Jointures.
- Expression conditionnelle CASE.
- Opérateurs ensemblistes : UNION, EXCEPT, INTERSECT.
IV-A-2. Objectifs▲
- Comprendre l’intérêt du NULL.
- Savoir écrire des requêtes complexes.
IV-B. Valeur NULL▲
-
Comment représenter une valeur que l’on ne connaît pas ?
- Valeur NULL.
-
Trois sens possibles pour NULL :
- valeur inconnue,
- valeur inapplicable,
- absence de valeur.
- Logique trois états.
Le standard SQL définit très précisément la valeur que doit avoir une colonne dont on ne connaît pas la valeur. Il faut utiliser le mot-clé NULL. En fait, ce mot-clé est utilisé dans trois cas : pour les valeurs inconnues, pour les valeurs inapplicables et pour une absence de valeurs.
IV-B-1. Avertissement▲
-
Chris J. Date a écrit :
- La valeur NULL telle qu’elle est implémentée dans SQL peut poser plus de problèmes qu’elle n’en résout. Son comportement est parfois étrange et est source de nombreuses erreurs et de confusions.
-
Éviter d’utiliser NULL le plus possible :
- utiliser NULL correctement lorsqu’il le faut.
Il ne faut utiliser NULL que lorsque cela est réellement nécessaire. La gestion des valeurs NULL est souvent source de confusions et d’erreurs, ce qui explique qu’il est préférable de l’éviter tant qu’on n’entre pas dans les trois cas vus ci-dessus (valeur inconnue, valeur inapplicable, absence de valeur).
IV-B-2. Assignation de NULL▲
- Assignation de NULL pour INSERT et UPDATE.
-
Explicitement :
- NULL est indiqué explicitement dans les assignations.
-
Implicitement :
- la colonne n’est pas affectée par INSERT,
- et n’a pas de valeur par défaut.
-
Empêcher la valeur NULL :
- contrainte NOT NULL.
Il est possible de donner le mot-clé NULL pour certaines colonnes dans les INSERT et les UPDATE. Si jamais une colonne n’est pas indiquée dans un INSERT, elle aura comme valeur sa valeur par défaut (très souvent, il s’agit de NULL). Si jamais on veut toujours avoir une valeur dans une colonne particulière, il faut utiliser la clause NOT NULL lors de l’ajout de la colonne. C’est le cas pour les clés primaires par exemple.
Voici quelques exemples d’insertion et de mise à jour :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
CREATE TABLE public.personnes
(
id serial,
nom character varying(60) NOT NULL,
prenom character varying(60),
date_naissance date,
CONSTRAINT pk_personnes PRIMARY KEY (id)
);
INSERT INTO personnes(
nom, prenom, date_naissance)
VALUES ('Lagaffe', 'Gaston', date '1957-02-28');
-- assignation explicite
INSERT INTO personnes(
nom, prenom, date_naissance)
VALUES ('Fantasio', NULL, date '1938-01-01');
-- assignation implicite
INSERT INTO personnes(
nom, prenom)
VALUES ('Prunelle', 'Léon');
-- observation des résultats
id | nom | prenom | date_naissance
----+----------+--------+----------------
1 | Lagaffe | Gaston | 1957-02-28
2 | Fantasio | (null) | 1938-01-01
3 | Prunelle | Léon | (null)
(3 rows)
L’affichage (null) dans psql est obtenu avec la métacommande \pset null (null).
IV-B-3. Calculs avec NULL▲
-
Utilisation dans un calcul :
- propagation de NULL.
-
NULL est inapplicable :
- le résultat vaut NULL.
La valeur NULL est définie comme inapplicable. Ainsi, si elle est présente dans un calcul, elle est propagée sur l’ensemble du calcul : le résultat vaudra NULL.
Exemples de calcul :
Calculs simples :
SELECT 1 + 2 AS resultat;
resultat
----------
3
(1 row)
SELECT 1 + 2 + NULL AS resultat;
resultat
----------
(null)
(1 row)Calcul à partir de l’âge :
SELECT nom, prenom,
1 + extract('year' from age(date_naissance)) AS calcul_age FROM personnes;
nom | prenom | calcul_age
----------+--------+------------
Lagaffe | Gaston | 60
Fantasio | (null) | 79
Prunelle | Léon | (null)
(3 rows)Exemple d’utilisation de NULL dans une concaténation :
SELECT nom || ' ' || prenom AS nom_complet FROM personnes;
nom_complet
----------------
Lagaffe Gaston
(null)
Prunelle Léon
(3 rows)L’affichage (null) est obtenu avec la métacommande \pset null (null) du shell psql.
IV-B-4. NULL et les prédicats▲
-
Dans un prédicat du WHERE :
- opérateur IS NULL ou IS NOT NULL.
-
AND :
- vaut false si NULL AND false,
- vaut NULL si NULL AND true ou NULL AND NULL.
-
OR :
- vaut true si NULL OR true ,
- vaut NULL si NULL OR false ou NULL OR NULL.
Les opérateurs de comparaisons classiques ne sont pas fonctionnels avec une valeur NULL. Du fait de la logique à trois états de PostgreSQL, une comparaison avec NULL vaut toujours NULL, ainsi expression = NULL vaudra toujours NULL et de même pour expression <> NULL vaudra toujours NULL. Cette comparaison ne vaudra jamais ni vrai ni faux.
De ce fait, il existe les opérateurs de prédicats IS NULL et IS NOT NULL qui permettent de vérifier qu’une expression est NULL ou n’est pas NULL.
Pour en savoir plus sur la logique ternaire qui régit les règles de calcul des prédicats, se conformer à la page Wikipédia sur la logique ternaire .
Exemples :
Comparaison directe avec NULL, qui est invalide :
SELECT * FROM personnes WHERE date_naissance = NULL;
id | nom | prenom | date_naissance
----+-----+--------+----------------
(0 rows)L’opérateur IS NULL permet de retourner les lignes dont la date de naissance n’est pas renseignée :
SELECT * FROM personnes WHERE date_naissance IS NULL;
id | nom | prenom | date_naissance
----+----------+--------+----------------
3 | Prunelle | Léon | (null)
(1 row)IV-B-5. NULL et les agrégats▲
-
Opérateurs d’agrégats :
- ignorent NULL,
- sauf count(*).
Les fonctions d’agrégats ne tiennent pas compte des valeurs NULL :
SELECT SUM(extract('year' from age(date_naissance))) AS age_cumule
FROM personnes;
age_cumule
------------
139
(1 row)Sauf count(*) et uniquement count(*), la fonction count(_expression_) tient compte des valeurs NULL :
SELECT count(*) AS compte_lignes, count(date_naissance) AS compte_valeurs
FROM (SELECT date_naissance
FROM personnes) date_naissance;
compte_lignes | compte_valeurs
---------------+----------------
3 | 2
(1 row)IV-B-6. COALESCE▲
-
Remplacer NULL par une autre valeur :
- COALESCE(attribut, ...);.
Cette fonction permet de tester une colonne et de récupérer sa valeur si elle n’est pas NULL et une autre valeur dans le cas contraire. Elle peut avoir plus de deux arguments. Dans ce cas, la première expression de la liste qui ne vaut pas NULL sera retournée par la fonction.
Voici quelques exemples :
Remplacer les prénoms non renseignés par la valeur X dans le résultat :
SELECT nom, COALESCE(prenom, 'X') FROM personnes;
nom | coalesce
----------+----------
Lagaffe | Gaston
Fantasio | X
Prunelle | Léon
(3 rows)Cette fonction est efficace également pour la concaténation précédente :
SELECT nom || ' ' || COALESCE(prenom, '') AS nom_complet FROM personnes;
nom_complet
----------------
Lagaffe Gaston
Fantasio
Prunelle Léon
(3 rows)IV-C. Agrégats▲
- Regroupement de données.
- Calculs d’agrégats.
Comme son nom l’indique, l’agrégation permet de regrouper des données, qu’elles viennent d’une ou de plusieurs colonnes. Le but est principalement de réaliser des calculs sur les données des lignes regroupées.
IV-C-1. Regroupement de données▲
- Regroupement de données :
GROUPBYexpression[, ...]. - Chaque groupe de données est ensuite représenté sur une seule ligne.
-
Permet d’appliquer des calculs sur les ensembles regroupés :
- comptage, somme, moyenne, etc.
La clause GROUP BY permet de réaliser des regroupements de données. Les données regroupées sont alors représentées sur une seule ligne. Le principal intérêt de ces regroupements est de permettre de réaliser des calculs sur ces données.
IV-C-2. Calculs d’agrégats▲
-
Effectue un calcul sur un ensemble de valeurs :
- somme, moyenne, etc.
-
Retourne NULL si l’ensemble est vide :
- sauf count()
Nous allons voir les différentes fonctions d’agrégats disponibles.
IV-C-3. Agrégats simples▲
-
Comptage :
count(expression)- compte les lignes :
count(*), - compte les valeurs renseignées :
count(colonne),
- compte les lignes :
- Valeur minimale :
min(expression) - Valeur maximale :
max(expression)
La fonction count() permet de compter les éléments. La fonction est appelée de deux façons.
La première forme consiste à utiliser count(*) qui revient à transmettre la ligne complète à la fonction d’agrégat. Ainsi, toute ligne transmise à la fonction sera comptée, même si elle n’est composée que de valeurs NULL. On rencontre parfois une forme du type count(1), qui transmet une valeur arbitraire à la fonction, et qui permettait d’accélérer le temps de traitement sur certains SGBD, mais qui reste sans intérêt avec PostgreSQL.
La seconde forme consiste à utiliser une expression, par exemple le nom d’une colonne : count(nom_colonne). Dans ce cas-là, seules les valeurs renseignées, donc non NULL, seront prises en compte. Les valeurs NULL seront exclues du comptage.
La fonction min() permet de déterminer la valeur la plus petite d’un ensemble de valeurs données. La fonction max() permet à l’inverse de déterminer la valeur la plus grande d’un ensemble de valeurs données. Les valeurs NULL sont bien ignorées. Ces deux fonctions permettent de travailler sur des données numériques, mais fonctionnent également sur les autres types de données comme les chaînes de caractères.
La documentation de PostgreSQL permet d’obtenir la liste des fonctions d’agrégats disponibles.
Exemples :
Différences entre count(*) et count(colonne) :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
CREATE TABLE test (x INTEGER);
-- insertion de cinq lignes dans la table test
INSERT INTO test (x) VALUES (1), (2), (2), (NULL), (NULL);
SELECT x, count(*) AS count_etoile, count(x) AS count_x FROM test GROUP BY x;
x | count_etoile | count_x
--------+--------------+---------
(null) | 2 | 0
1 | 1 | 1
2 | 2 | 2
(3 rows)
Déterminer la date de naissance de la personne la plus jeune :
SELECT MAX(date_naissance) FROM personnes;
max
------------
1957-02-28
(1 row)IV-C-4. Calculs d’agrégats▲
- Moyenne :
avg(expression) - Somme :
sum(expression) - Écart-type :
stddev(expression) - Variance :
variance(expression)
La fonction avg() permet d’obtenir la moyenne d’un ensemble de valeurs données. La fonction sum() permet, quant à elle, d’obtenir la somme d’un ensemble de valeurs données. Enfin, les fonctions stddev() et variance() permettent d’obtenir respectivement l’écart-type et la variance d’un ensemble de valeurs données.
Ces fonctions retournent NULL si aucune donnée n’est applicable. Elles ne prennent en compte que des valeurs numériques.
La documentation de PostgreSQL permet d’obtenir la liste des fonctions d’agrégats disponibles.
Exemples :
Quel est le nombre total de bouteilles en stock par millésime ?
2.
3.
4.
5.
6.
7.
SELECT annee, sum(nombre) FROM stock GROUP BY annee ORDER BY annee;
annee | sum
-------+--------
1950 | 210967
1951 | 201977
1952 | 202183
...
Calcul de moyenne avec des valeurs NULL :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
CREATE TABLE test (a int, b int);
INSERT INTO test VALUES (10,10);
INSERT INTO test VALUES (20,20);
INSERT INTO test VALUES (30,30);
INSERT INTO test VALUES (null,0);
SELECT avg(a), avg(b) FROM test;
avg | avg
---------------------+---------------------
20.0000000000000000 | 15.0000000000000000
(1 row)
IV-C-5. Agrégats sur plusieurs colonnes▲
- Possible d’avoir plusieurs paramètres sur la même fonction d’agrégat.
-
Quelques exemples :
- pente, regr_slope(Y,X),
- intersection avec l’axe des ordonnées, regr_intercept(Y,X),
- indice de corrélation, corr (Y,X).
Une fonction d’agrégat peut aussi prendre plusieurs variables.
Par exemple concernant la méthode des «moindres carrés» :
- Pente : regr_slope(Y,X).
- Intersection avec l’axe des ordonnées : regr_intercept(Y,X).
- Indice de corrélation : corr (Y,X).
Voici un exemple avec un nuage de points proches d’une fonction y=2x+5 :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
CREATE TABLE test (x real, y real);
INSERT INTO test VALUES (0,5.01), (1,6.99), (2,9.03);
SELECT regr_slope(y,x) FROM test;
regr_slope
------------------
2.00999975204468
(1 ligne)
SELECT regr_intercept(y,x) FROM test;
regr_intercept
------------------
5.00000015894572
(1 ligne)
SELECT corr(y,x) FROM test;
corr
-------------------
0.999962873745297
IV-C-6. Clause HAVING▲
-
Filtrer sur des regroupements :
- HAVING.
- WHERE s’applique sur les lignes lues.
- HAVING s’applique sur les lignes groupées.
La clause HAVING permet de filtrer les résultats sur les regroupements réalisés par la clause GROUP BY. Il est possible d’utiliser une fonction d’agrégat dans la clause HAVING.
Il faudra néanmoins faire attention à ne pas utiliser la clause HAVING comme clause de filtrage des données lues par la requête. La clause HAVING ne doit permettre de filtrer que les données traitées par la requête.
Ainsi, on souhaite le nombre de vins rouges référencés dans le catalogue. La requête va donc exclure toutes les données de la table vin qui ne correspondent pas au filtre type_vin = 3. Pour réaliser cela, on utilisera la clause WHERE.
En revanche, si l’on souhaite connaître le nombre de vins par type de cépage si ce nombre est supérieur à 2030, on utilisera la clause HAVING.
Exemples :
SELECT type_vin_id, count(*)
FROM vin
GROUP BY type_vin_id
HAVING count(*) > 2030;
type_vin_id | count
-------------+-------
1 | 2031Si la colonne correspondant à la fonction d’agrégat est renommée avec la clause AS, il n’est pas possible d’utiliser le nouveau nom au sein de la clause HAVING. Par exemple :
2.
3.
4.
5.
6.
SELECT type_vin_id, count(*) AS nombre
FROM vin
GROUP BY type_vin_id
HAVING nombre > 2030;
ERROR: column "nombre" does not exist
IV-D. Sous-requêtes▲
- Corrélation requête/sous-requête.
- Sous-requêtes retournant une seule ligne.
- Sous-requêtes retournant une liste de valeur.
- Sous-requêtes retournant un ensemble.
- Sous-requêtes retournant un ensemble vide ou non vide.
IV-D-1. Corrélation requête/sous-requête▲
- Fait référence à la requête principale.
- Peut utiliser une valeur issue de la requête principale.
Une sous-requête peut faire référence à des variables de la requête principale. Ces variables seront ainsi transformées en constante à chaque évaluation de la sous-requête.
La corrélation requête/sous-requête permet notamment de créer des clauses de filtrage dans la sous-requête en utilisant des éléments de la requête principale.
IV-D-2. Qu’est-ce qu’une sous-requête ?▲
- Une requête imbriquée dans une autre requête.
- Le résultat de la requête principale dépend du résultat de la sous-requête.
- Encadrée par des parenthèses : ( et ).
Une sous-requête consiste à exécuter une requête à l’intérieur d’une autre requête. La requête principale peut être une requête de sélection (SELECT) ou une requête de modification (INSERT, UPDATE, DELETE). La sous-requête est obligatoirement un SELECT.
Le résultat de la requête principale dépend du résultat de la sous-requête. La requête suivante effectue la sélection des colonnes d’une autre requête, qui est une sous-requête. La sous-requête effectue une lecture de la table appellation. Son résultat est transformé en un ensemble qui est nommé requete_appellation :
SELECT * FROM (SELECT libelle, region_id FROM appellation) requete_appellation;
libelle | region_id
-------------------------------------------+-----------
Ajaccio | 1
Aloxe-Corton | 2
...IV-D-3. Utiliser une seule ligne▲
-
La sous-requête ne retourne qu’une seule ligne :
- sinon une erreur est levée.
-
Positionnée :
- au niveau de la liste des expressions retournées par SELECT,
- au niveau de la clause WHERE,
- au niveau d’une clause HAVING.
La sous-requête peut être positionnée au niveau de la liste des expressions retournées par SELECT. La sous-requête est alors généralement un calcul d’agrégat qui ne donne en résultat qu’une seule colonne sur une seule ligne. Ce type de sous-requête est peu performant. Elle est en effet appelée pour chaque ligne retournée par la requête principale.
La requête suivante permet d’obtenir le cumul du nombre de bouteilles année par année.
SELECT annee,
sum(nombre) AS stock,
(SELECT sum(nombre)
FROM stock s
WHERE s.annee <= stock.annee) AS stock_cumule
FROM stock
GROUP BY annee
ORDER BY annee;
annee | stock | stock_cumule
-------+--------+--------------
1950 | 210967 | 210967
1951 | 201977 | 412944
1952 | 202183 | 615127
1953 | 202489 | 817616
1954 | 202041 | 1019657
...Une telle sous-requête peut également être positionnée au niveau de la clause WHERE ou de la clause HAVING.
Par exemple, pour retourner la liste des vins rouges :
2.
3.
4.
5.
SELECT *
FROM vin
WHERE type_vin_id = (SELECT id
FROM type_vin
WHERE libelle = 'rouge');
IV-D-4. Utiliser une liste de valeurs▲
-
La sous-requête retourne :
- plusieurs lignes,
- sur une seule colonne.
-
Positionnée :
- avec une clause IN,
- avec une clause ANY,
- avec une clause ALL.
Les sous-requêtes retournant une liste de valeurs sont plus fréquemment utilisées. Ce type de sous-requête permet de filtrer les résultats de la requête principale à partir des résultats de la sous-requête.
IV-D-5. Clause IN▲
expression IN (sous-requete)
- L’expression de gauche est évaluée et vérifiée avec la liste de valeurs de droite.
-
IN vaut true :
- si l’expression de gauche correspond à un élément de la liste de droite.
-
IN vaut false :
- si aucune correspondance n’est trouvée et la liste ne contient pas NULL.
-
IN vaut NULL :
- si l’expression de gauche vaut NULL,
- si aucune valeur ne correspond et la liste contient NULL.
La clause IN dans la requête principale permet alors d’exploiter le résultat de la sous-requête pour sélectionner les lignes dont une colonne correspond à une valeur retournée par la sous-requête.
L’opérateur IN retourne true si la valeur de l’expression de gauche est trouvée au moins une fois dans la liste de droite. La liste de droite peut contenir la valeur NULL dans ce cas :
SELECT 1 IN (1, 2, NULL) AS in;
in
----
tSi aucune correspondance n’est trouvée entre l’expression de gauche et la liste de droite, alors IN vaut false :
SELECT 1 IN (2, 4) AS in;
in
----
fMais IN vaut NULL si aucune correspondance n’est trouvée et que la liste de droite contient au moins une valeur NULL :
SELECT 1 IN (2, 4, NULL) AS in;
in
--------
(null)IN vaut également NULL si l’expression de gauche vaut NULL :
SELECT NULL IN (2, 4) AS in;
in
--------
(null)Exemples :
La requête suivante permet de sélectionner les bouteilles du stock de la cave dont la contenance est comprise entre 0,3 litre et 1 litre. Pour répondre à la question, la sous-requête retourne les identifiants de contenants qui correspondent à la condition. La requête principale ne retient alors que les lignes dont la colonne contenant_id correspond à une valeur d’identifiant retournée par la sous-requête.
2.
3.
4.
5.
6.
SELECT *
FROM stock
WHERE contenant_id IN (SELECT id
FROM contenant
WHERE contenance
BETWEEN 0.3 AND 1.0);
IV-D-6. Clause NOT IN▲
expression NOT IN (sous-requete)
- L’expression de droite est évaluée et vérifiée avec la liste de valeurs de gauche.
-
NOT IN vaut true :
- si aucune correspondance n’est trouvée et la liste ne contient pas NULL.
-
NOT IN vaut false :
- si l’expression de gauche correspond à un élément de la liste de droite.
-
NOT IN vaut NULL :
- si l’expression de gauche vaut NULL,
- si aucune valeur ne correspond et la liste contient NULL.
À l’inverse, la clause NOT IN permet dans la requête principale de sélectionner les lignes dont la colonne impliquée dans la condition ne correspond pas aux valeurs retournées par la sous-requête.
La requête suivante permet de sélectionner les bouteilles du stock dont la contenance n’est pas inférieure à 2 litres.
2.
3.
4.
5.
SELECT *
FROM stock
WHERE contenant_id NOT IN (SELECT id
FROM contenant
WHERE contenance < 2.0);
Il est à noter que les requêtes impliquant les clauses IN ou NOT IN peuvent généralement être réécrites sous la forme d’une jointure.
De plus, les optimiseurs SQL parviennent difficilement à optimiser une requête impliquant NOT IN. Il est préférable d’essayer de réécrire ces requêtes en utilisant une jointure.
Avec NOT IN, la gestion des valeurs NULL est à l’inverse de celle de la clause IN.
Si une correspondance est trouvée, NOT IN vaut false :
SELECT 1 NOT IN (1, 2, NULL) AS notin;
notin
-------
fSi aucune correspondance n’est trouvée, NOT IN vaut true :
SELECT 1 NOT IN (2, 4) AS notin;
notin
-------
tSi aucune correspondance n’est trouvée, mais que la liste de valeurs de droite contient au moins un NULL, NOT IN vaut NULL :
SELECT 1 NOT IN (2, 4, NULL) AS notin;
notin
--------
(null)Si l’expression de gauche vaut NULL, alors NOT IN vaut NULL également :
SELECT NULL IN (2, 4) AS notin;
notin
--------
(null)Les sous-requêtes retournant des valeurs NULL posent souvent des problèmes avec NOT IN. Il est préférable d’utiliser EXISTS ou NOT EXISTS pour ne pas avoir à se soucier des valeurs NULL.
IV-D-7. Clause ANY▲
expression operateur ANY (sous-requete)
- L’expression de gauche est comparée au résultat de la sous-requête avec l’opérateur donné.
-
La ligne de gauche est retournée :
- si le résultat d’au moins une comparaison est vrai.
-
La ligne de gauche n’est pas retournée :
- si aucun résultat de la comparaison n’est vrai,
- si l’expression de gauche vaut NULL,
- si la sous-requête ramène un ensemble vide.
La clause ANY, ou son synonyme SOME, permet de comparer l’expression de gauche à chaque ligne du résultat de la sous-requête en utilisant l’opérateur indiqué. Ainsi, la requête de l’exemple avec la clause IN aurait pu être écrite avec = ANY de la façon suivante :
2.
3.
4.
5.
6.
SELECT *
FROM stock
WHERE contenant_id = ANY (SELECT id
FROM contenant
WHERE contenance
BETWEEN 0.3 AND 1.0);
IV-D-8. Clause ALL▲
expression operateur ALL (sous-requete)
- L’expression de gauche est comparée à tous les résultats de la sous-requête avec l’opérateur donné.
-
La ligne de gauche est retournée :
- si tous les résultats des comparaisons sont vrais,
- si la sous-requête retourne un ensemble vide.
-
La ligne de gauche n’est pas retournée :
- si au moins une comparaison est fausse,
- si au moins une comparaison est NULL.
La clause ALL permet de comparer l’expression de gauche à chaque ligne du résultat de la sous-requête en utilisant l’opérateur de comparaison indiqué.
La ligne de la table de gauche sera retournée si toutes les comparaisons sont vraies ou si la sous-requête retourne un ensemble vide. En revanche, la ligne de la table de gauche sera exclue si au moins une comparaison est fausse ou si au moins une comparaison est NULL.
La requête d’exemple de la clause NOT IN aurait pu être écrite avec <> ALL de la façon suivante :
2.
3.
4.
5.
SELECT *
FROM stock
WHERE contenant_id <> ALL (SELECT id
FROM contenant
WHERE contenance < 2.0);
IV-D-9. Utiliser un ensemble▲
-
La sous-requête retourne :
- plusieurs lignes,
- sur plusieurs colonnes.
- Positionnée au niveau de la clause FROM.
- Nommée avec un alias de table.
La sous-requête peut être utilisée dans la clause FROM afin d’être utilisée comme une table dans la requête principale. La sous-requête devra obligatoirement être nommée avec un alias de table. Lorsqu’elles sont issues d’un calcul, les colonnes résultantes doivent également être nommées avec un alias de colonne afin d’éviter toute confusion ou tout comportement incohérent.
La requête suivante permet de déterminer le nombre moyen de bouteilles par années :
2.
3.
4.
SELECT AVG(nombre_total_annee) AS moyenne
FROM (SELECT annee, sum(nombre) AS nombre_total_annee
FROM stock
GROUP BY annee) stock_total_par_annee;
IV-D-10. Clause EXISTS▲
EXISTS (sous-requete)
- Intéressant avec une corrélation.
-
La clause EXISTS vérifie la présence ou l’absence de résultats :
- vrai si l’ensemble est non vide,
- faux si l’ensemble est vide.
EXISTS présente peu d’intérêt sans corrélation entre la sous-requête et la requête principale.
Le prédicat EXISTS est en général plus performant que IN. Lorsqu’une requête utilisant IN ne peut pas être réécrite sous la forme d’une jointure, il est recommandé d’utiliser EXISTS en lieu et place de IN. Et à l’inverse, une clause NOT IN sera réécrite avec NOT EXISTS.
La requête suivante permet d’identifier les vins pour lesquels il y a au moins une bouteille en stock :
2.
3.
4.
5.
SELECT *
FROM vin
WHERE EXISTS (SELECT *
FROM stock
WHERE vin_id = vin.id);
IV-E. Jointures▲
- Produit cartésien.
- Jointure interne.
- Jointures externes.
- Jointure ou sous-requête ?
Les jointures permettent d’écrire des requêtes qui impliquent plusieurs tables. Elles permettent de combiner les colonnes de plusieurs tables selon des critères particuliers, appelés conditions de jointures.
Les jointures permettent de tirer parti du modèle de données dans lequel les tables sont associées à l’aide de clés étrangères.
Bien qu’il soit possible de décrire une jointure interne sous la forme d’une requête SELECT portant sur deux tables dont la condition de jointure est décrite dans la clause WHERE, cette forme d’écriture n’est pas recommandée. En effet, les conditions de jointures se trouveront mélangées avec les clauses de filtrage, rendant ainsi la compréhension et la maintenance difficiles. Il arrive aussi que, noyé dans les autres conditions de filtrage, l’utilisateur oublie la configuration de jointure, ce qui aboutit à un produit cartésien, n’ayant rien à voir avec le résultat attendu, sans même parler de la lenteur de la requête.
Il est recommandé d’utiliser la syntaxe SQL:92 et d’exprimer les jointures à l’aide de la clause JOIN. D’ailleurs, cette syntaxe est la seule qui soit utilisable pour exprimer simplement et efficacement une jointure externe. Cette syntaxe facilite la compréhension de la requête, mais facilite également le travail de l’optimiseur SQL qui peut déduire beaucoup plus rapidement les jointures qu’en analysant la clause WHERE pour déterminer les conditions de jointure et les tables auxquelles elles s’appliquent le cas échéant.
IV-E-1. Produit cartésien▲
- Clause CROSS JOIN.
- Réalise toutes les combinaisons entre les lignes d’une table et les lignes d’une autre.
-
À éviter dans la mesure du possible :
- peu de cas d’utilisation,
- peu performant.
Le produit cartésien peut être exprimé avec la clause de jointure CROSS JOIN :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
-- préparation du jeu de données
CREATE TABLE t1 (i1 integer, v1 integer);
CREATE TABLE t2 (i2 integer, v2 integer);
INSERT INTO t1 (i1, v1) VALUES (0, 0), (1, 1);
INSERT INTO t2 (i2, v2) VALUES (2, 2), (3, 3);
-- requête CROSS JOIN
SELECT * FROM t1 CROSS JOIN t2;
i1 | v1 | i2 | v2
----+----+----+----
0 | 0 | 2 | 2
0 | 0 | 3 | 3
1 | 1 | 2 | 2
1 | 1 | 3 | 3
(4 rows)
Ou plus simplement, en listant les deux tables dans la clause FROM sans indiquer de condition de jointure :
SELECT * FROM t1, t2;
i1 | v1 | i2 | v2
----+----+----+----
0 | 0 | 2 | 2
0 | 0 | 3 | 3
1 | 1 | 2 | 2
1 | 1 | 3 | 3
(4 rows)Voici un autre exemple utilisant aussi un NOT EXISTS :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
CREATE TABLE sondes (id_sonde int, nom_sonde text);
CREATE TABLE releves_horaires (
id_sonde int,
heure_releve timestamptz check
(date_trunc('hour',heure_releve)=heure_releve),
valeur numeric);
INSERT INTO sondes VALUES (1,'sonde 1'),
(2, 'sonde 2'),
(3, 'sonde 3');
INSERT INTO releves_horaires VALUES
(1,'2013-01-01 12:00:00',10),
(1,'2013-01-01 13:00:00',11),
(1,'2013-01-01 14:00:00',12),
(2,'2013-01-01 12:00:00',10),
(2,'2013-01-01 13:00:00',12),
(2,'2013-01-01 14:00:00',12),
(3,'2013-01-01 12:00:00',10),
(3,'2013-01-01 14:00:00',10);
-- quels sont les relevés manquants entre 12h et 14h ?
SELECT id_sonde,
heures_releves
FROM sondes
CROSS JOIN generate_series('2013-01-01 12:00:00','2013-01-01 14:00:00',
interval '1 hour') series(heures_releves)
WHERE NOT EXISTS
(SELECT 1
FROM releves_horaires
WHERE releves_horaires.id_sonde=sondes.id_sonde
AND releves_horaires.heure_releve=series.heures_releves);
id_sonde | heures_releves
----------+------------------------
3 | 2013-01-01 13:00:00+01
(1 ligne)
IV-E-2. Jointure interne▲
-
Clause INNER JOIN :
- meilleure lisibilité,
- facilite le travail de l’optimiseur.
-
Joint deux tables entre elles :
- selon une condition de jointure.
|
|
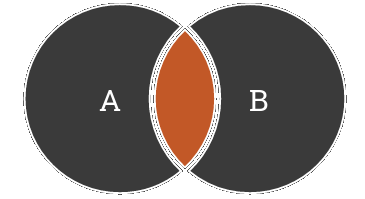
Une jointure interne est considérée comme un produit cartésien accompagné d’une clause de jointure pour ne conserver que les lignes qui répondent à la condition de jointure. Les SGBD réalisent néanmoins l’opération plus simplement.
La condition de jointure est généralement une égalité, ce qui permet d’associer entre elles les lignes de la table à gauche et de la table à droite dont les colonnes de condition de jointure sont égales.
La jointure interne est exprimée à travers la clause INNER JOIN ou plus simplement JOIN. En effet, si le type de jointure n’est pas spécifié, l’optimiseur considère la jointure comme étant une jointure interne.
IV-E-3. Syntaxe d’une jointure interne▲
- Condition de jointure par prédicats :
table1[INNER]JOINtable2ONprédicat[...] - Condition de jointure implicite par liste des colonnes impliquées :
table1[INNER]JOINtable2USING(colonne[, ...]) - Liste des colonnes implicites :
table1 NATURAL [INNER] JOIN table2
La clause ON permet d’écrire les conditions de jointures sous la forme de prédicats tels qu’on les retrouve dans une clause WHERE.
La clause USING permet de spécifier les colonnes sur lesquelles porte la jointure. Les tables jointes devront posséder toutes les colonnes sur lesquelles porte la jointure. La jointure sera réalisée en vérifiant l’égalité entre chaque colonne portant le même nom.
La clause NATURAL permet de réaliser la jointure entre deux tables en utilisant les colonnes qui portent le même nom sur les deux tables comme condition de jointure. La forme NATURAL JOIN est déconseillée, car elle entraîne des comportements inattendus.
La requête suivante permet de joindre la table appellation avec la table region pour déterminer l’origine d’une appellation :
2.
3.
4.
SELECT apl.libelle AS appellation, reg.libelle AS region
FROM appellation apl
JOIN region reg
ON (apl.region_id = reg.id);
IV-E-4. Jointure externe▲
-
Jointure externe à gauche :
- ramène le résultat de la jointure interne,
- ramène l’ensemble de la table de gauche qui ne peut être joint avec la table de droite,
- les attributs de la table de droite sont alors NULL.
|
|
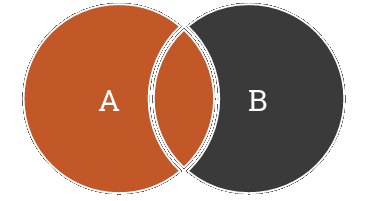
Il existe deux types de jointures externes : la jointure à gauche et la jointure à droite. Cela ne concerne que l’ordre de la jointure, le traitement en lui-même est identique.
IV-E-5. Jointure externe - 2▲
-
Jointure externe à droite
- ramène le résultat de la jointure interne,
- ramène l’ensemble de la table de droite qui ne peut être jointe avec la table de gauche,
- les attributs de la table de gauche sont alors NULL.
|
|
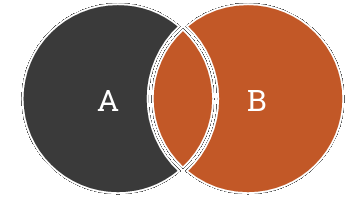
IV-E-6. Jointure externe complète▲
- Ramène le résultat de la jointure interne.
-
Ramène l’ensemble de la table de gauche qui ne peut être jointe avec la table de droite :
- les attributs de la table de droite sont alors NULL.
-
Ramène l’ensemble de la table de droite qui ne peut être joint avec la table de gauche :
- les attributs de la table de gauche sont alors NULL.
IV-E-7. Syntaxe d’une jointure externe à gauche▲
- Condition de jointure par prédicats :
table1LEFT[OUTER]JOINtable2ONprédicat[...] - Condition de jointure implicite par liste des colonnes impliquées :
table1LEFT[OUTER]JOINtable2USING(colonne[, ...]) - Liste des colonnes implicites :
table1NATURALLEFT[OUTER]JOINtable2
Il existe trois écritures différentes d’une jointure externe à gauche. La clause NATURAL permet de réaliser la jointure entre deux tables en utilisant les colonnes qui portent le même nom sur les deux tables comme condition de jointure.
Les voici en exemple :
-
Par prédicat :
Sélectionnez1.
2.
3.
4.SELECTarticle.art_titre, auteur.aut_nomFROMarticleLEFTJOINauteurON(article.aut_id=auteur.aut_id); - Par liste de colonnes :
2.
3.
4.
SELECT article.art_titre, auteur.aut_nom
FROM article
LEFT JOIN auteur
USING (aut_id);
IV-E-8. Syntaxe d’une jointure externe à droite▲
- Condition de jointure par prédicats :
table1RIGHT[OUTER]JOINtable2ONprédicat[...] - Condition de jointure implicite par liste des colonnes impliquées :
table1RIGHT[OUTER]JOINtable2USING(colonne[, ...]) - Liste des colonnes implicites :
table1NATURALRIGHT[OUTER]JOINtable2
Les jointures à droite sont moins fréquentes, mais elles restent utilisées.
IV-E-9. Syntaxe d’une jointure externe complète▲
- Condition de jointure par prédicats :
table1FULLOUTERJOINtable2ONprédicat[...] - Condition de jointure implicite par liste des colonnes impliquées :
table1FULLOUTERJOINtable2USING(colonne[, ...]) - Liste des colonnes implicites :
table1NATURALFULLOUTERJOINtable2
IV-E-10. Jointure ou sous-requête ?▲
-
Jointures :
- algorithmes très efficaces,
- ne gèrent pas tous les cas.
-
Sous-requêtes :
- parfois peu performantes,
- répondent à des besoins non couverts par les jointures.
Les sous-requêtes sont fréquemment utilisées, mais elles sont moins performantes que les jointures. Ces dernières permettent d’utiliser des optimisations très efficaces.
IV-F. Expressions CASE▲
- Équivalent à l’instruction switch en C ou Java.
- Emprunté au langage Ada.
- Retourne une valeur en fonction du résultat de tests.
CASE permet de tester différents cas. Il s’utilise de la façon suivante :
2.
3.
4.
5.
6.
SELECT
CASE WHEN col1=10 THEN 'dix'
WHEN col1>10 THEN 'supérieur à 10'
ELSE 'inférieur à 10'
END AS test
FROM t1;
IV-F-1. CASE simple▲
2.
3.
4.
5.
6.
CASE expression
WHEN valeur THEN expression
WHEN valeur THEN expression
(...)
ELSE expression
END
Il est possible de tester le résultat d’une expression avec CASE. Dans ce cas, chaque clause WHEN reprendra la valeur à laquelle on souhaite associer une expression particulière :
2.
3.
4.
5.
6.
7.
CASE nom_region
WHEN 'Afrique' THEN 1
WHEN 'Amérique' THEN 2
WHEN 'Asie' THEN 3
WHEN 'Europe' THEN 4
ELSE 0
END
IV-F-2. CASE sur expressions▲
2.
3.
4.
5.
CASE WHEN expression THEN expression
WHEN expression THEN expression
(...)
ELSE expression
END
Une expression peut être évaluée pour chaque clause WHEN. Dans ce cas, l’expression CASE retourne la première expression qui est vraie. Si une autre peut satisfaire la suivante, elle ne sera pas évaluée.
Par exemple :
2.
3.
4.
CASE WHEN salaire * prime < 1300 THEN salaire * prime
WHEN salaire * prime < 3000 THEN salaire
WHEN salaire * prime > 5000 THEN salaire * prime
END
IV-F-3. Spécificités de CASE▲
-
Comportement procédural :
- les expressions sont évaluées dans l’ordre d’apparition.
-
Transtypage :
- le type du retour de l’expression dépend du type de rang le plus élevé de toute l’expression.
-
Imbrication :
- des expressions CASE à l’intérieur d’autres expressions CASE.
-
Clause ELSE :
- recommandé.
Il est possible de placer plusieurs clauses WHEN. Elles sont évaluées dans leur ordre d’apparition.
2.
3.
4.
5.
6.
7.
8.
9.
CASE nom_region
WHEN 'Afrique' THEN 1
WHEN 'Amérique' THEN 2
/* l'expression suivante ne sera jamais évaluée */
WHEN 'Afrique' THEN 5
WHEN 'Asie' THEN 1
WHEN 'Europe' THEN 3
ELSE 0
END
Le type de données renvoyé par l’instruction CASE correspond au type indiqué par l’expression au niveau des THEN et du ELSE. Ce doit être le même type. Si les types de données ne correspondent pas, alors PostgreSQL retournera une erreur :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
SELECT *,
CASE nom_region
WHEN 'Afrique' THEN 1
WHEN 'Amérique' THEN 2
WHEN 'Asie' THEN 1
WHEN 'Europe' THEN 3
ELSE 'inconnu'
END
FROM regions;
ERROR: invalid input syntax for integer: "inconnu"
LIGNE 7 : ELSE 'inconnu'
La clause ELSE n’est pas obligatoire, mais fortement recommandée. En effet, si une expression CASE ne comporte pas de clause ELSE, alors la base de données ajoutera une clause ELSE NULL à l’expression.
Ainsi, l’expression suivante :
2.
3.
4.
CASE
WHEN salaire < 1000 THEN 'bas'
WHEN salaire > 3000 THEN 'haut'
END
Sera implicitement transformée de la façon suivante :
2.
3.
4.
5.
CASE
WHEN salaire < 1000 THEN 'bas'
WHEN salaire > 3000 THEN 'haut'
ELSE NULL
END
IV-G. Opérateurs ensemblistes▲
- UNION.
- INTERSECT.
- EXCEPT.
IV-G-1. Regroupement de deux ensembles▲
- Regroupement avec dédoublonnage :
requete_select1UNIONrequete_select2 - Regroupement sans dédoublonnage :
requete_select1 UNION ALL requete_select2
L’opérateur ensembliste UNION permet de regrouper deux ensembles dans un même résultat.
Le dédoublonnage peut être particulièrement coûteux, car il implique un tri des données.
Exemples :
La requête suivante assemble les résultats de deux requêtes pour produire le résultat :
2.
3.
4.
5.
6.
7.
SELECT *
FROM appellation
WHERE region_id = 1
UNION ALL
SELECT *
FROM appellation
WHERE region_id = 3;
IV-G-2. Intersection de deux ensembles▲
- Intersection de deux ensembles avec dédoublonnage :
requete_select1INTERSECTrequete_select2 - Intersection de deux ensembles sans dédoublonnage :
requete_select1 INTERSECT ALL requete_select2
L’opérateur ensembliste INTERSECT permet d’obtenir l’intersection du résultat de deux requêtes.
Le dédoublonnage peut être particulièrement coûteux, car il implique un tri des données.
Exemples :
L’exemple suivant n’a pas d’autre intérêt que de montrer le résultat de l’opérateur INTERSECT sur deux ensembles simples :
2.
3.
4.
5.
6.
7.
8.
9.
10.
SELECT *
FROM region
INTERSECT
SELECT *
FROM region
WHERE id = 3;
id | libelle
----+---------
3 | Alsace
IV-G-3. Différence entre deux ensembles▲
- Différence entre deux ensembles avec dédoublonnage :
requete_select1EXCEPTrequete_select2 - Différence entre deux ensembles sans dédoublonnage :
requete_select1 EXCEPT ALL requete_select2
L’opérateur ensembliste EXCEPT est l’équivalent de l’opérateur MINUS d’Oracle. Il permet d’obtenir la différence entre deux ensembles : toutes les lignes présentes dans les deux ensembles sont exclues du résultat.
Le dédoublonnage peut être particulièrement coûteux, car il implique un tri des données.
Exemples :
L’exemple suivant n’a pas d’autre intérêt que de montrer le résultat de l’opérateur EXCEPT sur deux ensembles simples. La première requête retourne l’ensemble des lignes de la table region, alors que la seconde requête retourne la ligne qui correspond au prédicat id = 3. Cette ligne est ensuite retirée du résultat, car elle est présente dans les deux ensembles de gauche et de droite :
SELECT *
FROM region
EXCEPT
SELECT *
FROM region
WHERE id = 3;
id | libelle
----+----------------------------
11 | Cotes du Rhone
12 | Provence produit a Cassis.
10 | Beaujolais
19 | Savoie
7 | Languedoc-Roussillon
4 | Loire
6 | Provence
16 | Est
8 | Bordeaux
14 | Lyonnais
15 | Auvergne
2 | Bourgogne
17 | Forez
9 | Vignoble du Sud-Ouest
18 | Charente
13 | Champagne
5 | Jura
1 | Provence et Corse
(18 rows)IV-H. Conclusion▲
- Possibilité d’écrire des requêtes complexes.
- C’est là où PostgreSQL est le plus performant.
Le standard SQL va bien plus loin que ce que les requêtes simplistes laissent penser. Utiliser des requêtes complexes permet de décharger l’application d’un travail important et le développeur de coder quelque chose qui existe déjà. Cela aide aussi la base de données, car il est plus simple d’optimiser une requête complexe qu’un grand nombre de requêtes simplistes.
IV-I. Travaux pratiques▲
IV-I-1. Énoncés▲
- Affichez, par pays, le nombre de fournisseurs.
Sortie attendue :
nom_pays | nombre
-------------------------------+--------
ARABIE SAOUDITE | 425
ARGENTINE | 416
(...)- Affichez, par continent (regions), le nombre de fournisseurs.
Sortie attendue :
nom_region | nombre
---------------------------+--------
Afrique | 1906
Moyen-Orient | 2113
Europe | 2094
Asie | 2002
Amérique | 1885- Affichez le nombre de commandes trié selon le nombre de lignes de commandes au sein de chaque commande.
Sortie attendue :
num | count
-----+-------
1 | 13733
2 | 27816
3 | 27750
4 | 27967
5 | 27687
6 | 27876
7 | 13895- Pour les 30 premières commandes (selon la date de commande), affichez le prix total de la commande, en appliquant la remise accordée sur chaque article commandé. La sortie sera triée de la commande la plus chère à la commande la moins chère.
Sortie attendue :
numero_commande | prix_total
-----------------+------------
3 | 259600.00
40 | 258959.00
6 | 249072.00
69 | 211330.00
70 | 202101.00
4 | 196132.00
(...)- Affichez, par année, le total des ventes. La date de commande fait foi. La sortie sera triée par année.
Sortie attendue :
annee | total_vente
-------+---------------
2005 | 3627568010.00
2006 | 3630975501.00
2007 | 3627112891.00
(...)- Pour toutes les commandes, calculez le temps moyen de livraison, depuis la date d’expédition. Le temps de livraison moyen sera exprimé en jours, arrondi à l’entier supérieur (fonction ceil()).
Sortie attendue :
temps_moyen_livraison
-----------------------
8 jour(s)- Pour les 30 commandes les plus récentes (selon la date de commande), calculez le temps moyen de livraison de chaque commande, depuis la date de commande. Le temps de livraison moyen sera exprimé en jours, arrondi à l’entier supérieur (fonction ceil()).
Sortie attendue :
temps_moyen_livraison
-----------------------
38 jour(s)- Déterminez le taux de retour des marchandises (l’état à R indiquant qu’une marchandise est retournée).
Sortie attendue :
taux_retour
-------------
24.29- Déterminez le mode d’expédition qui est le plus rapide, en moyenne.
Sortie attendue :
mode_expedition | delai
-----------------+--------------------
AIR | 7.4711070230494535- Un bogue applicatif est soupçonné, déterminez s’il existe des commandes dont la date de commande est postérieure à la date de livraison des articles.
Sortie attendue :
count
-------
2- Écrivez une requête qui corrige les données erronées en positionnant la date de commande à la date de livraison la plus ancienne des marchandises. Vérifiez qu’elle est correcte. Cette requête permet de corriger des calculs de statistiques sur les délais de livraison.
- Écrivez une requête qui calcule le délai total maximal de livraison de la totalité d’une commande donnée, depuis la date de la commande.
Sortie attendue pour la commande n°1 :
delai_max
-----------
102- Écrivez une requête pour déterminer les dix commandes dont le délai de livraison, entre la date de commande et la date de réception, est le plus important, pour l’année 2011 uniquement.
Sortie attendue :
numero_commande | delai
-----------------+-------
413510 | 146
123587 | 143
224453 | 143
(...)- Un autre bogue applicatif est détecté. Certaines commandes n’ont pas de lignes de commandes. Écrivez une requête pour les retrouver.
-[ RECORD 1 ]------------------------
numero_commande | 91495
client_id | 93528
etat_commande | P
prix_total |
date_commande | 2007-07-07
priorite_commande | 5-NOT SPECIFIED
vendeur | Vendeur 000006761
priorite_expedition | 0
commentaire | xxxxxxxxxxxxx- Écrivez une requête pour supprimer ces commandes. Vérifiez le travail avant de valider.
- Écrivez une requête pour déterminer les vingt pièces qui ont eu le plus gros volume de commande.
Sortie attendue :
nom | sum
--------------------------------------------+--------
lemon black goldenrod seashell plum | 461.00
brown lavender dim white indian | 408.00
burlywood white chiffon blanched lemon | 398.00
(...)- Affichez les fournisseurs des vingt pièces qui ont été les plus commandées sur l’année 2011.
Sortie attendue :
nom | piece_id
--------------+----------
Supplier4395 | 191875
Supplier4397 | 191875
Supplier6916 | 191875
Supplier9434 | 191875
Supplier4164 | 11662
Supplier6665 | 11662
(...)- Affichez le pays qui a connu, en nombre, le plus de commandes sur l’année 2011.
Sortie attendue :
nom_pays | count
-----------------+-------
ARABIE SAOUDITE | 1074- Affichez, pour les commandes passées en 2011, la liste des continents et la marge brute d’exploitation réalisée par continents, triées dans l’ordre décroissant.
Sortie attendue :
nom_region | benefice
---------------------------+---------------
Moyen-Orient | 2008595508.00
(...)- Affichez le nom, le numéro de téléphone et le pays des fournisseurs qui ont un commentaire contenant le mot-clé Complaints :
Sortie attendue :
nom_fournisseur | telephone | nom_pays
-----------------+-----------------+-------------------------------
Supplier3873 | 10-741-199-8614 | IRAN, RÉPUBLIQUE ISLAMIQUE D'
(...)- Déterminez le top 10 des fournisseurs ayant eu le plus long délai de livraison, entre la date de commande et la date de réception, pour l’année 2011 uniquement.
Sortie attendue :
fournisseur_id | nom_fournisseur | delai
----------------+-----------------+-------
9414 | Supplier9414 | 146
(...)IV-I-2. Solutions▲
- Affichez, par pays, le nombre de fournisseurs.
2.
3.
4.
5.
6.
SELECT p.nom_pays, count(*)
FROM fournisseurs f
JOIN contacts c ON f.contact_id = c.contact_id
JOIN pays p ON c.code_pays = p.code_pays
GROUP BY p.nom_pays
;
- Affichez, par continent, le nombre de fournisseurs.
2.
3.
4.
5.
6.
7.
SELECT r.nom_region, count(*)
FROM fournisseurs f
JOIN contacts c ON f.contact_id = c.contact_id
JOIN pays p ON c.code_pays = p.code_pays
JOIN regions r ON p.region_id = r.region_id
GROUP BY r.nom_region
;
- Affichez le nombre de commandes trié selon le nombre de lignes de commandes au sein de chaque commande.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
SELECT
nombre_lignes_commandes,
count(*) AS nombre_total_commandes
FROM (
/* cette sous-requête permet de compter le nombre de lignes de commande de
chaque commande, et remonte cette information à la requête principale */
SELECT count(numero_ligne_commande) AS nombre_lignes_commandes
FROM lignes_commandes
GROUP BY numero_commande
) comm_agg
/* la requête principale agrège et trie les données sur ce nombre de lignes
de commandes pour compter le nombre de commandes distinctes ayant le même
nombre de lignes de commandes */
GROUP BY nombre_lignes_commandes
ORDER BY nombre_lignes_commandes DESC
;
- Pour les 30 premières commandes (selon la date de commande), affichez le prix total de la commande, en appliquant la remise accordée sur chaque article commandé. La sortie sera triée de la commande la plus chère à la commande la moins chère.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
SELECT c.numero_commande, sum(quantite * prix_unitaire - remise) prix_total
FROM (
SELECT numero_commande, date_commande
FROM commandes
ORDER BY date_commande
LIMIT 30
) c
JOIN lignes_commandes lc ON c.numero_commande = lc.numero_commande
GROUP BY c.numero_commande
ORDER BY sum(quantite * prix_unitaire - remise) DESC
;
- Affichez, par année, le total des ventes. La date de commande fait foi. La sortie sera triée par année.
2.
3.
4.
5.
6.
7.
8.
9.
SELECT
extract ('year' FROM date_commande),
sum(quantite * prix - remise) AS prix_total
FROM commandes c
JOIN lignes_commandes lc ON c.numero_commande = lc.numero_commande
JOIN pieces p ON lc.piece_id = p.piece_id
GROUP BY extract ('year' FROM date_commande)
ORDER BY extract ('year' FROM date_commande)
;
- Pour toutes les commandes, calculez le temps moyen de livraison, depuis la date d’expédition. Le temps de livraison moyen sera exprimé en jours, arrondi à l’entier supérieur (fonction ceil()).
SELECT ceil(avg(date_reception - date_expedition))::text || ' jour(s)'
FROM lignes_commandes lc
;- Pour les 30 commandes les plus récentes (selon la date de commande), calculez le temps moyen de livraison de chaque commande, depuis la date de commande. Le temps de livraison moyen sera exprimé en jours, arrondi à l’entier supérieur (fonction ceil()).
2.
3.
4.
5.
6.
7.
8.
SELECT count(*), ceil(avg(date_reception - date_commande))::text || ' jour(s)'
FROM (
SELECT numero_commande, date_commande
FROM commandes
ORDER BY date_commande DESC
LIMIT 30
) c
JOIN lignes_commandes lc ON c.numero_commande = lc.numero_commande ;
Note : la colonne date_commande de la table commandes n’a pas de contrainte NOT NULL, il est donc possible d’avoir des commandes sans date de commande renseignée. Dans ce cas, ces commandes vont remonter par défaut en haut de la liste, puisque la clause ORDER BY renvoie les NULL après les valeurs les plus grandes, et que l’on inverse le tri. Pour éviter que ces commandes ne faussent les résultats, il faut donc les exclure de la sous-requête, de la façon suivante :
2.
3.
4.
5.
SELECT numero_commande, date_commande
FROM commandes
WHERE date_commande IS NOT NULL
ORDER BY date_commande DESC
LIMIT 30
- Déterminez le taux de retour des marchandises (l’état à R indiquant qu’une marchandise est retournée).
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
SELECT
round(
sum(
CASE etat_retour
WHEN 'R' THEN 1.0
ELSE 0.0
END
) / count(*)::numeric * 100,
2
)::text || ' %' AS taux_retour
FROM lignes_commandes
;
À partir de la version 9.4 de PostgreSQL, la clause FILTER des fonctions d’agrégation permet d’écrire une telle requête plus facilement :
2.
3.
4.
5.
6.
7.
SELECT
round(
count(*) FILTER (WHERE etat_retour = 'R') / count(*)::numeric * 100,
2
)::text || ' %' AS taux_retour
FROM lignes_commandes
;
- Déterminez le mode d’expédition qui est le plus rapide, en moyenne.
2.
3.
4.
5.
6.
SELECT mode_expedition, avg(date_reception - date_expedition)
FROM lignes_commandes lc
GROUP BY mode_expedition
ORDER BY avg(date_reception - date_expedition) ASC
LIMIT 1
;
- Un bug applicatif est soupçonné, déterminez s’il existe des commandes dont la date de commande est postérieure à la date d’expédition des articles.
2.
3.
4.
5.
SELECT count(*)
FROM commandes c
JOIN lignes_commandes lc ON c.numero_commande = lc.numero_commande
AND c.date_commande > lc.date_expedition
;
- Écrivez une requête qui corrige les données erronées en positionnant la date de commande à la date d’expédition la plus ancienne des marchandises. Vérifiez qu’elle est correcte. Cette requête permet de corriger des calculs de statistiques sur les délais de livraison.
Afin de se protéger d’une erreur de manipulation, on ouvre une transaction :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
BEGIN;
UPDATE commandes c_up
SET date_commande = (
SELECT min(date_expedition)
FROM commandes c
JOIN lignes_commandes lc ON lc.numero_commande = c.numero_commande
AND c.date_commande > lc.date_expedition
WHERE c.numero_commande = c_up.numero_commande
)
WHERE EXISTS (
SELECT 1
FROM commandes c2
JOIN lignes_commandes lc ON lc.numero_commande = c2.numero_commande
AND c2.date_commande > lc.date_expedition
WHERE c_up.numero_commande = c2.numero_commande
GROUP BY 1
)
;
La requête réalisée précédemment doit à présent retourner 0 :
2.
3.
4.
5.
SELECT count(*)
FROM commandes c
JOIN lignes_commandes lc ON c.numero_commande = lc.numero_commande
AND c.date_commande > lc.date_expedition
;
Si c’est le cas, on valide la transaction :
COMMIT;
Si ce n’est pas le cas, il doit y avoir une erreur dans la transaction, on l’annule :
ROLLBACK;
- Écrivez une requête qui calcule le délai total maximal de livraison de la totalité d’une commande donnée, depuis la date de la commande.
Par exemple pour la commande dont le numéro de commande est le 1 :
2.
3.
4.
5.
SELECT max(date_reception - date_commande)
FROM commandes c
JOIN lignes_commandes lc ON c.numero_commande = lc.numero_commande
WHERE c.numero_commande = 1
;
- Écrivez une requête pour déterminer les dix commandes dont le délai de livraison, entre la date de commande et la date de réception, est le plus important, pour l’année 2011 uniquement.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
SELECT
c.numero_commande,
max(date_reception - date_commande)
FROM commandes c
JOIN lignes_commandes lc ON c.numero_commande = lc.numero_commande
WHERE date_commande BETWEEN to_date('01/01/2011', 'DD/MM/YYYY')
AND to_date('31/12/2011', 'DD/MM/YYYY')
GROUP BY c.numero_commande
ORDER BY max(date_reception - date_commande) DESC
LIMIT 10
;
- Un autre bug applicatif est détecté. Certaines commandes n’ont pas de lignes de commandes. Écrivez une requête pour les retrouver.
Pour réaliser cette requête, il faut effectuer une jointure spéciale, nommée « Anti-jointure ». Il y a plusieurs façons d’écrire ce type de jointure. Les différentes méthodes sont données de la moins efficace à la plus efficace.
La version la moins performante est la suivante, avec NOT IN :
2.
3.
4.
5.
6.
7.
SELECT c.numero_commande
FROM commandes
WHERE numero_commande NOT IN (
SELECT numero_commande
FROM lignes_commandes
)
;
Il n’y a aucune corrélation entre la requête principale et la sous-requête. PostgreSQL doit donc vérifier pour chaque ligne de commandes que numero_commande n’est pas présent dans l’ensemble retourné par la sous-requête. Il est préférable d’éviter cette syntaxe.
Autre écriture possible, avec LEFT JOIN :
2.
3.
4.
5.
6.
7.
8.
SELECT c.numero_commande
FROM commandes c
LEFT JOIN lignes_commandes lc ON c.numero_commande = lc.numero_commande
/* c'est le filtre suivant qui permet de ne conserver que les lignes de la
table commandes qui n'ont PAS de correspondance avec la table
numero_commandes */
WHERE lc.numero_commande IS NULL
;
Enfin, l’écriture généralement préférée, tant pour la lisibilité que pour les performances, avec NOT EXISTS :
2.
3.
4.
5.
6.
7.
8.
SELECT c.numero_commande
FROM commandes c
WHERE NOT EXISTS (
SELECT 1
FROM lignes_commandes lc
WHERE lc.numero_commande = c.numero_commande
)
;
- Écrivez une requête pour supprimer ces commandes. Vérifiez le travail avant de valider.
Afin de se protéger d’une erreur de manipulation, on ouvre une transaction :
BEGIN;
La requête permettant de supprimer ces commandes est dérivée de la version NOT EXISTS de la requête ayant permis de trouver le problème :
2.
3.
4.
5.
6.
7.
8.
9.
10.
DELETE
FROM commandes c
WHERE NOT EXISTS (
SELECT 1
FROM lignes_commandes lc
WHERE lc.numero_commande = c.numero_commande
)
-- on peut renvoyer directement les numéros de commande qui ont été supprimés :
-- RETURNING numero_commande
;
Pour vérifier que le problème est corrigé :
2.
3.
4.
5.
6.
7.
8.
SELECT count(*
FROM commandes c
WHERE NOT EXISTS (
SELECT 1
FROM lignes_commandes lc
WHERE lc.numero_commande = c.numero_commande
)
;
Si la requête ci-dessus remonte 0, alors la transaction peut être validée :
COMMIT;
- Écrivez une requête pour déterminer les vingt pièces qui ont eu le plus gros volume de commande.
2.
3.
4.
5.
6.
7.
8.
SELECT p.nom,
sum(quantite)
FROM pieces p
JOIN lignes_commandes lc ON p.piece_id = lc.piece_id
GROUP BY p.nom
ORDER BY sum(quantite) DESC
LIMIT 20
;
- Affichez les fournisseurs des vingt pièces qui ont été les plus commandées sur l’année 2011.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
SELECT co.nom, max_p.piece_id, total_pieces
FROM (
/* cette sous-requête est sensiblement la même que celle de l'exercice
précédent, sauf que l'on remonte cette fois l'id de la pièce plutôt
que son nom pour pouvoir faire la jointure avec pieces_fournisseurs, et
que l'on ajoute une jointure avec commandes pour pouvoir filtrer sur
l'année 2011 */
SELECT
p.piece_id,
sum(quantite) AS total_pieces
FROM pieces p
JOIN lignes_commandes lc ON p.piece_id = lc.piece_id
JOIN commandes c ON c.numero_commande = lc.numero_commande
WHERE date_commande BETWEEN to_date('01/01/2011', 'DD/MM/YYYY')
AND to_date('31/12/2011', 'DD/MM/YYYY')
GROUP BY p.piece_id
ORDER BY sum(quantite) DESC
LIMIT 20
) max_p
/* il faut passer par la table de liens pieces_fournisseurs pour récupérer
la liste des fournisseurs d'une piece */
JOIN pieces_fournisseurs pf ON max_p.piece_id = pf.piece_id
JOIN fournisseurs f ON f.fournisseur_id = pf.fournisseur_id
-- la jointure avec la table contact permet d'afficher le nom du fournisseur
JOIN contacts co ON f.contact_id = co.contact_id
;
- Affichez le pays qui a connu, en nombre, le plus de commandes sur l’année 2011.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
SELECT nom_pays,
count(c.numero_commande)
FROM commandes c
JOIN clients cl ON (c.client_id = cl.client_id)
JOIN contacts co ON (cl.contact_id = co.contact_id)
JOIN pays p ON (co.code_pays = p.code_pays)
WHERE date_commande BETWEEN to_date('01/01/2011', 'DD/MM/YYYY')
AND to_date('31/12/2011', 'DD/MM/YYYY')
GROUP BY p.nom_pays
ORDER BY count(c.numero_commande) DESC
LIMIT 1;
- Affichez, pour les commandes passées en 2011, la liste des régions et la marge brute d’exploitation réalisée par régions, triées dans l’ordre décroissant.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
SELECT
nom_region,
round(sum(quantite * prix - remise) - sum(quantite * cout_piece), 2)
AS marge_brute
FROM
commandes c
JOIN lignes_commandes lc ON lc.numero_commande = c.numero_commande
/* il faut passer par la table de liens pieces_fournisseurs pour récupérer
la liste des fournisseurs d'une pièce - attention, la condition de
jointure entre lignes_commandes et pieces_fournisseurs porte sur deux
colonnes ! */
JOIN pieces_fournisseurs pf ON lc.piece_id = pf.piece_id
AND lc.fournisseur_id = pf.fournisseur_id
JOIN pieces p ON p.piece_id = pf.piece_id
JOIN fournisseurs f ON f.fournisseur_id = pf.fournisseur_id
JOIN clients cl ON c.client_id = cl.client_id
JOIN contacts co ON cl.contact_id = co.contact_id
JOIN pays pa ON co.code_pays = pa.code_pays
JOIN regions r ON r.region_id = pa.region_id
WHERE date_commande BETWEEN to_date('01/01/2011', 'DD/MM/YYYY')
AND to_date('31/12/2011', 'DD/MM/YYYY')
GROUP BY nom_region
ORDER BY sum(quantite * prix - remise) - sum(quantite * cout_piece) DESC
;
- Affichez le nom, le numéro de téléphone et le pays des fournisseurs qui ont un commentaire contenant le mot-clé Complaints :
2.
3.
4.
5.
6.
7.
8.
9.
10.
SELECT
nom,
telephone,
nom_pays
FROM
fournisseurs f
JOIN contacts c ON f.contact_id = c.contact_id
JOIN pays p ON c.code_pays = p.code_pays
WHERE f.commentaire LIKE '%Complaints%'
;
- Déterminez le top 10 des fournisseurs ayant eu le plus long délai de livraison, entre la date de commande et la date de réception, pour l’année 2011 uniquement.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
SELECT
f.fournisseur_id,
co.nom,
max(date_reception - date_commande)
FROM
lignes_commandes lc
JOIN commandes c ON c.numero_commande = lc.numero_commande
JOIN pieces_fournisseurs pf ON lc.piece_id = pf.piece_id
AND lc.fournisseur_id = pf.fournisseur_id
JOIN fournisseurs f ON pf.fournisseur_id = f.fournisseur_id
JOIN contacts co ON f.contact_id = co.contact_id
WHERE date_commande BETWEEN to_date('01/01/2011', 'DD/MM/YYYY')
AND to_date('31/12/2011', 'DD/MM/YYYY')
GROUP BY f.fournisseur_id, co.nom
ORDER BY max(date_reception - date_commande) DESC
LIMIT 10
;
